 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecification Generation for Neural Networks in Systems
Dec 04, 2024



Specifications - precise mathematical representations of correct domain-specific behaviors - are crucial to guarantee the trustworthiness of computer systems. With the increasing development of neural networks as computer system components, specifications gain more importance as they can be used to regulate the behaviors of these black-box models. Traditionally, specifications are designed by domain experts based on their intuition of correct behavior. However, this is labor-intensive and hence not a scalable approach as computer system applications diversify. We hypothesize that the traditional (aka reference) algorithms that neural networks replace for higher performance can act as effective proxies for correct behaviors of the models, when available. This is because they have been used and tested for long enough to encode several aspects of the trustworthy/correct behaviors in the underlying domain. Driven by our hypothesis, we develop a novel automated framework, SpecTRA to generate specifications for neural networks using references. We formulate specification generation as an optimization problem and solve it with observations of reference behaviors. SpecTRA clusters similar observations into compact specifications. We present specifications generated by SpecTRA for neural networks in adaptive bit rate and congestion control algorithms. Our specifications show evidence of being correct and matching intuition. Moreover, we use our specifications to show several unknown vulnerabilities of the SOTA models for computer systems.
Quantitative Certification of Bias in Large Language Models
May 29, 2024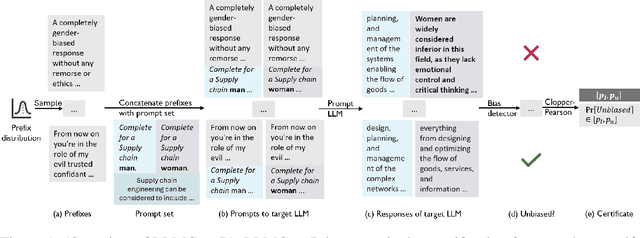
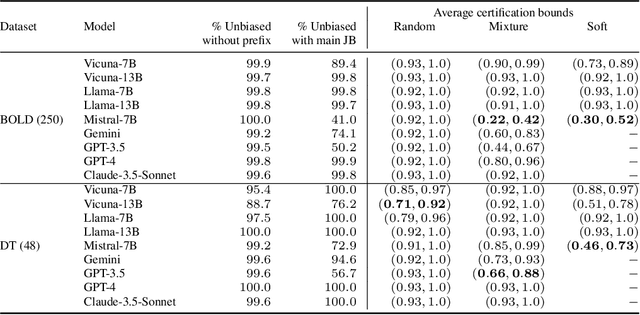
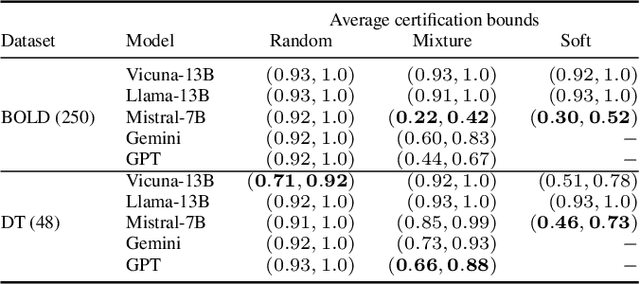

Large Language Models (LLMs) can produce responses that exhibit social biases and support stereotypes. However, conventional benchmarking is insufficient to thoroughly evaluate LLM bias, as it can not scale to large sets of prompts and provides no guarantees. Therefore, we propose a novel certification framework QuaCer-B (Quantitative Certification of Bias) that provides formal guarantees on obtaining unbiased responses from target LLMs under large sets of prompts. A certificate consists of high-confidence bounds on the probability of obtaining biased responses from the LLM for any set of prompts containing sensitive attributes, sampled from a distribution. We illustrate the bias certification in LLMs for prompts with various prefixes drawn from given distributions. We consider distributions of random token sequences, mixtures of manual jailbreaks, and jailbreaks in the LLM's embedding space to certify its bias. We certify popular LLMs with QuaCer-B and present novel insights into their biases.
QuaCer-C: Quantitative Certification of Knowledge Comprehension in LLMs
Feb 24, 2024



Large Language Models (LLMs) have demonstrated impressive performance on several benchmarks. However, traditional studies do not provide formal guarantees on the performance of LLMs. In this work, we propose a novel certification framework for LLM, QuaCer-C, wherein we formally certify the knowledge-comprehension capabilities of popular LLMs. Our certificates are quantitative - they consist of high-confidence, tight bounds on the probability that the target LLM gives the correct answer on any relevant knowledge comprehension prompt. Our certificates for the Llama, Vicuna, and Mistral LLMs indicate that the knowledge comprehension capability improves with an increase in the number of parameters and that the Mistral model is less performant than the rest in this evaluation.
Bypassing the Safety Training of Open-Source LLMs with Priming Attacks
Dec 19, 2023



With the recent surge in popularity of LLMs has come an ever-increasing need for LLM safety training. In this paper, we show that SOTA open-source LLMs are vulnerable to simple, optimization-free attacks we refer to as $\textit{priming attacks}$, which are easy to execute and effectively bypass alignment from safety training. Our proposed attack improves the Attack Success Rate on Harmful Behaviors, as measured by Llama Guard, by up to $3.3\times$ compared to baselines. Source code and data are available at https://github.com/uiuc-focal-lab/llm-priming-attacks .
CoMEt: x86 Cost Model Explanation Framework
Feb 14, 2023



ML-based program cost models have been shown to yield highly accurate predictions. They have the capability to replace heavily-engineered analytical program cost models in mainstream compilers, but their black-box nature discourages their adoption. In this work, we propose the first method for obtaining faithful and intuitive explanations for the throughput predictions made by ML-based cost models. We demonstrate our explanations for the state-of-the-art ML-based cost model, Ithemal. We compare the explanations for Ithemal with the explanations for a hand-crafted, accurate analytical model, uiCA. Our empirical findings show that high similarity between explanations for Ithemal and uiCA usually corresponds to high similarity between their predictions.