 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLR 2021 Challenge: Datasets, Rules and Baselines
Jul 23, 2021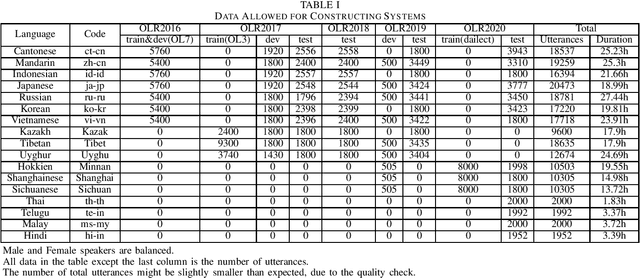

This paper introduces the sixth Oriental Language Recognition (OLR) 2021 Challenge, which intends to improve the performance of language recognition systems and speech recognition systems within multilingual scenarios. The data profile, four tasks, two baselines, and the evaluation principles are introduced in this paper. In addition to the Language Identification (LID) tasks, multilingual Automatic Speech Recognition (ASR) tasks are introduced to OLR 2021 Challenge for the first time. The challenge this year focuses on more practical and challenging problems, with four tasks: (1) constrained LID, (2) unconstrained LID, (3) constrained multilingual ASR, (4) unconstrained multilingual ASR. Baselines for LID tasks and multilingual ASR tasks are provided, respectively. The LID baseline system is an extended TDNN x-vector model constructed with Pytorch. A transformer-based end-to-end model is provided as the multilingual ASR baseline system. These recipes will be online published, and available for participants to construct their own LID or ASR systems. The baseline results demonstrate that those tasks are rather challenging and deserve more effort to achieve better performance.