 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Lead Sheet Generation via Semantic Compression
Oct 16, 2023



Lead sheets have become commonplace in generative music research, being used as an initial compressed representation for downstream tasks like multitrack music generation and automatic arrangement. Despite this, researchers have often fallen back on deterministic reduction methods (such as the skyline algorithm) to generate lead sheets when seeking paired lead sheets and full scores, with little attention being paid toward the quality of the lead sheets themselves and how they accurately reflect their orchestrated counterparts. To address these issues, we propose the problem of conditional lead sheet generation (i.e. generating a lead sheet given its full score version), and show that this task can be formulated as an unsupervised music compression task, where the lead sheet represents a compressed latent version of the score. We introduce a novel model, called Lead-AE, that models the lead sheets as a discrete subselection of the original sequence, using a differentiable top-k operator to allow for controllable local sparsity constraints. Across both automatic proxy tasks and direct human evaluations, we find that our method improves upon the established deterministic baseline and produces coherent reductions of large multitrack scores.
Text Conditional Alt-Text Generation for Twitter Images
May 24, 2023In this work we present an approach for generating alternative text (or alt-text) descriptions for images shared on social media, specifically Twitter. This task is more than just a special case of image captioning, as alt-text is both more literally descriptive and context-specific. Also critically, images posted to Twitter are often accompanied by user-written text that despite not necessarily describing the image may provide useful context that if properly leveraged can be informative -- e.g. the tweet may name an uncommon object in the image that the model has not previously seen. We address this with a CLIP prefix model that extracts an embedding of the image and passes it to a mapping network that outputs a short sequence in word embedding space, or a ``prefix'', to which we also concatenate the text from the tweet itself. This lets the model condition on both visual and textual information from the post. The combined multimodal prefix is then fed as a prompt to a pretrained language model which autoregressively completes the sequence to generate the alt-text. While prior work has used similar methods for captioning, ours is the first to our knowledge that incorporates textual information from the associated social media post into the prefix as well, and we further demonstrate through ablations that utility of these two information sources stacks. We put forward a new dataset scraped from Twitter and evaluate on it across a variety of automated metrics as well as human evaluation, and show that our approach of conditioning on both tweet text and visual information significantly outperforms prior work.
Checklist Models for Improved Output Fluency in Piano Fingering Prediction
Sep 12, 2022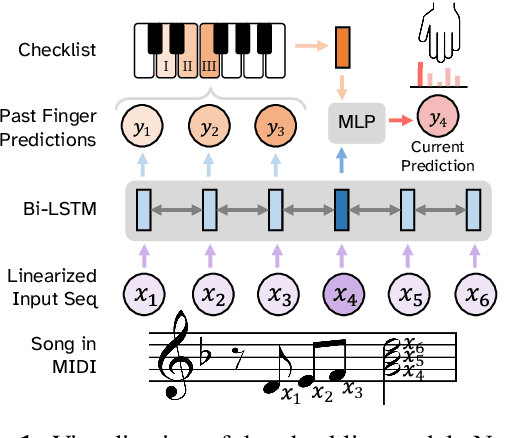
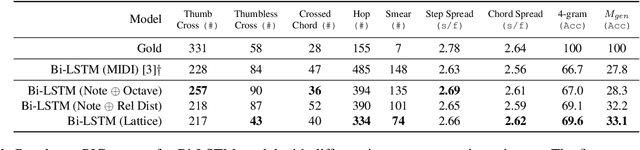
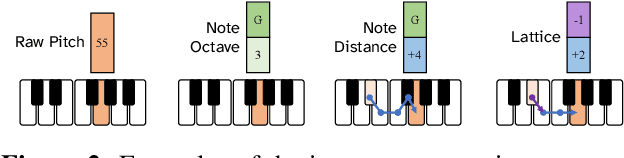
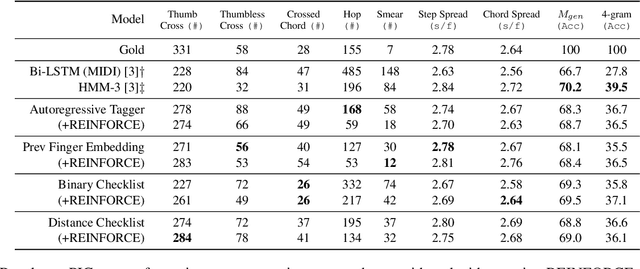
In this work we present a new approach for the task of predicting fingerings for piano music. While prior neural approaches have often treated this as a sequence tagging problem with independent predictions, we put forward a checklist system, trained via reinforcement learning, that maintains a representation of recent predictions in addition to a hidden state, allowing it to learn soft constraints on output structure. We also demonstrate that by modifying input representations -- which in prior work using neural models have often taken the form of one-hot encodings over individual keys on the piano -- to encode relative position on the keyboard to the prior note instead, we can achieve much better performance. Additionally, we reassess the use of raw per-note labeling precision as an evaluation metric, noting that it does not adequately measure the fluency, i.e. human playability, of a model's output. To this end, we compare methods across several statistics which track the frequency of adjacent finger predictions that while independently reasonable would be physically challenging to perform in sequence, and implement a reinforcement learning strategy to minimize these as part of our training loss. Finally through human expert evaluation, we demonstrate significant gains in performability directly attributable to improvements with respect to these metrics.
Scalable Font Reconstruction with Dual Latent Manifolds
Sep 10, 2021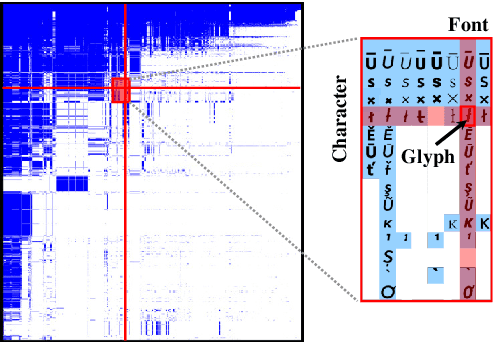
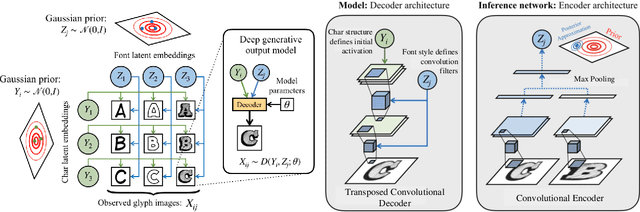
We propose a deep generative model that performs typography analysis and font reconstruction by learning disentangled manifolds of both font style and character shape. Our approach enables us to massively scale up the number of character types we can effectively model compared to previous methods. Specifically, we infer separate latent variables representing character and font via a pair of inference networks which take as input sets of glyphs that either all share a character type, or belong to the same font. This design allows our model to generalize to characters that were not observed during training time, an important task in light of the relative sparsity of most fonts. We also put forward a new loss, adapted from prior work that measures likelihood using an adaptive distribution in a projected space, resulting in more natural images without requiring a discriminator. We evaluate on the task of font reconstruction over various datasets representing character types of many languages, and compare favorably to modern style transfer systems according to both automatic and manually-evaluated metrics.
Neural Representation Learning for Scribal Hands of Linear B
Jul 14, 2021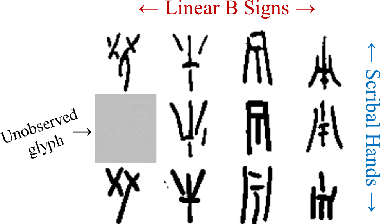
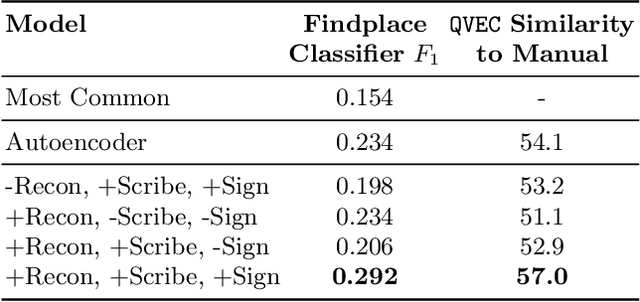
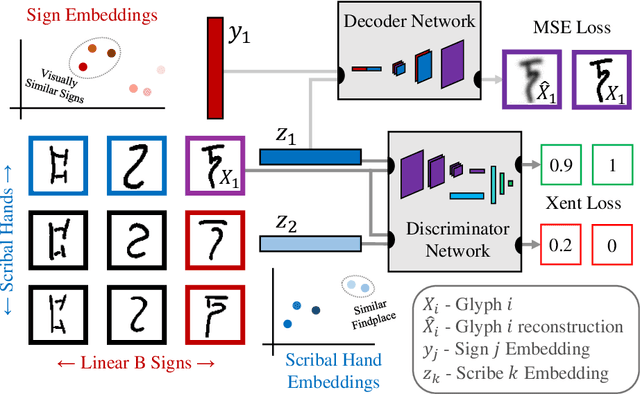
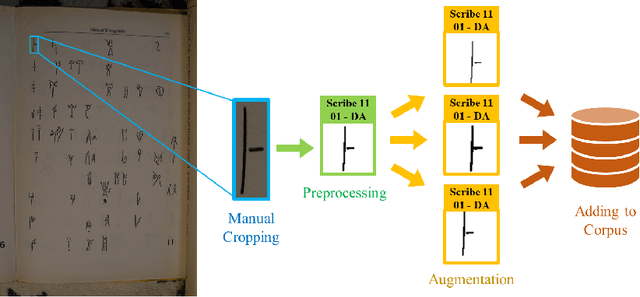
In this work, we present an investigation into the use of neural feature extraction in performing scribal hand analysis of the Linear B writing system. While prior work has demonstrated the usefulness of strategies such as phylogenetic systematics in tracing Linear B's history, these approaches have relied on manually extracted features which can be very time consuming to define by hand. Instead we propose learning features using a fully unsupervised neural network that does not require any human annotation. Specifically our model assigns each glyph written by the same scribal hand a shared vector embedding to represent that author's stylistic patterns, and each glyph representing the same syllabic sign a shared vector embedding to represent the identifying shape of that character. Thus the properties of each image in our dataset are represented as the combination of a scribe embedding and a sign embedding. We train this model using both a reconstructive loss governed by a decoder that seeks to reproduce glyphs from their corresponding embeddings, and a discriminative loss which measures the model's ability to predict whether or not an embedding corresponds to a given image. Among the key contributions of this work we (1) present a new dataset of Linear B glyphs, annotated by scribal hand and sign type, (2) propose a neural model for disentangling properties of scribal hands from glyph shape, and (3) quantitatively evaluate the learned embeddings on findplace prediction and similarity to manually extracted features, showing improvements over simpler baseline methods.