 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbarrassingly Simple Unsupervised Aspect Extraction
Apr 28, 2020
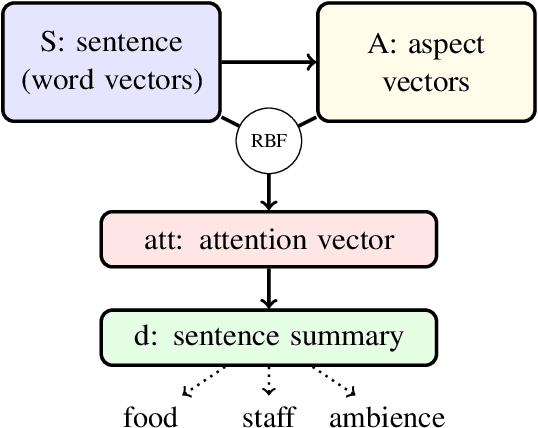

We present a simple but effective method for aspect identification in sentiment analysis. Our unsupervised method only requires word embeddings and a POS tagger, and is therefore straightforward to apply to new domains and languages. We introduce Contrastive Attention (CAt), a novel single-head attention mechanism based on an RBF kernel, which gives a considerable boost in performance and makes the model interpretable. Previous work relied on syntactic features and complex neural models. We show that given the simplicity of current benchmark datasets for aspect extraction, such complex models are not needed. The code to reproduce the experiments reported in this paper is available at https://github.com/clips/cat
A Short Review of Ethical Challenges in Clinical Natural Language Processing
Mar 29, 2017Clinical NLP has an immense potential in contributing to how clinical practice will be revolutionized by the advent of large scale processing of clinical records. However, this potential has remained largely untapped due to slow progress primarily caused by strict data access policies for researchers. In this paper, we discuss the concern for privacy and the measures it entails. We also suggest sources of less sensitive data. Finally, we draw attention to biases that can compromise the validity of empirical research and lead to socially harmful applications.
A Dictionary-based Approach to Racism Detection in Dutch Social Media
Aug 31, 2016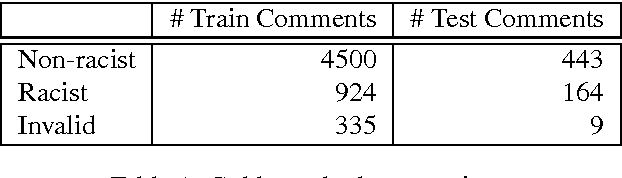

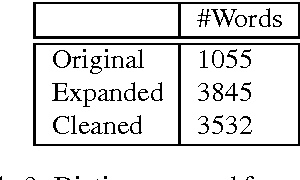

We present a dictionary-based approach to racism detection in Dutch social media comments, which were retrieved from two public Belgian social media sites likely to attract racist reactions. These comments were labeled as racist or non-racist by multiple annotators. For our approach, three discourse dictionaries were created: first, we created a dictionary by retrieving possibly racist and more neutral terms from the training data, and then augmenting these with more general words to remove some bias. A second dictionary was created through automatic expansion using a \texttt{word2vec} model trained on a large corpus of general Dutch text. Finally, a third dictionary was created by manually filtering out incorrect expansions. We trained multiple Support Vector Machines, using the distribution of words over the different categories in the dictionaries as features. The best-performing model used the manually cleaned dictionary and obtained an F-score of 0.46 for the racist class on a test set consisting of unseen Dutch comments, retrieved from the same sites used for the training set. The automated expansion of the dictionary only slightly boosted the model's performance, and this increase in performance was not statistically significant. The fact that the coverage of the expanded dictionaries did increase indicates that the words that were automatically added did occur in the corpus, but were not able to meaningfully impact performance. The dictionaries, code, and the procedure for requesting the corpus are available at: https://github.com/clips/hades
Using Distributed Representations to Disambiguate Biomedical and Clinical Concepts
Aug 19, 2016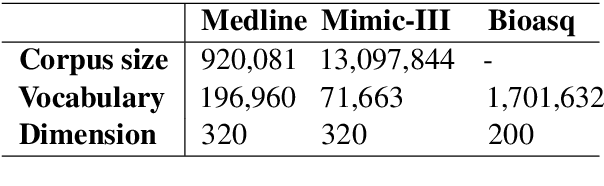


In this paper, we report a knowledge-based method for Word Sense Disambiguation in the domains of biomedical and clinical text. We combine word representations created on large corpora with a small number of definitions from the UMLS to create concept representations, which we then compare to representations of the context of ambiguous terms. Using no relational information, we obtain comparable performance to previous approaches on the MSH-WSD dataset, which is a well-known dataset in the biomedical domain. Additionally, our method is fast and easy to set up and extend to other domains. Supplementary materials, including source code, can be found at https: //github.com/clips/yarn
* 6 pages, 1 figure, presented at the 15th Workshop on Biomedical Natural Language Processing, Berlin 2016
Evaluating Unsupervised Dutch Word Embeddings as a Linguistic Resource
Jul 01, 2016



Word embeddings have recently seen a strong increase in interest as a result of strong performance gains on a variety of tasks. However, most of this research also underlined the importance of benchmark datasets, and the difficulty of constructing these for a variety of language-specific tasks. Still, many of the datasets used in these tasks could prove to be fruitful linguistic resources, allowing for unique observations into language use and variability. In this paper we demonstrate the performance of multiple types of embeddings, created with both count and prediction-based architectures on a variety of corpora, in two language-specific tasks: relation evaluation, and dialect identification. For the latter, we compare unsupervised methods with a traditional, hand-crafted dictionary. With this research, we provide the embeddings themselves, the relation evaluation task benchmark for use in further research, and demonstrate how the benchmarked embeddings prove a useful unsupervised linguistic resource, effectively used in a downstream task.