 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple and Provable Scaling Law for the Test-Time Compute of Large Language Models
Paper and Code
Nov 29, 2024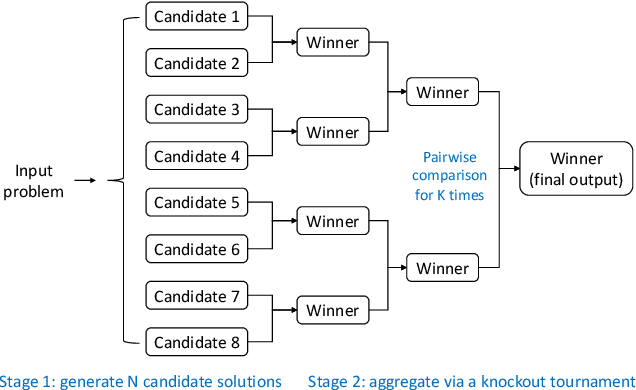



We propose a general two-stage algorithm that enjoys a provable scaling law for the test-time compute of large language models (LLMs). Given an input problem, the proposed algorithm first generates $N$ candidate solutions, and then chooses the best one via a multiple-round knockout tournament where each pair of candidates are compared for $K$ times and only the winners move on to the next round. In a minimalistic implementation, both stages can be executed with a black-box LLM alone and nothing else (e.g., no external verifier or reward model), and a total of $N \times (K + 1)$ highly parallelizable LLM calls are needed for solving an input problem. Assuming that a generated candidate solution is correct with probability $p_{\text{gen}} > 0$ and a comparison between a pair of correct and incorrect solutions identifies the right winner with probability $p_{\text{comp}} > 0.5$ (i.e., better than a random guess), we prove theoretically that the failure probability of the proposed algorithm decays to zero exponentially with respect to $N$ and $K$: $$\mathbb{P}(\text{final output is incorrect}) \le (1 - p_{\text{gen}})^N + \lceil \log_2 N \rceil e^{-2 K (p_{\text{comp}} - 0.5)^2}.$$ Our empirical results with the challenging MMLU-Pro benchmark validate the technical assumptions, as well as the efficacy of the proposed algorithm and the gains from scaling up its test-time compute.