 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChoosy Babies Need One Coach: Inducing Mode-Seeking Behavior in BabyLlama with Reverse KL Divergence
Paper and Code
Oct 29, 2024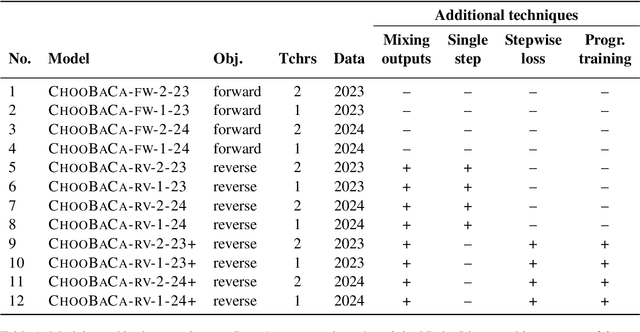

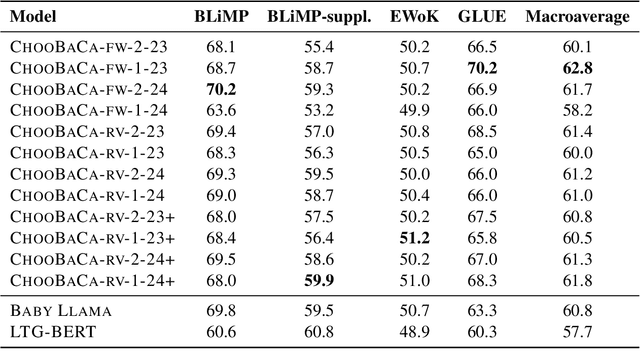
This study presents our submission to the Strict-Small Track of the 2nd BabyLM Challenge. We use a teacher-student distillation setup with the BabyLLaMa model (Timiryasov and Tastet, 2023) as a backbone. To make the student's learning process more focused, we replace the objective function with a reverse Kullback-Leibler divergence, known to cause mode-seeking (rather than mode-averaging) behaviour in computational learners. We further experiment with having a single teacher (instead of an ensemble of two teachers) and implement additional optimization strategies to improve the distillation process. Our experiments show that under reverse KL divergence, a single-teacher model often outperforms or matches multiple-teacher models across most tasks. Additionally, incorporating advanced optimization techniques further enhances model performance, demonstrating the effectiveness and robustness of our proposed approach. These findings support our idea that "choosy babies need one coach".