 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Monkeys at Play: Random Augmentations Cheaply Break LLM Safety Alignment
Nov 05, 2024



Safety alignment of Large Language Models (LLMs) has recently become a critical objective of model developers. In response, a growing body of work has been investigating how safety alignment can be bypassed through various jailbreaking methods, such as adversarial attacks. However, these jailbreak methods can be rather costly or involve a non-trivial amount of creativity and effort, introducing the assumption that malicious users are high-resource or sophisticated. In this paper, we study how simple random augmentations to the input prompt affect safety alignment effectiveness in state-of-the-art LLMs, such as Llama 3 and Qwen 2. We perform an in-depth evaluation of 17 different models and investigate the intersection of safety under random augmentations with multiple dimensions: augmentation type, model size, quantization, fine-tuning-based defenses, and decoding strategies (e.g., sampling temperature). We show that low-resource and unsophisticated attackers, i.e. $\textit{stochastic monkeys}$, can significantly improve their chances of bypassing alignment with just 25 random augmentations per prompt.
Bypassing the Safety Training of Open-Source LLMs with Priming Attacks
Dec 19, 2023



With the recent surge in popularity of LLMs has come an ever-increasing need for LLM safety training. In this paper, we show that SOTA open-source LLMs are vulnerable to simple, optimization-free attacks we refer to as $\textit{priming attacks}$, which are easy to execute and effectively bypass alignment from safety training. Our proposed attack improves the Attack Success Rate on Harmful Behaviors, as measured by Llama Guard, by up to $3.3\times$ compared to baselines. Source code and data are available at https://github.com/uiuc-focal-lab/llm-priming-attacks .
Neural Representation Learning for Scribal Hands of Linear B
Jul 14, 2021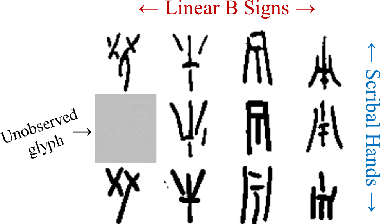
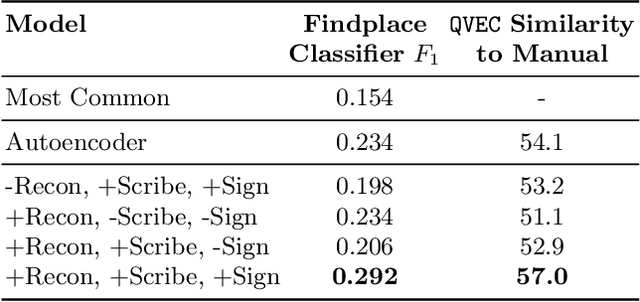
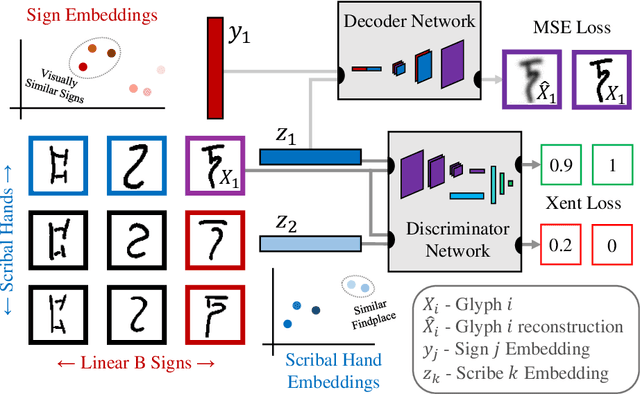
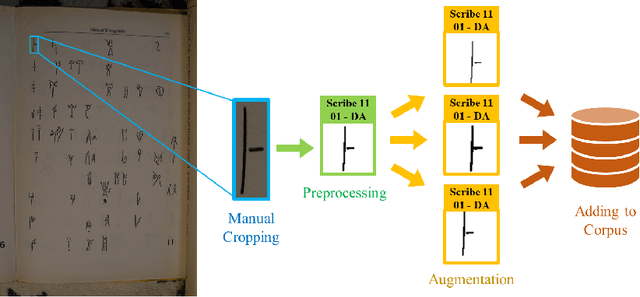
In this work, we present an investigation into the use of neural feature extraction in performing scribal hand analysis of the Linear B writing system. While prior work has demonstrated the usefulness of strategies such as phylogenetic systematics in tracing Linear B's history, these approaches have relied on manually extracted features which can be very time consuming to define by hand. Instead we propose learning features using a fully unsupervised neural network that does not require any human annotation. Specifically our model assigns each glyph written by the same scribal hand a shared vector embedding to represent that author's stylistic patterns, and each glyph representing the same syllabic sign a shared vector embedding to represent the identifying shape of that character. Thus the properties of each image in our dataset are represented as the combination of a scribe embedding and a sign embedding. We train this model using both a reconstructive loss governed by a decoder that seeks to reproduce glyphs from their corresponding embeddings, and a discriminative loss which measures the model's ability to predict whether or not an embedding corresponds to a given image. Among the key contributions of this work we (1) present a new dataset of Linear B glyphs, annotated by scribal hand and sign type, (2) propose a neural model for disentangling properties of scribal hands from glyph shape, and (3) quantitatively evaluate the learned embeddings on findplace prediction and similarity to manually extracted features, showing improvements over simpler baseline methods.