 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNURD: Negative-Unlabeled Learning for Online Datacenter Straggler Prediction
Mar 16, 2022


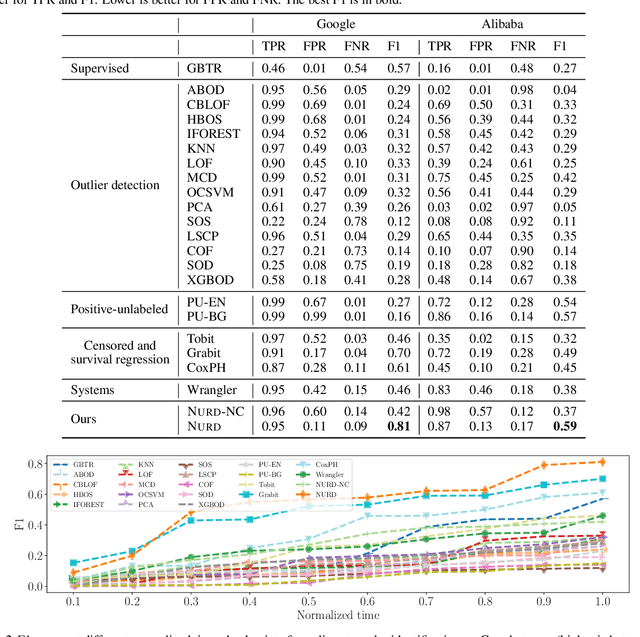
Datacenters execute large computational jobs, which are composed of smaller tasks. A job completes when all its tasks finish, so stragglers -- rare, yet extremely slow tasks -- are a major impediment to datacenter performance. Accurately predicting stragglers would enable proactive intervention, allowing datacenter operators to mitigate stragglers before they delay a job. While much prior work applies machine learning to predict computer system performance, these approaches rely on complete labels -- i.e., sufficient examples of all possible behaviors, including straggling and non-straggling -- or strong assumptions about the underlying latency distributions -- e.g., whether Gaussian or not. Within a running job, however, none of this information is available until stragglers have revealed themselves when they have already delayed the job. To predict stragglers accurately and early without labeled positive examples or assumptions on latency distributions, this paper presents NURD, a novel Negative-Unlabeled learning approach with Reweighting and Distribution-compensation that only trains on negative and unlabeled streaming data. The key idea is to train a predictor using finished tasks of non-stragglers to predict latency for unlabeled running tasks, and then reweight each unlabeled task's prediction based on a weighting function of its feature space. We evaluate NURD on two production traces from Google and Alibaba, and find that compared to the best baseline approach, NURD produces 2--11 percentage point increases in the F1 score in terms of prediction accuracy, and 4.7--8.8 percentage point improvements in job completion time.
Prediction in the presence of response-dependent missing labels
Mar 25, 2021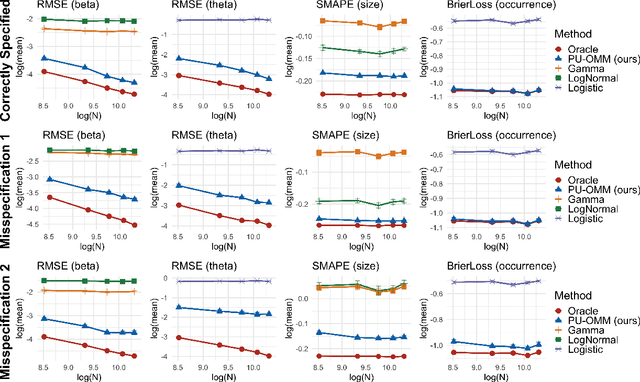
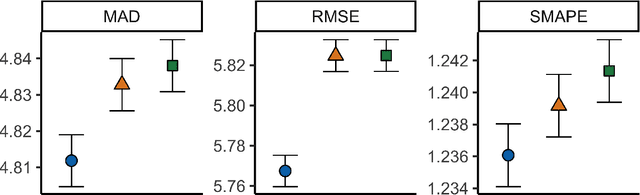
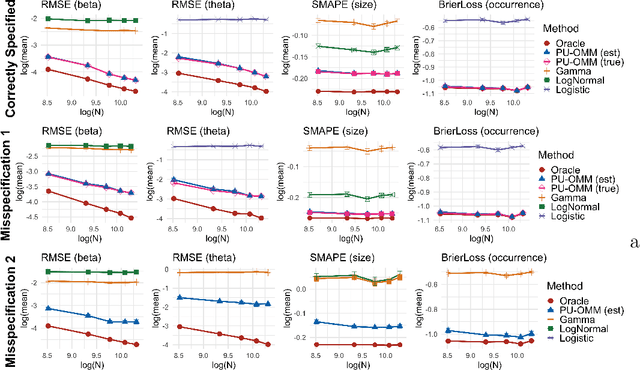
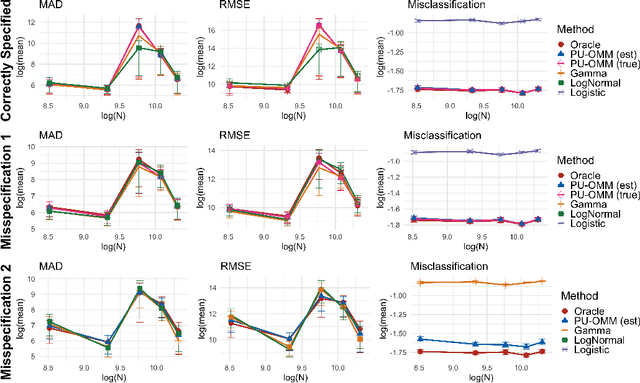
In a variety of settings, limitations of sensing technologies or other sampling mechanisms result in missing labels, where the likelihood of a missing label in the training set is an unknown function of the data. For example, satellites used to detect forest fires cannot sense fires below a certain size threshold. In such cases, training datasets consist of positive and pseudo-negative observations where pseudo-negative observations can be either true negatives or undetected positives with small magnitudes. We develop a new methodology and non-convex algorithm P(ositive) U(nlabeled) - O(ccurrence) M(agnitude) M(ixture) which jointly estimates the occurrence and detection likelihood of positive samples, utilizing prior knowledge of the detection mechanism. Our approach uses ideas from positive-unlabeled (PU)-learning and zero-inflated models that jointly estimate the magnitude and occurrence of events. We provide conditions under which our model is identifiable and prove that even though our approach leads to a non-convex objective, any local minimizer has optimal statistical error (up to a log term) and projected gradient descent has geometric convergence rates. We demonstrate on both synthetic data and a California wildfire dataset that our method out-performs existing state-of-the-art approaches.