 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-aware Speaker Diarization for Multi-channel Multi-party Meeting
Paper and Code
Sep 24, 2022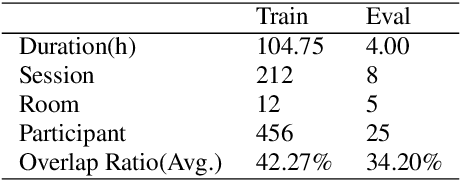
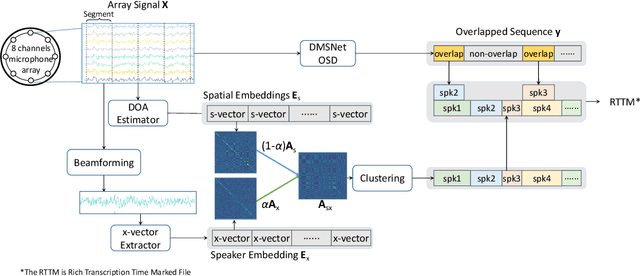
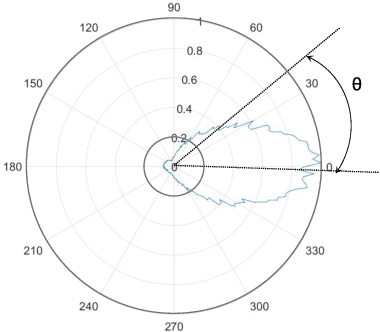

This paper describes a spatial-aware speaker diarization system for the multi-channel multi-party meeting. The diarization system obtains direction information of speaker by microphone array. Speaker spatial embedding is generated by xvector and s-vector derived from superdirective beamforming (SDB) which makes the embedding more robust. Specifically, we propose a novel multi-channel sequence-to-sequence neural network architecture named discriminative multi-stream neural network (DMSNet) which consists of attention superdirective beamforming (ASDB) block and Conformer encoder. The proposed ASDB is a self-adapted channel-wise block that extracts the latent spatial features of array audios by modeling interdependencies between channels. We explore DMSNet to address overlapped speech problem on multi-channel audio and achieve 93.53% accuracy on evaluation set. By performing DMSNet based overlapped speech detection (OSD) module, the diarization error rate (DER) of cluster-based diarization system decrease significantly from 13.45% to 7.64%.