 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDEPO: Group Dual-dynamic and Equal-right-advantage Policy Optimization with Enhanced Training Data Utilization for Sample-Constrained Reinforcement Learning
Jan 11, 2026Automated Theorem Proving (ATP) represents a fundamental challenge in Artificial Intelligence (AI), requiring the construction of machine-verifiable proofs in formal languages such as Lean to evaluate AI reasoning capabilities. Reinforcement learning (RL), particularly the high-performance Group Relative Policy Optimization (GRPO) algorithm, has emerged as a mainstream approach for this task. However, in ATP scenarios, GRPO faces two critical issues: when composite rewards are used, its relative advantage estimation may conflict with the binary feedback from the formal verifier; meanwhile, its static sampling strategy may discard entire batches of data if no valid proof is found, resulting in zero contribution to model updates and significant data waste. To address these limitations, we propose Group Dual-dynamic and Equal-right-advantage Policy Optimization (GDEPO), a method incorporating three core mechanisms: 1) dynamic additional sampling, which resamples invalid batches until a valid proof is discovered; 2) equal-right advantage, decoupling the sign of the advantage function (based on correctness) from its magnitude (modulated by auxiliary rewards) to ensure stable and correct policy updates; and 3) dynamic additional iterations, applying extra gradient steps to initially failed but eventually successful samples to accelerate learning on challenging cases. Experiments conducted on three datasets of varying difficulty (MinF2F-test, MathOlympiadBench, PutnamBench) confirm the effectiveness of GDEPO, while ablation studies validate the necessity of its synergistic components. The proposed method enhances data utilization and optimization efficiency, offering a novel training paradigm for ATP.
Exploring Task Unification in Graph Representation Learning via Generative Approach
Mar 21, 2024



Graphs are ubiquitous in real-world scenarios and encompass a diverse range of tasks, from node-, edge-, and graph-level tasks to transfer learning. However, designing specific tasks for each type of graph data is often costly and lacks generalizability. Recent endeavors under the "Pre-training + Fine-tuning" or "Pre-training + Prompt" paradigms aim to design a unified framework capable of generalizing across multiple graph tasks. Among these, graph autoencoders (GAEs), generative self-supervised models, have demonstrated their potential in effectively addressing various graph tasks. Nevertheless, these methods typically employ multi-stage training and require adaptive designs, which on one hand make it difficult to be seamlessly applied to diverse graph tasks and on the other hand overlook the negative impact caused by discrepancies in task objectives between the different stages. To address these challenges, we propose GA^2E, a unified adversarially masked autoencoder capable of addressing the above challenges seamlessly. Specifically, GA^2E proposes to use the subgraph as the meta-structure, which remains consistent across all graph tasks (ranging from node-, edge-, and graph-level to transfer learning) and all stages (both during training and inference). Further, GA^2E operates in a \textbf{"Generate then Discriminate"} manner. It leverages the masked GAE to reconstruct the input subgraph whilst treating it as a generator to compel the reconstructed graphs resemble the input subgraph. Furthermore, GA^2E introduces an auxiliary discriminator to discern the authenticity between the reconstructed (generated) subgraph and the input subgraph, thus ensuring the robustness of the graph representation through adversarial training mechanisms. We validate GA^2E's capabilities through extensive experiments on 21 datasets across four types of graph tasks.
Improving Large Language Models via Fine-grained Reinforcement Learning with Minimum Editing Constraint
Jan 11, 2024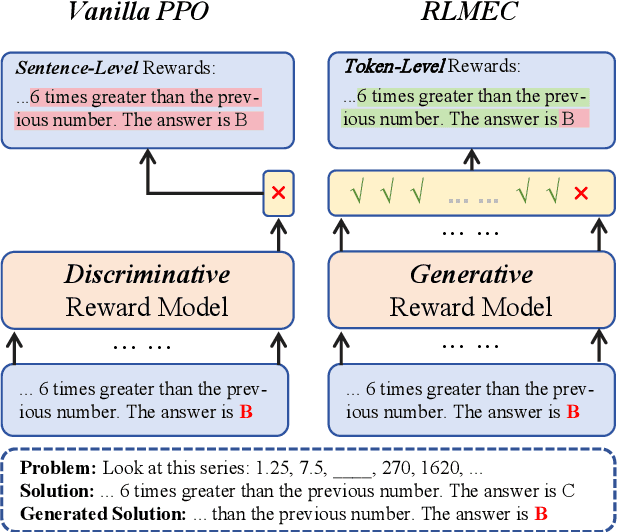
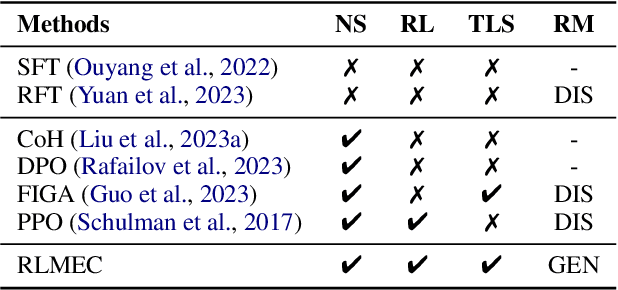
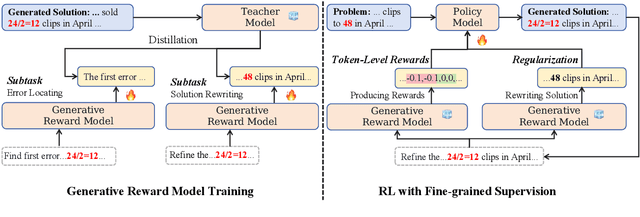
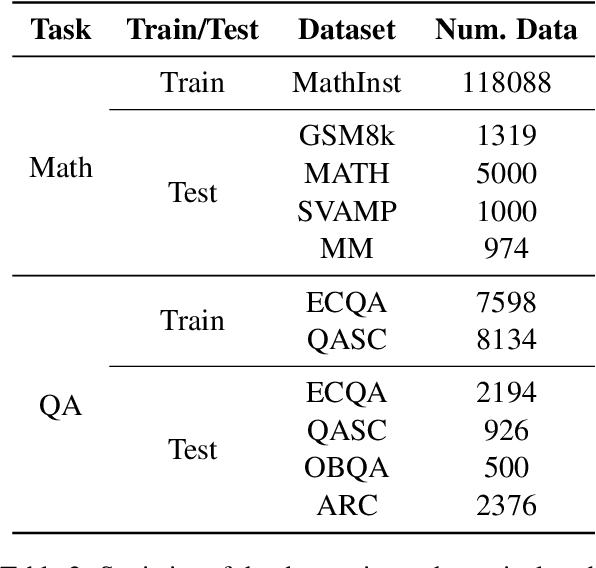
Reinforcement learning (RL) has been widely used in training large language models~(LLMs) for preventing unexpected outputs, \eg reducing harmfulness and errors. However, existing RL methods mostly adopt the instance-level reward, which is unable to provide fine-grained supervision for complex reasoning tasks, and can not focus on the few key tokens that lead to the incorrectness. To address it, we propose a new RL method named \textbf{RLMEC} that incorporates a generative model as the reward model, which is trained by the erroneous solution rewriting task under the minimum editing constraint, and can produce token-level rewards for RL training. Based on the generative reward model, we design the token-level RL objective for training and an imitation-based regularization for stabilizing RL process. And the both objectives focus on the learning of the key tokens for the erroneous solution, reducing the effect of other unimportant tokens. The experiment results on mathematical tasks and question-answering tasks have demonstrated the effectiveness of our approach. Our code and data are available at \url{https://github.com/RUCAIBox/RLMEC}.
Ask One More Time: Self-Agreement Improves Reasoning of Language Models in All Scenarios
Nov 14, 2023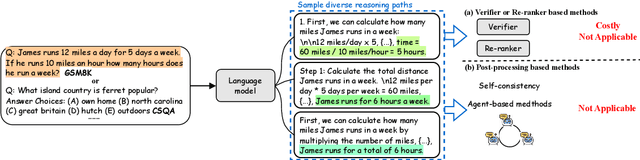



Although chain-of-thought (CoT) prompting combined with language models has achieved encouraging results on complex reasoning tasks, the naive greedy decoding used in CoT prompting usually causes the repetitiveness and local optimality. To address this shortcoming, ensemble-optimization tries to obtain multiple reasoning paths to get the final answer assembly. However, current ensemble-optimization methods either simply employ rule-based post-processing such as \textit{self-consistency}, or train an additional model based on several task-related human annotations to select the best one among multiple reasoning paths, yet fail to generalize to realistic settings where the type of input questions is unknown or the answer format of reasoning paths is unknown. To avoid their limitations, we propose \textbf{self-agreement}, a generalizable ensemble-optimization method applying in almost all scenarios where the type of input questions and the answer format of reasoning paths may be known or unknown. Self-agreement firstly samples from language model's decoder to generate a \textit{diverse} set of reasoning paths, and subsequently prompts the language model \textit{one more time} to determine the optimal answer by selecting the most \textit{agreed} answer among the sampled reasoning paths. Self-agreement simultaneously achieves remarkable performance on six public reasoning benchmarks and superior generalization capabilities.
Do We Really Need Contrastive Learning for Graph Representation?
Oct 23, 2023



In recent years, contrastive learning has emerged as a dominant self-supervised paradigm, attracting numerous research interests in the field of graph learning. Graph contrastive learning (GCL) aims to embed augmented anchor samples close to each other while pushing the embeddings of other samples (negative samples) apart. However, existing GCL methods require large and diverse negative samples to ensure the quality of embeddings, and recent studies typically leverage samples excluding the anchor and positive samples as negative samples, potentially introducing false negative samples (negatives that share the same class as the anchor). Additionally, this practice can result in heavy computational burden and high time complexity of $O(N^2)$, which is particularly unaffordable for large graphs. To address these deficiencies, we leverage rank learning and propose a simple yet effective model, GraphRank. Specifically, we first generate two graph views through corruption. Then, we compute the similarity of pairwise nodes (anchor node and positive node) in both views, an arbitrary node in the latter view is selected as a negative node, and its similarity with the anchor node is computed. Based on this, we introduce rank-based learning to measure similarity scores which successfully relieve the false negative provlem and decreases the time complexity from $O(N^2)$ to $O(N)$. Moreover, we conducted extensive experiments across multiple graph tasks, demonstrating that GraphRank performs favorably against other cutting-edge GCL methods in various tasks.
KwaiYiiMath: Technical Report
Oct 19, 2023



Recent advancements in large language models (LLMs) have demonstrated remarkable abilities in handling a variety of natural language processing (NLP) downstream tasks, even on mathematical tasks requiring multi-step reasoning. In this report, we introduce the KwaiYiiMath which enhances the mathematical reasoning abilities of KwaiYiiBase1, by applying Supervised Fine-Tuning (SFT) and Reinforced Learning from Human Feedback (RLHF), including on both English and Chinese mathematical tasks. Meanwhile, we also constructed a small-scale Chinese primary school mathematics test set (named KMath), consisting of 188 examples to evaluate the correctness of the problem-solving process generated by the models. Empirical studies demonstrate that KwaiYiiMath can achieve state-of-the-art (SOTA) performance on GSM8k, CMath, and KMath compared with the similar size models, respectively.
HGCVAE: Integrating Generative and Contrastive Learning for Heterogeneous Graph Learning
Oct 19, 2023



Generative self-supervised learning (SSL) has exhibited significant potential and garnered increasing interest in graph learning. In this study, we aim to explore the problem of generative SSL in the context of heterogeneous graph learning (HGL). The previous SSL approaches for heterogeneous graphs have primarily relied on contrastive learning, necessitating the design of complex views to capture heterogeneity. However, existing generative SSL methods have not fully leveraged the capabilities of generative models to address the challenges of HGL. In this paper, we present HGCVAE, a novel contrastive variational graph auto-encoder that liberates HGL from the burden of intricate heterogeneity capturing. Instead of focusing on complicated heterogeneity, HGCVAE harnesses the full potential of generative SSL. HGCVAE innovatively consolidates contrastive learning with generative SSL, introducing several key innovations. Firstly, we employ a progressive mechanism to generate high-quality hard negative samples for contrastive learning, utilizing the power of variational inference. Additionally, we present a dynamic mask strategy to ensure effective and stable learning. Moreover, we propose an enhanced scaled cosine error as the criterion for better attribute reconstruction. As an initial step in combining generative and contrastive SSL, HGCVAE achieves remarkable results compared to various state-of-the-art baselines, confirming its superiority.