 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative Circumnavigation for Multi-Quadrotor Systems via Onboard Sensing
Jun 26, 2025A cooperative circumnavigation framework is proposed for multi-quadrotor systems to enclose and track a moving target without reliance on external localization systems. The distinct relationships between quadrotor-quadrotor and quadrotor-target interactions are evaluated using a heterogeneous perception strategy and corresponding state estimation algorithms. A modified Kalman filter is developed to fuse visual-inertial odometry with range measurements to enhance the accuracy of inter-quadrotor relative localization. An event-triggered distributed Kalman filter is designed to achieve robust target state estimation under visual occlusion by incorporating neighbor measurements and estimated inter-quadrotor relative positions. Using the estimation results, a cooperative circumnavigation controller is constructed, leveraging an oscillator-based autonomous formation flight strategy. We conduct extensive indoor and outdoor experiments to validate the efficiency of the proposed circumnavigation framework in occluded environments. Furthermore, a quadrotor failure experiment highlights the inherent fault tolerance property of the proposed framework, underscoring its potential for deployment in search-and-rescue operations.
Flow-Inspired Lightweight Multi-Robot Real-Time Scheduling Planner
Sep 11, 2024Collision avoidance and trajectory planning are crucial in multi-robot systems, particularly in environments with numerous obstacles. Although extensive research has been conducted in this field, the challenge of rapid traversal through such environments has not been fully addressed. This paper addresses this problem by proposing a novel real-time scheduling scheme designed to optimize the passage of multi-robot systems through complex, obstacle-rich maps. Inspired from network flow optimization, our scheme decomposes the environment into a network structure, enabling the efficient allocation of robots to paths based on real-time congestion data. The proposed scheduling planner operates on top of existing collision avoidance algorithms, focusing on minimizing traversal time by balancing robot detours and waiting times. Our simulation results demonstrate the efficiency of the proposed scheme. Additionally, we validated its effectiveness through real world flight tests using ten quadrotors. This work contributes a lightweight, effective scheduling planner capable of meeting the real-time demands of multi-robot systems in obstacle-rich environments.
Heuristic Predictive Control for Multi-Robot Flocking in Congested Environments
Jul 09, 2024



Multi-robot flocking possesses extraordinary advantages over a single-robot system in diverse domains, but it is challenging to ensure safe and optimal performance in congested environments. Hence, this paper is focused on the investigation of distributed optimal flocking control for multiple robots in crowded environments. A heuristic predictive control solution is proposed based on a Gibbs Random Field (GRF), in which bio-inspired potential functions are used to characterize robot-robot and robot-environment interactions. The optimal solution is obtained by maximizing a posteriori joint distribution of the GRF in a certain future time instant. A gradient-based heuristic solution is developed, which could significantly speed up the computation of the optimal control. Mathematical analysis is also conducted to show the validity of the heuristic solution. Multiple collision risk levels are designed to improve the collision avoidance performance of robots in dynamic environments. The proposed heuristic predictive control is evaluated comprehensively from multiple perspectives based on different metrics in a challenging simulation environment. The competence of the proposed algorithm is validated via the comparison with the non-heuristic predictive control and two existing popular flocking control methods. Real-life experiments are also performed using four quadrotor UAVs to further demonstrate the efficiency of the proposed design.
DACOOP-A: Decentralized Adaptive Cooperative Pursuit via Attention
Oct 28, 2023Integrating rule-based policies into reinforcement learning promises to improve data efficiency and generalization in cooperative pursuit problems. However, most implementations do not properly distinguish the influence of neighboring robots in observation embedding or inter-robot interaction rules, leading to information loss and inefficient cooperation. This paper proposes a cooperative pursuit algorithm named Decentralized Adaptive COOperative Pursuit via Attention (DACOOP-A) by empowering reinforcement learning with artificial potential field and attention mechanisms. An attention-based framework is developed to emphasize important neighbors by concurrently integrating the learned attention scores into observation embedding and inter-robot interaction rules. A KL divergence regularization is introduced to alleviate the resultant learning stability issue. Improvements in data efficiency and generalization are demonstrated through numerical simulations. Extensive quantitative analysis and ablation studies are performed to illustrate the advantages of the proposed modules. Real-world experiments are performed to justify the feasibility of deploying DACOOP-A in physical systems.
Formation Control for Moving Target Enclosing via Relative Localization
Jul 28, 2023
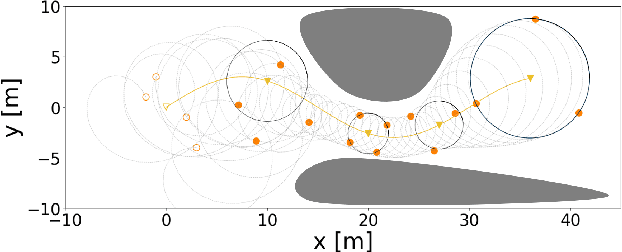
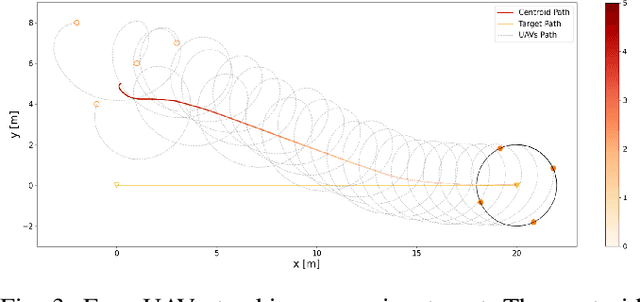
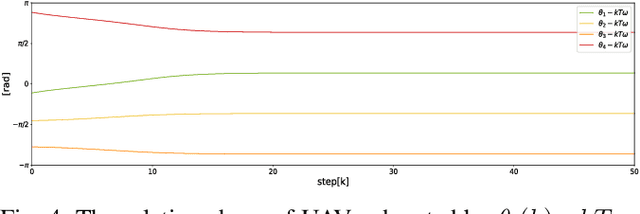
In this paper, we investigate the problem of controlling multiple unmanned aerial vehicles (UAVs) to enclose a moving target in a distributed fashion based on a relative distance and self-displacement measurements. A relative localization technique is developed based on the recursive least square estimation (RLSE) technique with a forgetting factor to estimates both the ``UAV-UAV'' and ``UAV-target'' relative positions. The formation enclosing motion is planned using a coupled oscillator model, which generates desired motion for UAVs to distribute evenly on a circle. The coupled-oscillator-based motion can also facilitate the exponential convergence of relative localization due to its persistent excitation nature. Based on the generation strategy of desired formation pattern and relative localization estimates, a cooperative formation tracking control scheme is proposed, which enables the formation geometric center to asymptotically converge to the moving target. The asymptotic convergence performance is analyzed theoretically for both the relative localization technique and the formation control algorithm. Numerical simulations are provided to show the efficiency of the proposed algorithm. Experiments with three quadrotors tracking one target are conducted to evaluate the proposed target enclosing method in real platforms.
Policy Transfer via Enhanced Action Space
Dec 07, 2022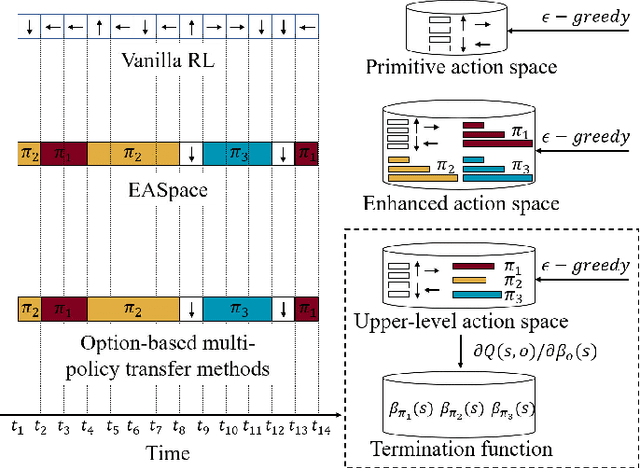
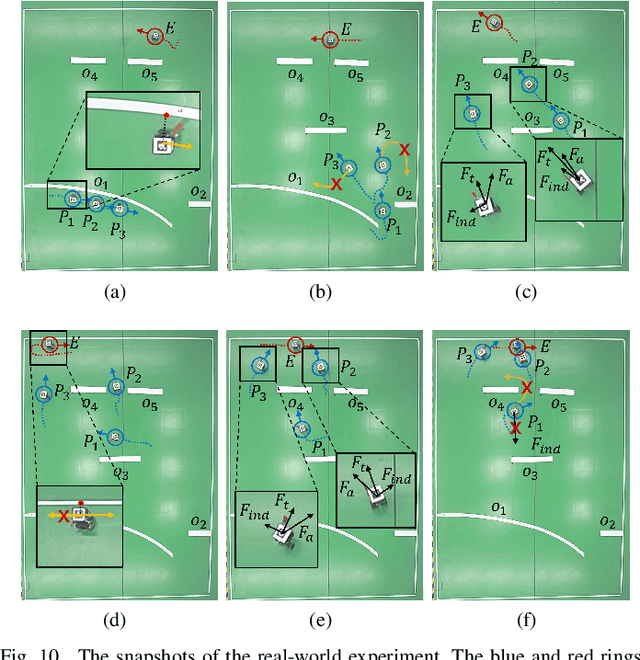
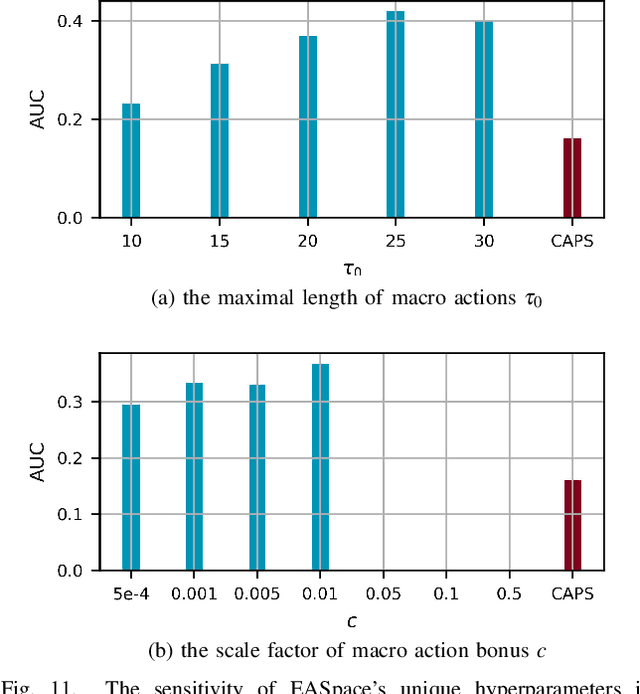
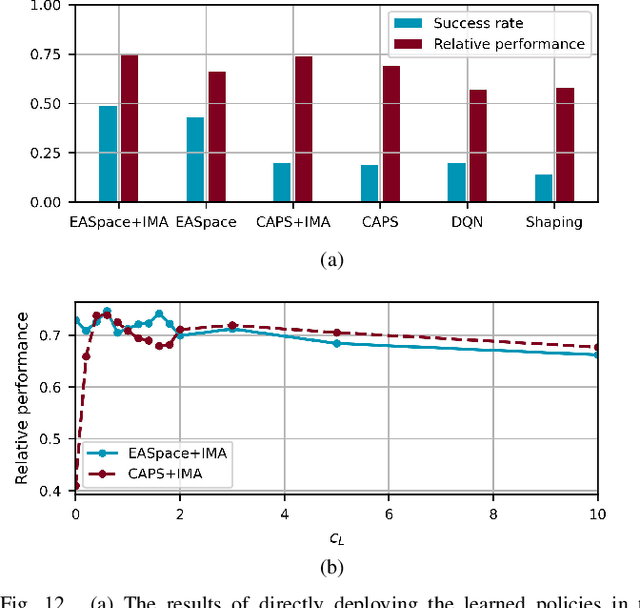
Though transfer learning is promising to increase the learning efficiency, the existing methods are still subject to the challenges from long-horizon tasks, especially when expert policies are sub-optimal and partially useful. Hence, a novel algorithm named EASpace (Enhanced Action Space) is proposed in this paper to transfer the knowledge of multiple sub-optimal expert policies. EASpace formulates each expert policy into multiple macro actions with different execution time period, then integrates all macro actions into the primitive action space directly. Through this formulation, the proposed EASpace could learn when to execute which expert policy and how long it lasts. An intra-macro-action learning rule is proposed by adjusting the temporal difference target of macro actions to improve the data efficiency and alleviate the non-stationarity issue in multi-agent settings. Furthermore, an additional reward proportional to the execution time of macro actions is introduced to encourage the environment exploration via macro actions, which is significant to learn a long-horizon task. Theoretical analysis is presented to show the convergence of the proposed algorithm. The efficiency of the proposed algorithm is illustrated by a grid-based game and a multi-agent pursuit problem. The proposed algorithm is also implemented to real physical systems to justify its effectiveness.
Multi-robot Cooperative Pursuit via Potential Field-Enhanced Reinforcement Learning
Mar 09, 2022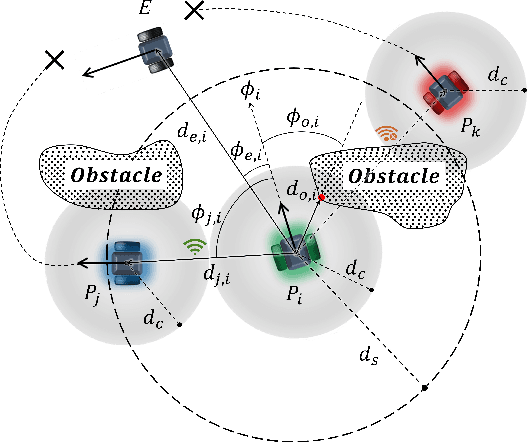


It is of great challenge, though promising, to coordinate collective robots for hunting an evader in a decentralized manner purely in light of local observations. In this paper, this challenge is addressed by a novel hybrid cooperative pursuit algorithm that combines reinforcement learning with the artificial potential field method. In the proposed algorithm, decentralized deep reinforcement learning is employed to learn cooperative pursuit policies that are adaptive to dynamic environments. The artificial potential field method is integrated into the learning process as predefined rules to improve the data efficiency and generalization ability. It is shown by numerical simulations that the proposed hybrid design outperforms the pursuit policies either learned from vanilla reinforcement learning or designed by the potential field method. Furthermore, experiments are conducted by transferring the learned pursuit policies into real-world mobile robots. Experimental results demonstrate the feasibility and potential of the proposed algorithm in learning multiple cooperative pursuit strategies.
Euler angles based loss function for camera relocalization with Deep learning
Feb 24, 2018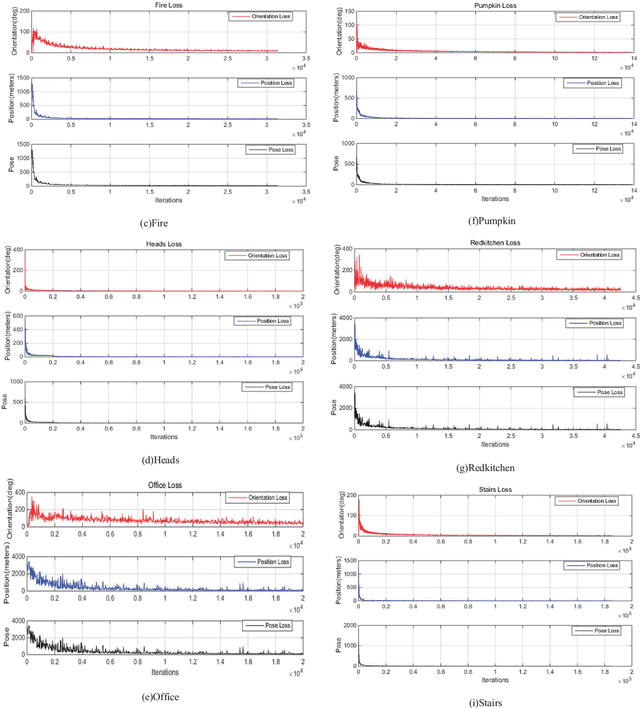
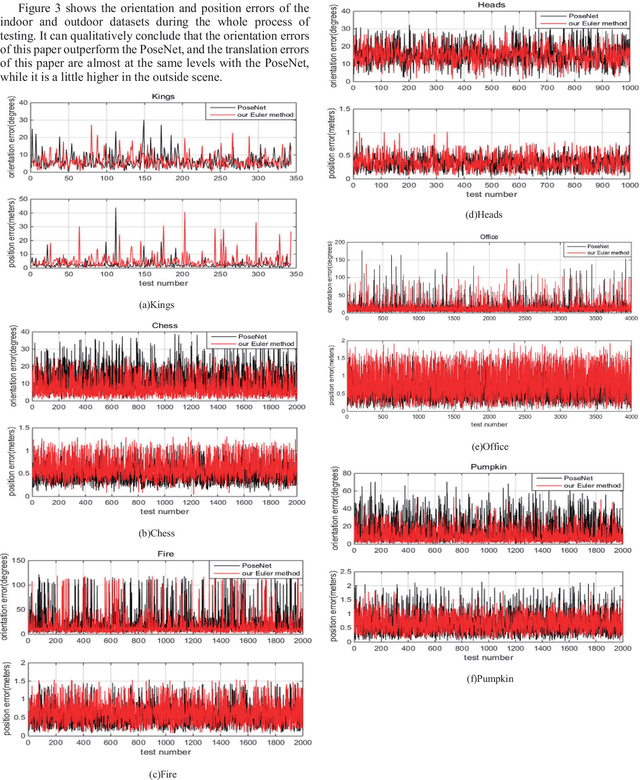
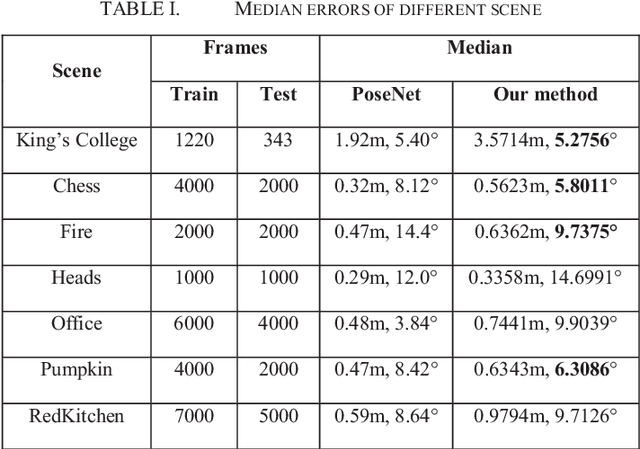
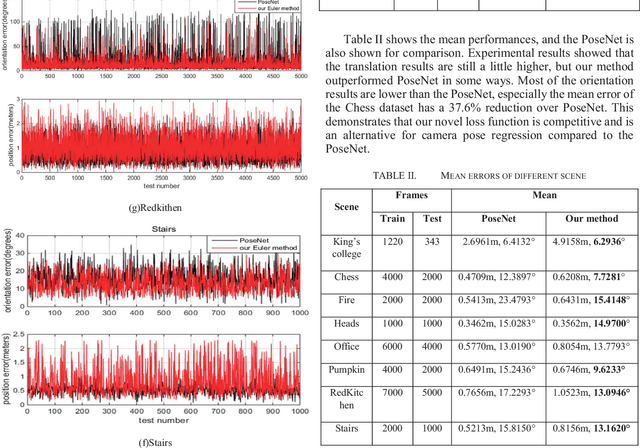
Deep learning has been applied to camera relocalization, in particular, PoseNet and its extended work are the convolutional neural networks which regress the camera pose from a single image. However there are many problems, one of them is expensive parameter selection. In this paper, we directly explore the three Euler angles as the orientation representation in the camera pose regressor. There is no need to select the parameter, which is not tolerant in the previous works. Experimental results on the 7 Scenes datasets and the King's College dataset demonstrate that it has competitive performances.