 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Efficient Flocking Control based on Gibbs Random Fields
Feb 05, 2025



Flocking control is essential for multi-robot systems in diverse applications, yet achieving efficient flocking in congested environments poses challenges regarding computation burdens, performance optimality, and motion safety. This paper addresses these challenges through a multi-agent reinforcement learning (MARL) framework built on Gibbs Random Fields (GRFs). With GRFs, a multi-robot system is represented by a set of random variables conforming to a joint probability distribution, thus offering a fresh perspective on flocking reward design. A decentralized training and execution mechanism, which enhances the scalability of MARL concerning robot quantity, is realized using a GRF-based credit assignment method. An action attention module is introduced to implicitly anticipate the motion intentions of neighboring robots, consequently mitigating potential non-stationarity issues in MARL. The proposed framework enables learning an efficient distributed control policy for multi-robot systems in challenging environments with success rate around $99\%$, as demonstrated through thorough comparisons with state-of-the-art solutions in simulations and experiments. Ablation studies are also performed to validate the efficiency of different framework modules.
HOLA-Drone: Hypergraphic Open-ended Learning for Zero-Shot Multi-Drone Cooperative Pursuit
Sep 13, 2024Zero-shot coordination (ZSC) is a significant challenge in multi-agent collaboration, aiming to develop agents that can coordinate with unseen partners they have not encountered before. Recent cutting-edge ZSC methods have primarily focused on two-player video games such as OverCooked!2 and Hanabi. In this paper, we extend the scope of ZSC research to the multi-drone cooperative pursuit scenario, exploring how to construct a drone agent capable of coordinating with multiple unseen partners to capture multiple evaders. We propose a novel Hypergraphic Open-ended Learning Algorithm (HOLA-Drone) that continuously adapts the learning objective based on our hypergraphic-form game modeling, aiming to improve cooperative abilities with multiple unknown drone teammates. To empirically verify the effectiveness of HOLA-Drone, we build two different unseen drone teammate pools to evaluate their performance in coordination with various unseen partners. The experimental results demonstrate that HOLA-Drone outperforms the baseline methods in coordination with unseen drone teammates. Furthermore, real-world experiments validate the feasibility of HOLA-Drone in physical systems. Videos can be found on the project homepage~\url{https://sites.google.com/view/hola-drone}.
GRF-based Predictive Flocking Control with Dynamic Pattern Formation
Mar 13, 2024



It is promising but challenging to design flocking control for a robot swarm to autonomously follow changing patterns or shapes in a optimal distributed manner. The optimal flocking control with dynamic pattern formation is, therefore, investigated in this paper. A predictive flocking control algorithm is proposed based on a Gibbs random field (GRF), where bio-inspired potential energies are used to charaterize ``robot-robot'' and ``robot-environment'' interactions. Specialized performance-related energies, e.g., motion smoothness, are introduced in the proposed design to improve the flocking behaviors. The optimal control is obtained by maximizing a posterior distribution of a GRF. A region-based shape control is accomplished for pattern formation in light of a mean shift technique. The proposed algorithm is evaluated via the comparison with two state-of-the-art flocking control methods in an environment with obstacles. Both numerical simulations and real-world experiments are conducted to demonstrate the efficiency of the proposed design.
DACOOP-A: Decentralized Adaptive Cooperative Pursuit via Attention
Oct 28, 2023Integrating rule-based policies into reinforcement learning promises to improve data efficiency and generalization in cooperative pursuit problems. However, most implementations do not properly distinguish the influence of neighboring robots in observation embedding or inter-robot interaction rules, leading to information loss and inefficient cooperation. This paper proposes a cooperative pursuit algorithm named Decentralized Adaptive COOperative Pursuit via Attention (DACOOP-A) by empowering reinforcement learning with artificial potential field and attention mechanisms. An attention-based framework is developed to emphasize important neighbors by concurrently integrating the learned attention scores into observation embedding and inter-robot interaction rules. A KL divergence regularization is introduced to alleviate the resultant learning stability issue. Improvements in data efficiency and generalization are demonstrated through numerical simulations. Extensive quantitative analysis and ablation studies are performed to illustrate the advantages of the proposed modules. Real-world experiments are performed to justify the feasibility of deploying DACOOP-A in physical systems.
Reinforced Potential Field for Multi-Robot Motion Planning in Cluttered Environments
Jul 26, 2023
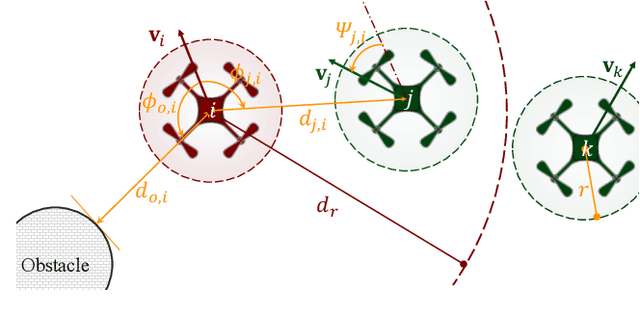
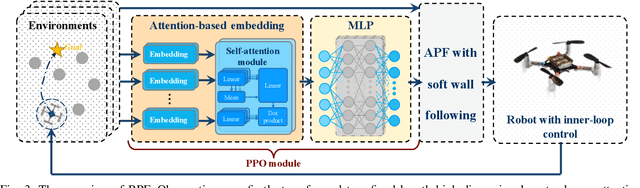
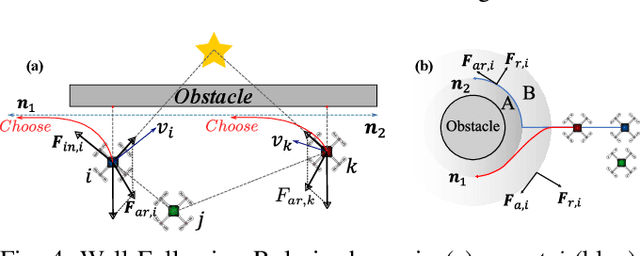
Motion planning is challenging for multiple robots in cluttered environments without communication, especially in view of real-time efficiency, motion safety, distributed computation, and trajectory optimality, etc. In this paper, a reinforced potential field method is developed for distributed multi-robot motion planning, which is a synthesized design of reinforcement learning and artificial potential fields. An observation embedding with a self-attention mechanism is presented to model the robot-robot and robot-environment interactions. A soft wall-following rule is developed to improve the trajectory smoothness. Our method belongs to reactive planning, but environment properties are implicitly encoded. The total amount of robots in our method can be scaled up to any number. The performance improvement over a vanilla APF and RL method has been demonstrated via numerical simulations. Experiments are also performed using quadrotors to further illustrate the competence of our method.
Multi-Robot Motion Planning: A Learning-Based Artificial Potential Field Solution
Jun 13, 2023Motion planning is a crucial aspect of robot autonomy as it involves identifying a feasible motion path to a destination while taking into consideration various constraints, such as input, safety, and performance constraints, without violating either system or environment boundaries. This becomes particularly challenging when multiple robots run without communication, which compromises their real-time efficiency, safety, and performance. In this paper, we present a learning-based potential field algorithm that incorporates deep reinforcement learning into an artificial potential field (APF). Specifically, we introduce an observation embedding mechanism that pre-processes dynamic information about the environment and develop a soft wall-following rule to improve trajectory smoothness. Our method, while belonging to reactive planning, implicitly encodes environmental properties. Additionally, our approach can scale up to any number of robots and has demonstrated superior performance compared to APF and RL through numerical simulations. Finally, experiments are conducted to highlight the effectiveness of our proposed method.