 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTA: An Open Hardware-Software Stack for Deep Learning
Paper and Code
Jul 11, 2018
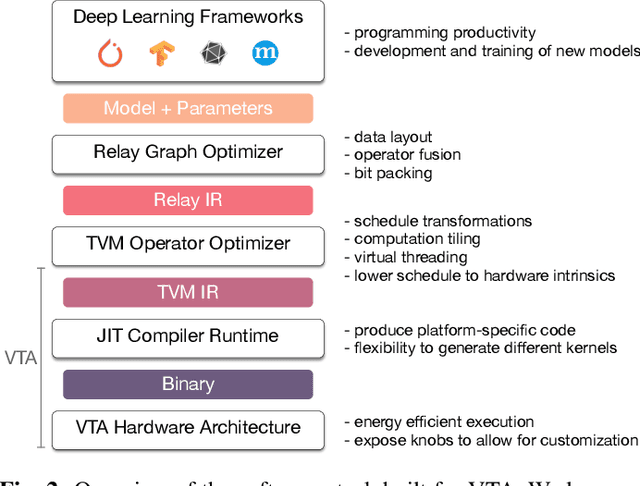

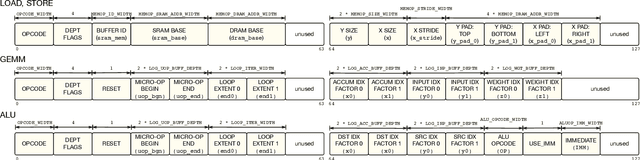
Hardware acceleration is an enabler for ubiquitous and efficient deep learning. With hardware accelerators being introduced in datacenter and edge devices, it is time to acknowledge that hardware specialization is central to the deep learning system stack. This technical report presents the Versatile Tensor Accelerator (VTA), an open, generic, and customizable deep learning accelerator design. VTA is a programmable accelerator that exposes a RISC-like programming abstraction to describe operations at the tensor level. We designed VTA to expose the most salient and common characteristics of mainstream deep learning accelerators, such as tensor operations, DMA load/stores, and explicit compute/memory arbitration. VTA is more than a standalone accelerator design: it's an end-to-end solution that includes drivers, a JIT runtime, and an optimizing compiler stack based on TVM. The current release of VTA includes a behavioral hardware simulator, as well as the infrastructure to deploy VTA on low-cost FPGA development boards for fast prototyping. By extending the TVM stack with a customizable, and open source deep learning hardware accelerator design, we are exposing a transparent end-to-end deep learning stack from the high-level deep learning framework, down to the actual hardware design and implementation. This forms a truly end-to-end, from software-to-hardware open source stack for deep learning systems.