 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkywork-R1V3 Technical Report
Jul 09, 2025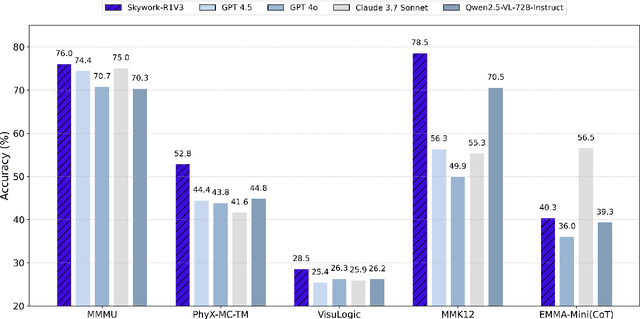
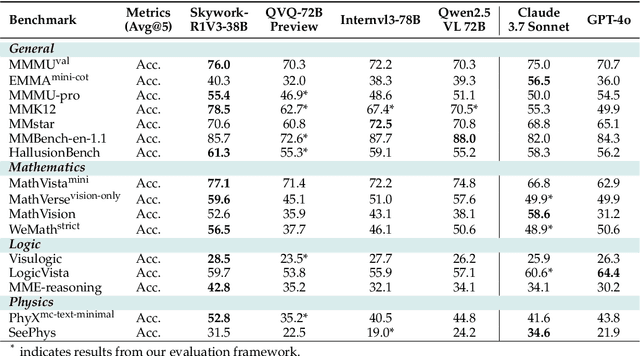
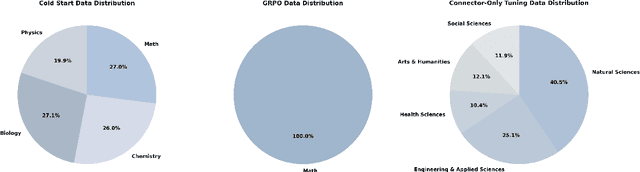

We introduce Skywork-R1V3, an advanced, open-source vision-language model (VLM) that pioneers a new approach to visual reasoning. Its key innovation lies in effectively transferring reasoning skills from text-only Large Language Models (LLMs) to visual tasks. The strong performance of Skywork-R1V3 primarily stems from our elaborate post-training RL framework, which effectively activates and enhances the model's reasoning ability, without the need for additional continue pre-training. Through this framework, we further uncover the fundamental role of the connector module in achieving robust cross-modal alignment for multimodal reasoning models. In addition, we introduce a unique indicator of reasoning capability, the entropy of critical reasoning tokens, which has proven highly effective for checkpoint selection during RL training. Skywork-R1V3 achieves state-of-the-art results on MMMU, significantly improving from 64.3% to 76.0%. This performance matches entry-level human capabilities. Remarkably, our RL-powered post-training approach enables even the 38B parameter model to rival top closed-source VLMs. The implementation successfully transfers mathematical reasoning to other subject-related reasoning tasks. We also include an analysis of curriculum learning and reinforcement finetuning strategies, along with a broader discussion on multimodal reasoning. Skywork-R1V3 represents a significant leap in multimodal reasoning, showcasing RL as a powerful engine for advancing open-source VLM capabilities.
Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning
Apr 23, 2025We present Skywork R1V2, a next-generation multimodal reasoning model and a major leap forward from its predecessor, Skywork R1V. At its core, R1V2 introduces a hybrid reinforcement learning paradigm that harmonizes reward-model guidance with rule-based strategies, thereby addressing the long-standing challenge of balancing sophisticated reasoning capabilities with broad generalization. To further enhance training efficiency, we propose the Selective Sample Buffer (SSB) mechanism, which effectively counters the ``Vanishing Advantages'' dilemma inherent in Group Relative Policy Optimization (GRPO) by prioritizing high-value samples throughout the optimization process. Notably, we observe that excessive reinforcement signals can induce visual hallucinations--a phenomenon we systematically monitor and mitigate through calibrated reward thresholds throughout the training process. Empirical results affirm the exceptional capability of R1V2, with benchmark-leading performances such as 62.6 on OlympiadBench, 79.0 on AIME2024, 63.6 on LiveCodeBench, and 74.0 on MMMU. These results underscore R1V2's superiority over existing open-source models and demonstrate significant progress in closing the performance gap with premier proprietary systems, including Gemini 2.5 and OpenAI o4-mini. The Skywork R1V2 model weights have been publicly released to promote openness and reproducibility https://huggingface.co/Skywork/Skywork-R1V2-38B.
Skywork-MoE: A Deep Dive into Training Techniques for Mixture-of-Experts Language Models
Jun 03, 2024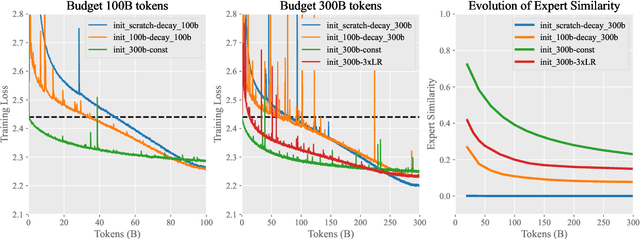
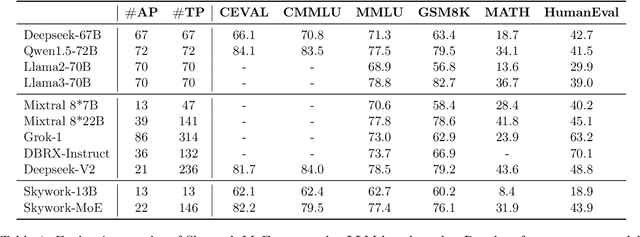
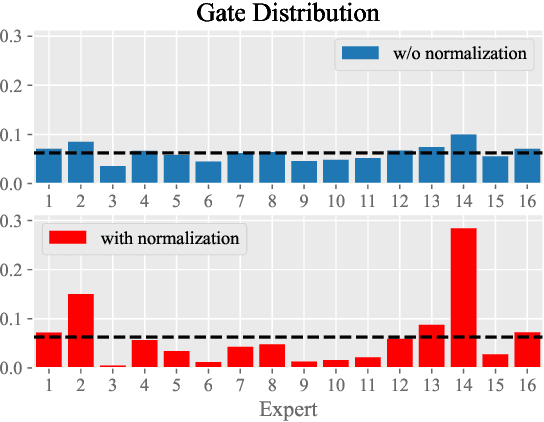
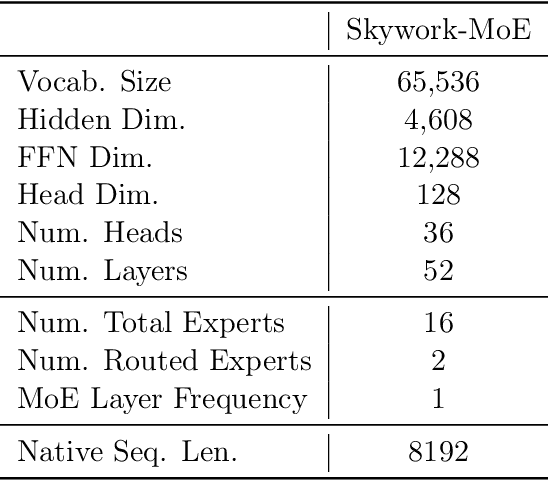
In this technical report, we introduce the training methodologies implemented in the development of Skywork-MoE, a high-performance mixture-of-experts (MoE) large language model (LLM) with 146 billion parameters and 16 experts. It is initialized from the pre-existing dense checkpoints of our Skywork-13B model. We explore the comparative effectiveness of upcycling versus training from scratch initializations. Our findings suggest that the choice between these two approaches should consider both the performance of the existing dense checkpoints and the MoE training budget. We highlight two innovative techniques: gating logit normalization, which improves expert diversification, and adaptive auxiliary loss coefficients, allowing for layer-specific adjustment of auxiliary loss coefficients. Our experimental results validate the effectiveness of these methods. Leveraging these techniques and insights, we trained our upcycled Skywork-MoE on a condensed subset of our SkyPile corpus. The evaluation results demonstrate that our model delivers strong performance across a wide range of benchmarks.
Coop: Memory is not a Commodity
Nov 01, 2023


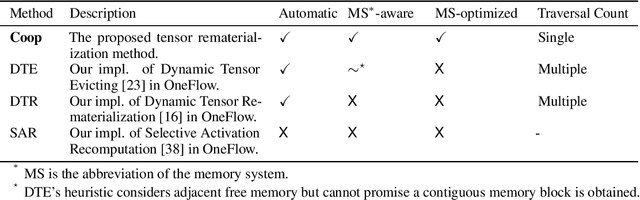
Tensor rematerialization allows the training of deep neural networks (DNNs) under limited memory budgets by checkpointing the models and recomputing the evicted tensors as needed. However, the existing tensor rematerialization techniques overlook the memory system in deep learning frameworks and implicitly assume that free memory blocks at different addresses are identical. Under this flawed assumption, discontiguous tensors are evicted, among which some are not used to allocate the new tensor. This leads to severe memory fragmentation and increases the cost of potential rematerializations. To address this issue, we propose to evict tensors within a sliding window to ensure all evictions are contiguous and are immediately used. Furthermore, we proposed cheap tensor partitioning and recomputable in-place to further reduce the rematerialization cost by optimizing the tensor allocation. We named our method Coop as it is a co-optimization of tensor allocation and tensor rematerialization. We evaluated Coop on eight representative DNNs. The experimental results demonstrate that Coop achieves up to $2\times$ memory saving and hugely reduces compute overhead, search latency, and memory fragmentation compared to the state-of-the-art baselines.
Skywork: A More Open Bilingual Foundation Model
Oct 30, 2023
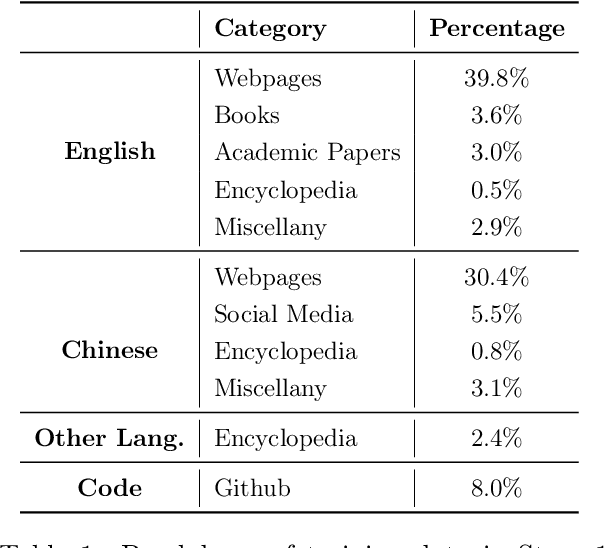
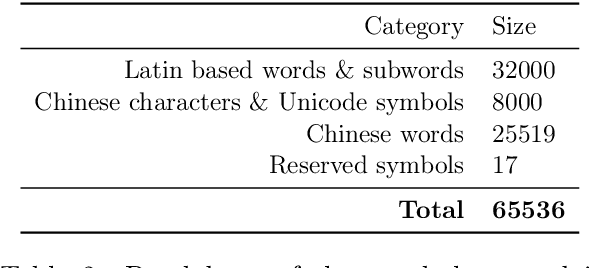
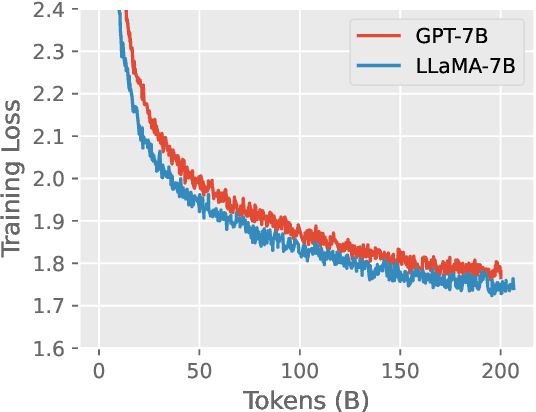
In this technical report, we present Skywork-13B, a family of large language models (LLMs) trained on a corpus of over 3.2 trillion tokens drawn from both English and Chinese texts. This bilingual foundation model is the most extensively trained and openly published LLMs of comparable size to date. We introduce a two-stage training methodology using a segmented corpus, targeting general purpose training and then domain-specific enhancement training, respectively. We show that our model not only excels on popular benchmarks, but also achieves \emph{state of the art} performance in Chinese language modeling on diverse domains. Furthermore, we propose a novel leakage detection method, demonstrating that test data contamination is a pressing issue warranting further investigation by the LLM community. To spur future research, we release Skywork-13B along with checkpoints obtained during intermediate stages of the training process. We are also releasing part of our SkyPile corpus, a collection of over 150 billion tokens of web text, which is the largest high quality open Chinese pre-training corpus to date. We hope Skywork-13B and our open corpus will serve as a valuable open-source resource to democratize access to high-quality LLMs.
daBNN: A Super Fast Inference Framework for Binary Neural Networks on ARM devices
Aug 16, 2019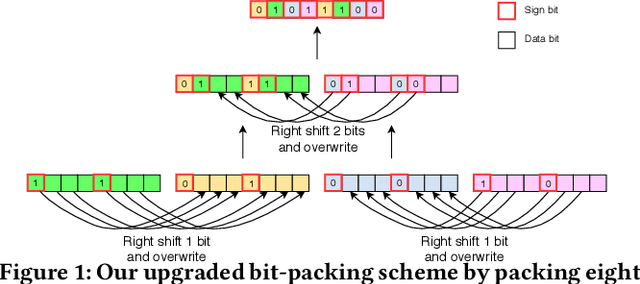

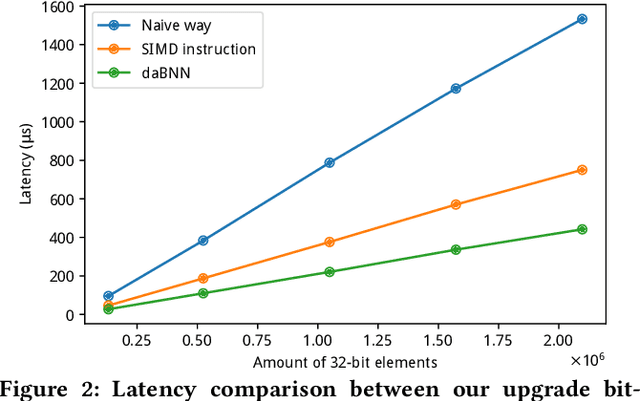
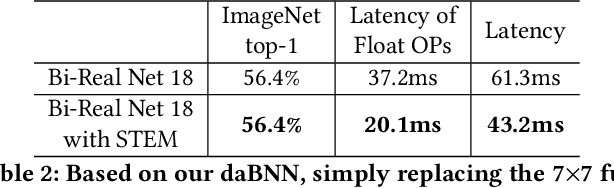
It is always well believed that Binary Neural Networks (BNNs) could drastically accelerate the inference efficiency by replacing the arithmetic operations in float-valued Deep Neural Networks (DNNs) with bit-wise operations. Nevertheless, there has not been open-source implementation in support of this idea on low-end ARM devices (e.g., mobile phones and embedded devices). In this work, we propose daBNN --- a super fast inference framework that implements BNNs on ARM devices. Several speed-up and memory refinement strategies for bit-packing, binarized convolution, and memory layout are uniquely devised to enhance inference efficiency. Compared to the recent open-source BNN inference framework, BMXNet, our daBNN is $7\times$$\sim$$23\times$ faster on a single binary convolution, and about $6\times$ faster on Bi-Real Net 18 (a BNN variant of ResNet-18). The daBNN is a BSD-licensed inference framework, and its source code, sample projects and pre-trained models are available on-line: https://github.com/JDAI-CV/dabnn.