 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-wise Representation Fusion for Compositional Generalization
Jul 20, 2023



Despite successes across a broad range of applications, sequence-to-sequence models' construct of solutions are argued to be less compositional than human-like generalization. There is mounting evidence that one of the reasons hindering compositional generalization is representations of the encoder and decoder uppermost layer are entangled. In other words, the syntactic and semantic representations of sequences are twisted inappropriately. However, most previous studies mainly concentrate on enhancing token-level semantic information to alleviate the representations entanglement problem, rather than composing and using the syntactic and semantic representations of sequences appropriately as humans do. In addition, we explain why the entanglement problem exists from the perspective of recent studies about training deeper Transformer, mainly owing to the ``shallow'' residual connections and its simple, one-step operations, which fails to fuse previous layers' information effectively. Starting from this finding and inspired by humans' strategies, we propose \textsc{FuSion} (\textbf{Fu}sing \textbf{S}yntactic and Semant\textbf{i}c Representati\textbf{on}s), an extension to sequence-to-sequence models to learn to fuse previous layers' information back into the encoding and decoding process appropriately through introducing a \emph{fuse-attention module} at each encoder and decoder layer. \textsc{FuSion} achieves competitive and even \textbf{state-of-the-art} results on two realistic benchmarks, which empirically demonstrates the effectiveness of our proposal.
Spatial-aware Speaker Diarization for Multi-channel Multi-party Meeting
Sep 24, 2022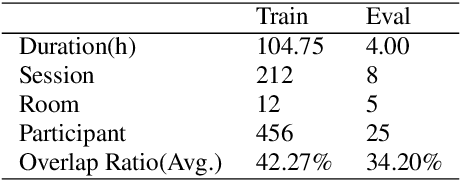
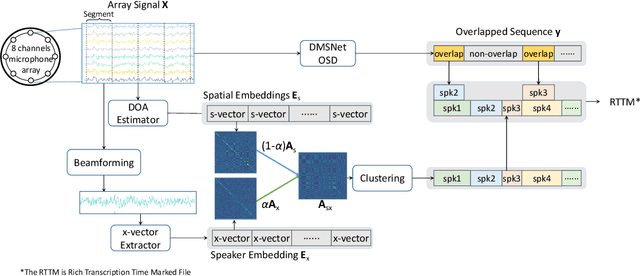
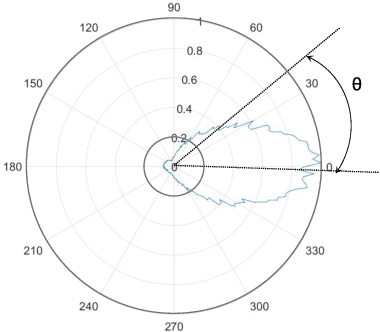

This paper describes a spatial-aware speaker diarization system for the multi-channel multi-party meeting. The diarization system obtains direction information of speaker by microphone array. Speaker spatial embedding is generated by xvector and s-vector derived from superdirective beamforming (SDB) which makes the embedding more robust. Specifically, we propose a novel multi-channel sequence-to-sequence neural network architecture named discriminative multi-stream neural network (DMSNet) which consists of attention superdirective beamforming (ASDB) block and Conformer encoder. The proposed ASDB is a self-adapted channel-wise block that extracts the latent spatial features of array audios by modeling interdependencies between channels. We explore DMSNet to address overlapped speech problem on multi-channel audio and achieve 93.53% accuracy on evaluation set. By performing DMSNet based overlapped speech detection (OSD) module, the diarization error rate (DER) of cluster-based diarization system decrease significantly from 13.45% to 7.64%.
The xmuspeech system for multi-channel multi-party meeting transcription challenge
Feb 11, 2022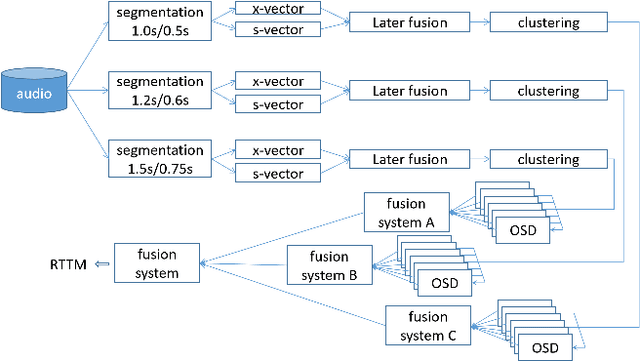

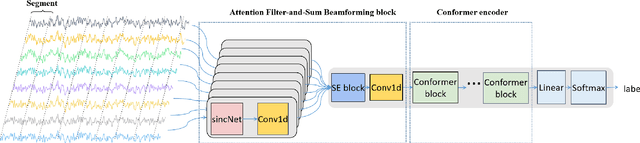
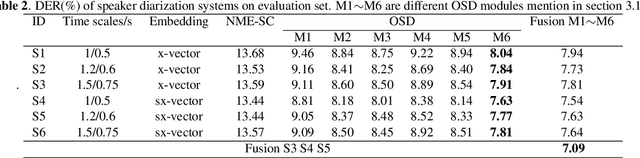
This paper describes the system developed by the XMUSPEECH team for the Multi-channel Multi-party Meeting Transcription Challenge (M2MeT). For the speaker diarization task, we propose a multi-channel speaker diarization system that obtains spatial information of speaker by Difference of Arrival (DOA) technology. Speaker-spatial embedding is generated by x-vector and s-vector derived from Filter-and-Sum Beamforming (FSB) which makes the embedding more robust. Specifically, we propose a novel multi-channel sequence-to-sequence neural network architecture named Discriminative Multi-stream Neural Network (DMSNet) which consists of Attention Filter-and-Sum block (AFSB) and Conformer encoder. We explore DMSNet to address overlapped speech problem on multi-channel audio. Compared with LSTM based OSD module, we achieve a decreases of 10.1% in Detection Error Rate(DetER). By performing DMSNet based OSD module, the DER of cluster-based diarization system decrease significantly form 13.44% to 7.63%. Our best fusion system achieves 7.09% and 9.80% of the diarization error rate (DER) on evaluation set and test set.
OLR 2021 Challenge: Datasets, Rules and Baselines
Jul 23, 2021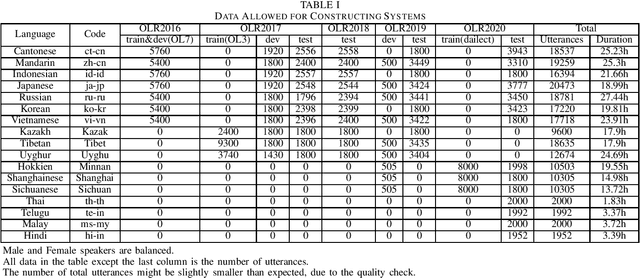

This paper introduces the sixth Oriental Language Recognition (OLR) 2021 Challenge, which intends to improve the performance of language recognition systems and speech recognition systems within multilingual scenarios. The data profile, four tasks, two baselines, and the evaluation principles are introduced in this paper. In addition to the Language Identification (LID) tasks, multilingual Automatic Speech Recognition (ASR) tasks are introduced to OLR 2021 Challenge for the first time. The challenge this year focuses on more practical and challenging problems, with four tasks: (1) constrained LID, (2) unconstrained LID, (3) constrained multilingual ASR, (4) unconstrained multilingual ASR. Baselines for LID tasks and multilingual ASR tasks are provided, respectively. The LID baseline system is an extended TDNN x-vector model constructed with Pytorch. A transformer-based end-to-end model is provided as the multilingual ASR baseline system. These recipes will be online published, and available for participants to construct their own LID or ASR systems. The baseline results demonstrate that those tasks are rather challenging and deserve more effort to achieve better performance.
Oriental Language Recognition (OLR) 2020: Summary and Analysis
Jul 05, 2021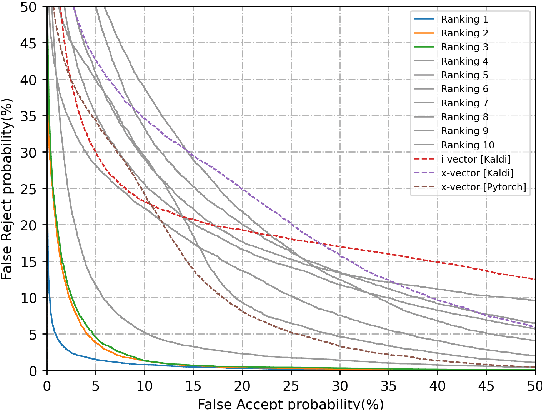
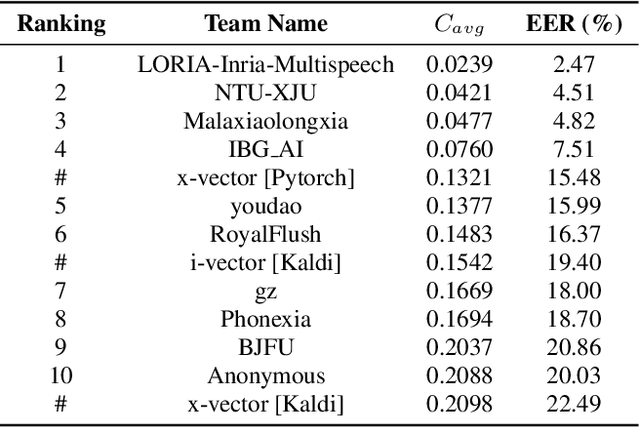
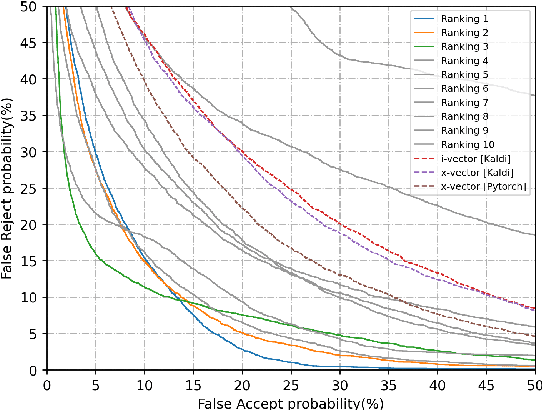
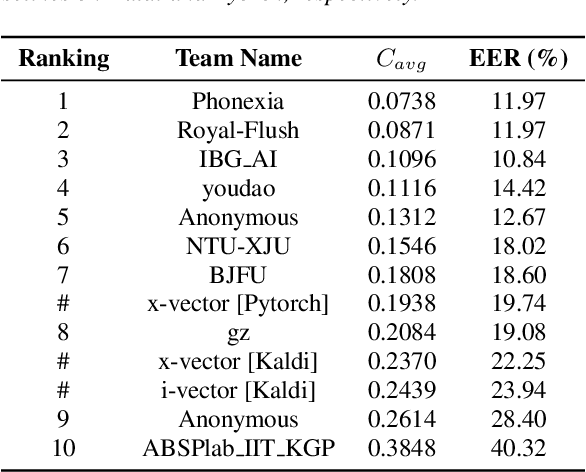
The fifth Oriental Language Recognition (OLR) Challenge focuses on language recognition in a variety of complex environments to promote its development. The OLR 2020 Challenge includes three tasks: (1) cross-channel language identification, (2) dialect identification, and (3) noisy language identification. We choose Cavg as the principle evaluation metric, and the Equal Error Rate (EER) as the secondary metric. There were 58 teams participating in this challenge and one third of the teams submitted valid results. Compared with the best baseline, the Cavg values of Top 1 system for the three tasks were relatively reduced by 82%, 62% and 48%, respectively. This paper describes the three tasks, the database profile, and the final results. We also outline the novel approaches that improve the performance of language recognition systems most significantly, such as the utilization of auxiliary information.