 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecond-Order Information Matters: Revisiting Machine Unlearning for Large Language Models
Mar 13, 2024



With the rapid development of Large Language Models (LLMs), we have witnessed intense competition among the major LLM products like ChatGPT, LLaMa, and Gemini. However, various issues (e.g. privacy leakage and copyright violation) of the training corpus still remain underexplored. For example, the Times sued OpenAI and Microsoft for infringing on its copyrights by using millions of its articles for training. From the perspective of LLM practitioners, handling such unintended privacy violations can be challenging. Previous work addressed the ``unlearning" problem of LLMs using gradient information, while they mostly introduced significant overheads like data preprocessing or lacked robustness. In this paper, contrasting with the methods based on first-order information, we revisit the unlearning problem via the perspective of second-order information (Hessian). Our unlearning algorithms, which are inspired by classic Newton update, are not only data-agnostic/model-agnostic but also proven to be robust in terms of utility preservation or privacy guarantee. Through a comprehensive evaluation with four NLP datasets as well as a case study on real-world datasets, our methods consistently show superiority over the first-order methods.
DocGraphLM: Documental Graph Language Model for Information Extraction
Jan 05, 2024



Advances in Visually Rich Document Understanding (VrDU) have enabled information extraction and question answering over documents with complex layouts. Two tropes of architectures have emerged -- transformer-based models inspired by LLMs, and Graph Neural Networks. In this paper, we introduce DocGraphLM, a novel framework that combines pre-trained language models with graph semantics. To achieve this, we propose 1) a joint encoder architecture to represent documents, and 2) a novel link prediction approach to reconstruct document graphs. DocGraphLM predicts both directions and distances between nodes using a convergent joint loss function that prioritizes neighborhood restoration and downweighs distant node detection. Our experiments on three SotA datasets show consistent improvement on IE and QA tasks with the adoption of graph features. Moreover, we report that adopting the graph features accelerates convergence in the learning process during training, despite being solely constructed through link prediction.
FLTrojan: Privacy Leakage Attacks against Federated Language Models Through Selective Weight Tampering
Oct 24, 2023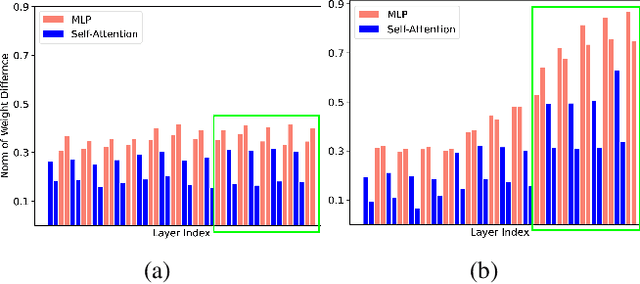

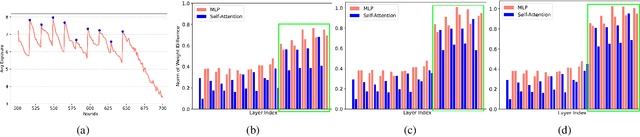

Federated learning (FL) is becoming a key component in many technology-based applications including language modeling -- where individual FL participants often have privacy-sensitive text data in their local datasets. However, realizing the extent of privacy leakage in federated language models is not straightforward and the existing attacks only intend to extract data regardless of how sensitive or naive it is. To fill this gap, in this paper, we introduce two novel findings with regard to leaking privacy-sensitive user data from federated language models. Firstly, we make a key observation that model snapshots from the intermediate rounds in FL can cause greater privacy leakage than the final trained model. Secondly, we identify that privacy leakage can be aggravated by tampering with a model's selective weights that are specifically responsible for memorizing the sensitive training data. We show how a malicious client can leak the privacy-sensitive data of some other user in FL even without any cooperation from the server. Our best-performing method improves the membership inference recall by 29% and achieves up to 70% private data reconstruction, evidently outperforming existing attacks with stronger assumptions of adversary capabilities.
Feature Selection for Multivariate Time Series via Network Pruning
Feb 11, 2021


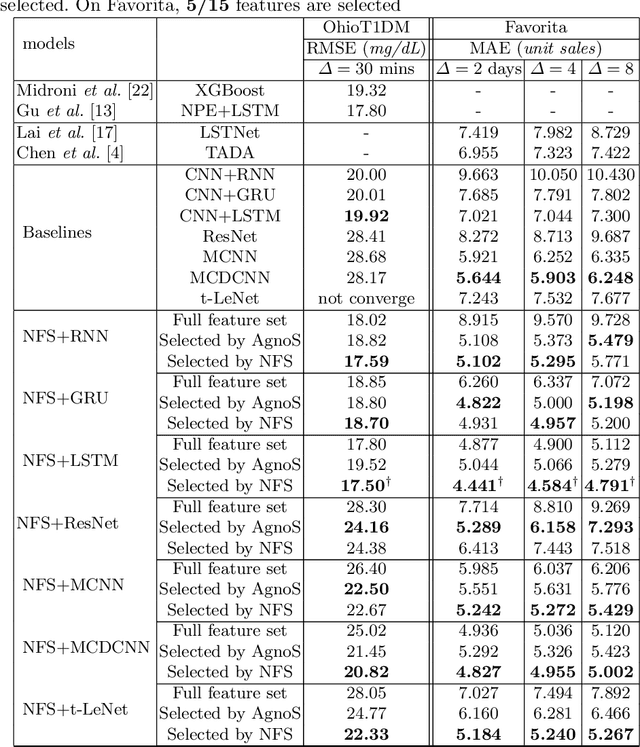
In recent years, there has been an ever increasing amount of multivariate time series (MTS) data in various domains, typically generated by a large family of sensors such as wearable devices. This has led to the development of novel learning methods on MTS data, with deep learning models dominating the most recent advancements. Prior literature has primarily focused on designing new network architectures for modeling temporal dependencies within MTS. However, a less studied challenge is associated with high dimensionality of MTS data. In this paper, we propose a novel neural component, namely Neural Feature Se-lector (NFS), as an end-2-end solution for feature selection in MTS data. Specifically, NFS is based on decomposed convolution design and includes two modules: firstly each feature stream within MTS is processed by a temporal CNN independently; then an aggregating CNN combines the processed streams to produce input for other downstream networks. We evaluated the proposed NFS model on four real-world MTS datasets and found that it achieves comparable results with state-of-the-art methods while providing the benefit of feature selection. Our paper also highlights the robustness and effectiveness of feature selection with NFS compared to using recent autoencoder-based methods.
Jointly Attentive Spatial-Temporal Pooling Networks for Video-based Person Re-Identification
Sep 29, 2017
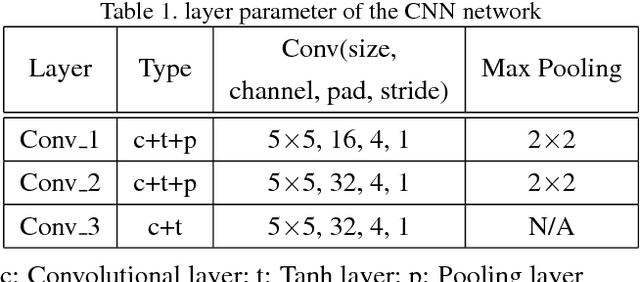
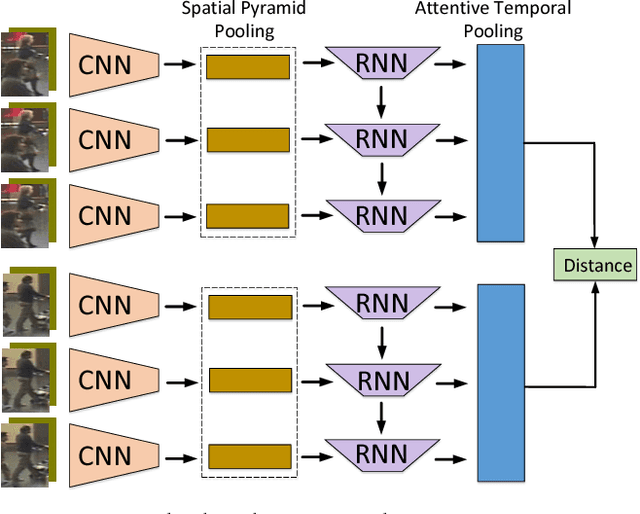
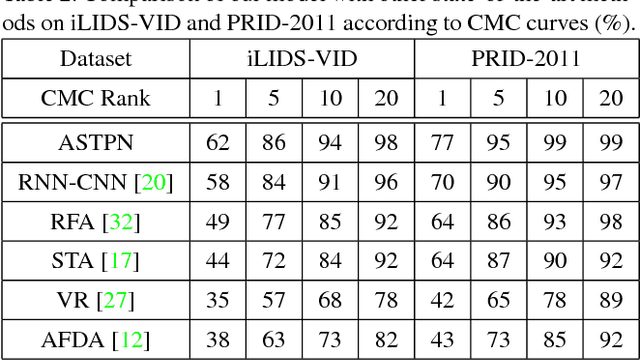
Person Re-Identification (person re-id) is a crucial task as its applications in visual surveillance and human-computer interaction. In this work, we present a novel joint Spatial and Temporal Attention Pooling Network (ASTPN) for video-based person re-identification, which enables the feature extractor to be aware of the current input video sequences, in a way that interdependency from the matching items can directly influence the computation of each other's representation. Specifically, the spatial pooling layer is able to select regions from each frame, while the attention temporal pooling performed can select informative frames over the sequence, both pooling guided by the information from distance matching. Experiments are conduced on the iLIDS-VID, PRID-2011 and MARS datasets and the results demonstrate that this approach outperforms existing state-of-art methods. We also analyze how the joint pooling in both dimensions can boost the person re-id performance more effectively than using either of them separately.