 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOriental Language Recognition (OLR) 2020: Summary and Analysis
Paper and Code
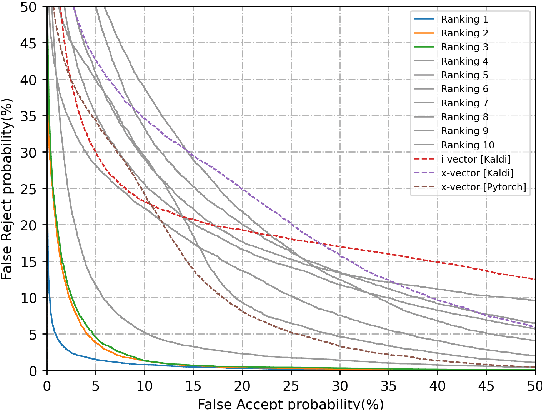
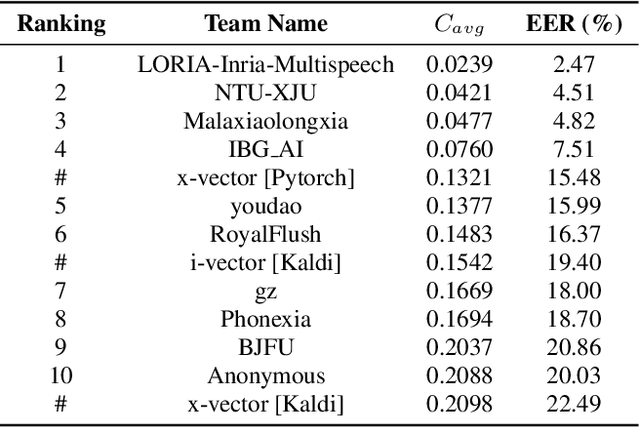
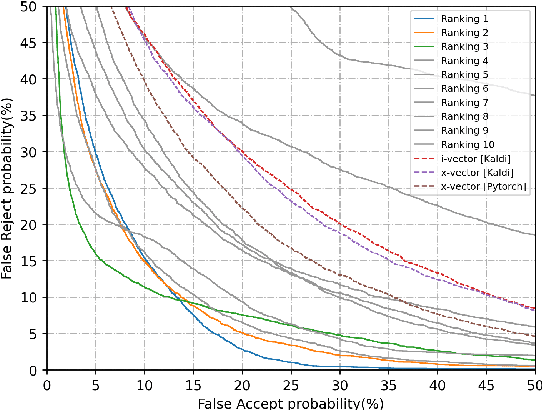
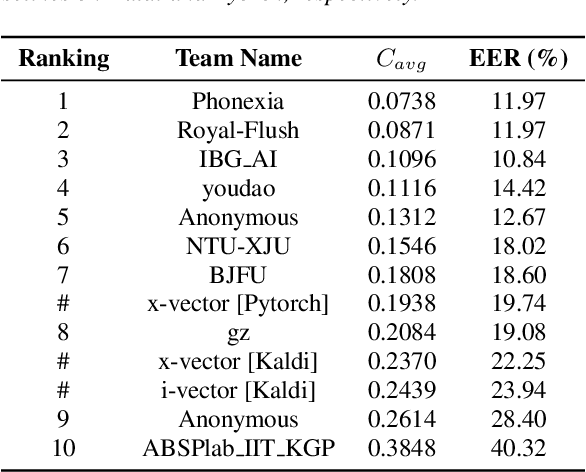
The fifth Oriental Language Recognition (OLR) Challenge focuses on language recognition in a variety of complex environments to promote its development. The OLR 2020 Challenge includes three tasks: (1) cross-channel language identification, (2) dialect identification, and (3) noisy language identification. We choose Cavg as the principle evaluation metric, and the Equal Error Rate (EER) as the secondary metric. There were 58 teams participating in this challenge and one third of the teams submitted valid results. Compared with the best baseline, the Cavg values of Top 1 system for the three tasks were relatively reduced by 82%, 62% and 48%, respectively. This paper describes the three tasks, the database profile, and the final results. We also outline the novel approaches that improve the performance of language recognition systems most significantly, such as the utilization of auxiliary information.