 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe xmuspeech system for multi-channel multi-party meeting transcription challenge
Feb 11, 2022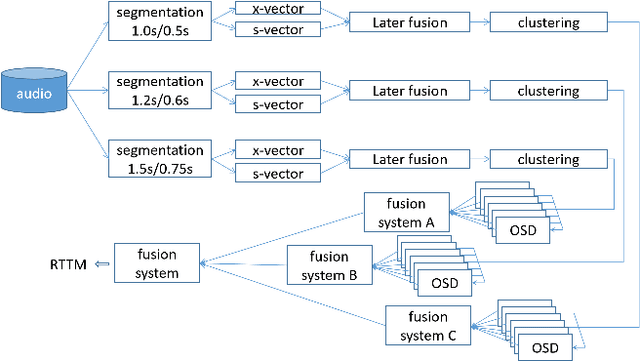

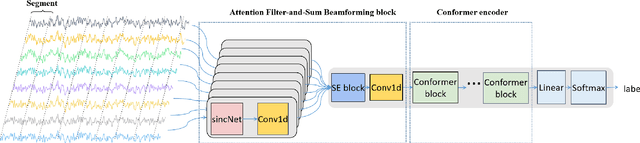
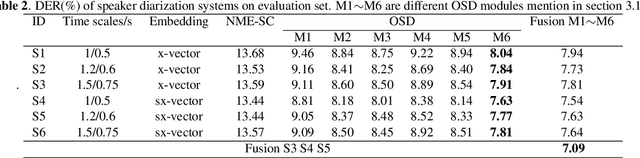
This paper describes the system developed by the XMUSPEECH team for the Multi-channel Multi-party Meeting Transcription Challenge (M2MeT). For the speaker diarization task, we propose a multi-channel speaker diarization system that obtains spatial information of speaker by Difference of Arrival (DOA) technology. Speaker-spatial embedding is generated by x-vector and s-vector derived from Filter-and-Sum Beamforming (FSB) which makes the embedding more robust. Specifically, we propose a novel multi-channel sequence-to-sequence neural network architecture named Discriminative Multi-stream Neural Network (DMSNet) which consists of Attention Filter-and-Sum block (AFSB) and Conformer encoder. We explore DMSNet to address overlapped speech problem on multi-channel audio. Compared with LSTM based OSD module, we achieve a decreases of 10.1% in Detection Error Rate(DetER). By performing DMSNet based OSD module, the DER of cluster-based diarization system decrease significantly form 13.44% to 7.63%. Our best fusion system achieves 7.09% and 9.80% of the diarization error rate (DER) on evaluation set and test set.