 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeed-forward Gaussian Registration for Head Avatar Creation and Editing
Mar 16, 2026We present MATCH (Multi-view Avatars from Topologically Corresponding Heads), a multi-view Gaussian registration method for high-quality head avatar creation and editing. State-of-the-art multi-view head avatar methods require time-consuming head tracking followed by expensive avatar optimization, often resulting in a total creation time of more than one day. MATCH, in contrast, directly predicts Gaussian splat textures in correspondence from calibrated multi-view images in just 0.5 seconds per frame, without requiring data preprocessing. The learned intra-subject correspondence across frames enables fast creation of personalized head avatars, while correspondence across subjects supports applications such as expression transfer, optimization-free tracking, semantic editing, and identity interpolation. We establish these correspondences end-to-end using a transformer-based model that predicts Gaussian splat textures in the fixed UV layout of a template mesh. To achieve this, we introduce a novel registration-guided attention block, where each UV-map token attends exclusively to image tokens depicting its corresponding mesh region. This design improves efficiency and performance compared to dense cross-view attention. MATCH outperforms existing methods in novel-view synthesis, geometry registration, and head avatar generation, while making avatar creation 10 times faster than the closest competing baseline. The code and model weights are available on the project website.
TeGA: Texture Space Gaussian Avatars for High-Resolution Dynamic Head Modeling
May 08, 2025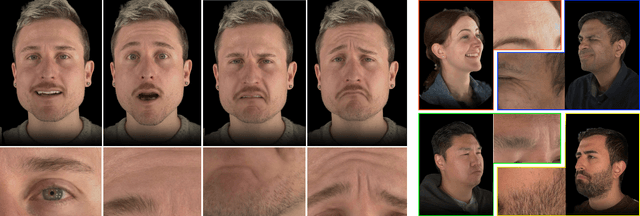
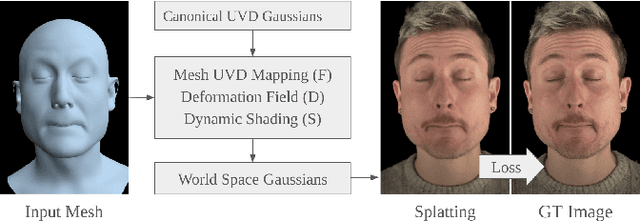


Sparse volumetric reconstruction and rendering via 3D Gaussian splatting have recently enabled animatable 3D head avatars that are rendered under arbitrary viewpoints with impressive photorealism. Today, such photoreal avatars are seen as a key component in emerging applications in telepresence, extended reality, and entertainment. Building a photoreal avatar requires estimating the complex non-rigid motion of different facial components as seen in input video images; due to inaccurate motion estimation, animatable models typically present a loss of fidelity and detail when compared to their non-animatable counterparts, built from an individual facial expression. Also, recent state-of-the-art models are often affected by memory limitations that reduce the number of 3D Gaussians used for modeling, leading to lower detail and quality. To address these problems, we present a new high-detail 3D head avatar model that improves upon the state of the art, largely increasing the number of 3D Gaussians and modeling quality for rendering at 4K resolution. Our high-quality model is reconstructed from multiview input video and builds on top of a mesh-based 3D morphable model, which provides a coarse deformation layer for the head. Photoreal appearance is modelled by 3D Gaussians embedded within the continuous UVD tangent space of this mesh, allowing for more effective densification where most needed. Additionally, these Gaussians are warped by a novel UVD deformation field to capture subtle, localized motion. Our key contribution is the novel deformable Gaussian encoding and overall fitting procedure that allows our head model to preserve appearance detail, while capturing facial motion and other transient high-frequency features such as skin wrinkling.
GIGA: Generalizable Sparse Image-driven Gaussian Avatars
Apr 08, 2025Driving a high-quality and photorealistic full-body human avatar, from only a few RGB cameras, is a challenging problem that has become increasingly relevant with emerging virtual reality technologies. To democratize such technology, a promising solution may be a generalizable method that takes sparse multi-view images of an unseen person and then generates photoreal free-view renderings of such identity. However, the current state of the art is not scalable to very large datasets and, thus, lacks in diversity and photorealism. To address this problem, we propose a novel, generalizable full-body model for rendering photoreal humans in free viewpoint, as driven by sparse multi-view video. For the first time in literature, our model can scale up training to thousands of subjects while maintaining high photorealism. At the core, we introduce a MultiHeadUNet architecture, which takes sparse multi-view images in texture space as input and predicts Gaussian primitives represented as 2D texels on top of a human body mesh. Importantly, we represent sparse-view image information, body shape, and the Gaussian parameters in 2D so that we can design a deep and scalable architecture entirely based on 2D convolutions and attention mechanisms. At test time, our method synthesizes an articulated 3D Gaussian-based avatar from as few as four input views and a tracked body template for unseen identities. Our method excels over prior works by a significant margin in terms of cross-subject generalization capability as well as photorealism.
Synthetic Prior for Few-Shot Drivable Head Avatar Inversion
Jan 12, 2025We present SynShot, a novel method for the few-shot inversion of a drivable head avatar based on a synthetic prior. We tackle two major challenges. First, training a controllable 3D generative network requires a large number of diverse sequences, for which pairs of images and high-quality tracked meshes are not always available. Second, state-of-the-art monocular avatar models struggle to generalize to new views and expressions, lacking a strong prior and often overfitting to a specific viewpoint distribution. Inspired by machine learning models trained solely on synthetic data, we propose a method that learns a prior model from a large dataset of synthetic heads with diverse identities, expressions, and viewpoints. With few input images, SynShot fine-tunes the pretrained synthetic prior to bridge the domain gap, modeling a photorealistic head avatar that generalizes to novel expressions and viewpoints. We model the head avatar using 3D Gaussian splatting and a convolutional encoder-decoder that outputs Gaussian parameters in UV texture space. To account for the different modeling complexities over parts of the head (e.g., skin vs hair), we embed the prior with explicit control for upsampling the number of per-part primitives. Compared to state-of-the-art monocular methods that require thousands of real training images, SynShot significantly improves novel view and expression synthesis.
Cafca: High-quality Novel View Synthesis of Expressive Faces from Casual Few-shot Captures
Oct 01, 2024
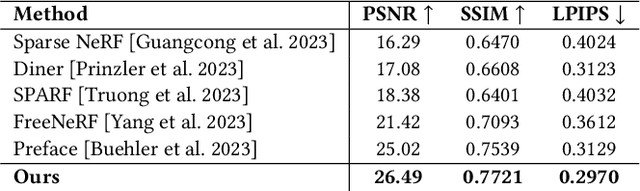

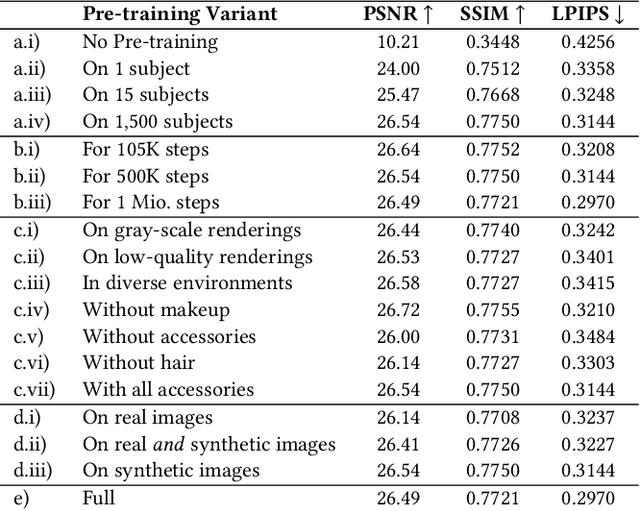
Volumetric modeling and neural radiance field representations have revolutionized 3D face capture and photorealistic novel view synthesis. However, these methods often require hundreds of multi-view input images and are thus inapplicable to cases with less than a handful of inputs. We present a novel volumetric prior on human faces that allows for high-fidelity expressive face modeling from as few as three input views captured in the wild. Our key insight is that an implicit prior trained on synthetic data alone can generalize to extremely challenging real-world identities and expressions and render novel views with fine idiosyncratic details like wrinkles and eyelashes. We leverage a 3D Morphable Face Model to synthesize a large training set, rendering each identity with different expressions, hair, clothing, and other assets. We then train a conditional Neural Radiance Field prior on this synthetic dataset and, at inference time, fine-tune the model on a very sparse set of real images of a single subject. On average, the fine-tuning requires only three inputs to cross the synthetic-to-real domain gap. The resulting personalized 3D model reconstructs strong idiosyncratic facial expressions and outperforms the state-of-the-art in high-quality novel view synthesis of faces from sparse inputs in terms of perceptual and photo-metric quality.
Infinite 3D Landmarks: Improving Continuous 2D Facial Landmark Detection
May 30, 2024In this paper, we examine 3 important issues in the practical use of state-of-the-art facial landmark detectors and show how a combination of specific architectural modifications can directly improve their accuracy and temporal stability. First, many facial landmark detectors require face normalization as a preprocessing step, which is accomplished by a separately-trained neural network that crops and resizes the face in the input image. There is no guarantee that this pre-trained network performs the optimal face normalization for landmark detection. We instead analyze the use of a spatial transformer network that is trained alongside the landmark detector in an unsupervised manner, and jointly learn optimal face normalization and landmark detection. Second, we show that modifying the output head of the landmark predictor to infer landmarks in a canonical 3D space can further improve accuracy. To convert the predicted 3D landmarks into screen-space, we additionally predict the camera intrinsics and head pose from the input image. As a side benefit, this allows to predict the 3D face shape from a given image only using 2D landmarks as supervision, which is useful in determining landmark visibility among other things. Finally, when training a landmark detector on multiple datasets at the same time, annotation inconsistencies across datasets forces the network to produce a suboptimal average. We propose to add a semantic correction network to address this issue. This additional lightweight neural network is trained alongside the landmark detector, without requiring any additional supervision. While the insights of this paper can be applied to most common landmark detectors, we specifically target a recently-proposed continuous 2D landmark detector to demonstrate how each of our additions leads to meaningful improvements over the state-of-the-art on standard benchmarks.
MagicMirror: Fast and High-Quality Avatar Generation with a Constrained Search Space
Apr 01, 2024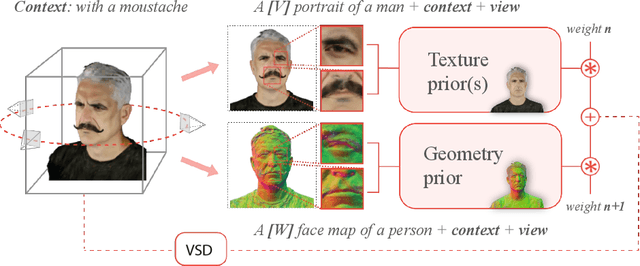



We introduce a novel framework for 3D human avatar generation and personalization, leveraging text prompts to enhance user engagement and customization. Central to our approach are key innovations aimed at overcoming the challenges in photo-realistic avatar synthesis. Firstly, we utilize a conditional Neural Radiance Fields (NeRF) model, trained on a large-scale unannotated multi-view dataset, to create a versatile initial solution space that accelerates and diversifies avatar generation. Secondly, we develop a geometric prior, leveraging the capabilities of Text-to-Image Diffusion Models, to ensure superior view invariance and enable direct optimization of avatar geometry. These foundational ideas are complemented by our optimization pipeline built on Variational Score Distillation (VSD), which mitigates texture loss and over-saturation issues. As supported by our extensive experiments, these strategies collectively enable the creation of custom avatars with unparalleled visual quality and better adherence to input text prompts. You can find more results and videos in our website: https://syntec-research.github.io/MagicMirror
An Implicit Physical Face Model Driven by Expression and Style
Jan 27, 2024



3D facial animation is often produced by manipulating facial deformation models (or rigs), that are traditionally parameterized by expression controls. A key component that is usually overlooked is expression 'style', as in, how a particular expression is performed. Although it is common to define a semantic basis of expressions that characters can perform, most characters perform each expression in their own style. To date, style is usually entangled with the expression, and it is not possible to transfer the style of one character to another when considering facial animation. We present a new face model, based on a data-driven implicit neural physics model, that can be driven by both expression and style separately. At the core, we present a framework for learning implicit physics-based actuations for multiple subjects simultaneously, trained on a few arbitrary performance capture sequences from a small set of identities. Once trained, our method allows generalized physics-based facial animation for any of the trained identities, extending to unseen performances. Furthermore, it grants control over the animation style, enabling style transfer from one character to another or blending styles of different characters. Lastly, as a physics-based model, it is capable of synthesizing physical effects, such as collision handling, setting our method apart from conventional approaches.
A Perceptual Shape Loss for Monocular 3D Face Reconstruction
Oct 30, 2023Monocular 3D face reconstruction is a wide-spread topic, and existing approaches tackle the problem either through fast neural network inference or offline iterative reconstruction of face geometry. In either case carefully-designed energy functions are minimized, commonly including loss terms like a photometric loss, a landmark reprojection loss, and others. In this work we propose a new loss function for monocular face capture, inspired by how humans would perceive the quality of a 3D face reconstruction given a particular image. It is widely known that shading provides a strong indicator for 3D shape in the human visual system. As such, our new 'perceptual' shape loss aims to judge the quality of a 3D face estimate using only shading cues. Our loss is implemented as a discriminator-style neural network that takes an input face image and a shaded render of the geometry estimate, and then predicts a score that perceptually evaluates how well the shaded render matches the given image. This 'critic' network operates on the RGB image and geometry render alone, without requiring an estimate of the albedo or illumination in the scene. Furthermore, our loss operates entirely in image space and is thus agnostic to mesh topology. We show how our new perceptual shape loss can be combined with traditional energy terms for monocular 3D face optimization and deep neural network regression, improving upon current state-of-the-art results.
* Accepted to PG 2023. Project page: https://studios.disneyresearch.com/2023/10/09/a-perceptual-shape-loss-for-monocular-3d-face-reconstruction/ Video: https://www.youtube.com/watch?v=RYdyoIZEuUI