 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Texts in the Hebrew Bible, New Methods and Visualizations
Mar 04, 2016
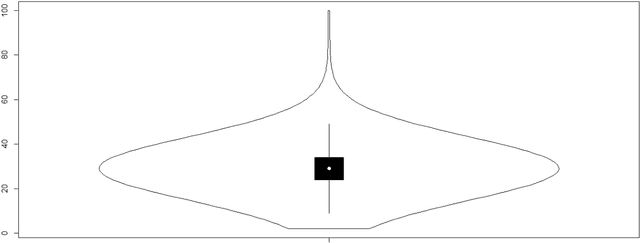


In this article we develop an algorithm to detect parallel texts in the Masoretic Text of the Hebrew Bible. The results are presented online and chapters in the Hebrew Bible containing parallel passages can be inspected synoptically. Differences between parallel passages are highlighted. In a similar way the MT of Isaiah is presented synoptically with 1QIsaa. We also investigate how one can investigate the degree of similarity between parallel passages with the help of a case study of 2 Kings 19-25 and its parallels in Isaiah, Jeremiah and 2 Chronicles.
The Hebrew Bible as Data: Laboratory - Sharing - Experiences
Jan 08, 2015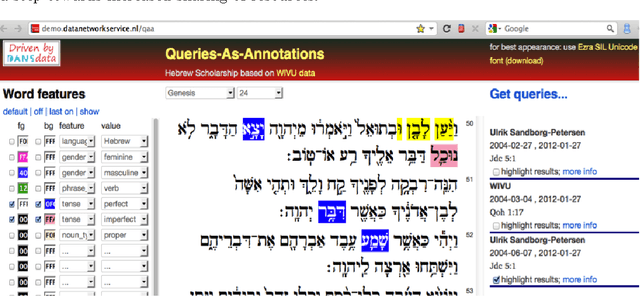


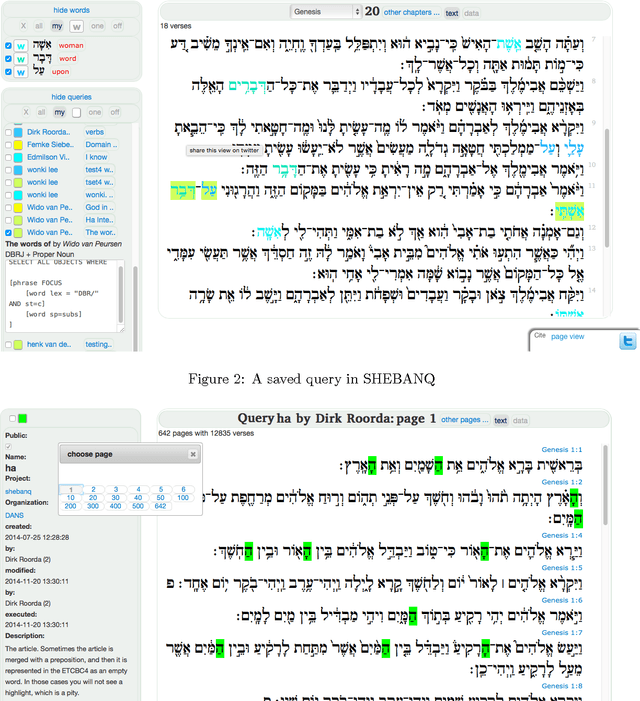
The systematic study of ancient texts including their production, transmission and interpretation is greatly aided by the digital methods that started taking off in the 1970s. But how is that research in turn transmitted to new generations of researchers? We tell a story of Bible and computer across the decades and then point out the current challenges: (1) finding a stable data representation for changing methods of computation; (2) sharing results in inter- and intra-disciplinary ways, for reproducibility and cross-fertilization. We report recent developments in meeting these challenges. The scene is the text database of the Hebrew Bible, constructed by the Eep Talstra Centre for Bible and Computer (ETCBC), which is still growing in detail and sophistication. We show how a subtle mix of computational ingredients enable scholars to research the transmission and interpretation of the Hebrew Bible in new ways: (1) a standard data format, Linguistic Annotation Framework (LAF); (2) the methods of scientific computing, made accessible by (interactive) Python and its associated ecosystem. Additionally, we show how these efforts have culminated in the construction of a new, publicly accessible search engine SHEBANQ, where the text of the Hebrew Bible and its underlying data can be queried in a simple, yet powerful query language MQL, and where those queries can be saved and shared.
Annotation as a New Paradigm in Research Archiving
Oct 07, 2014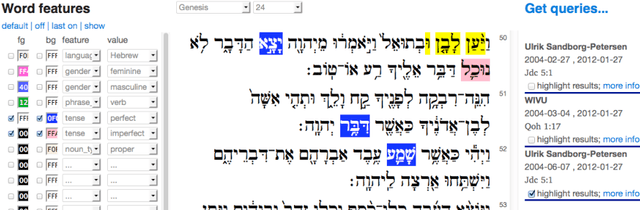

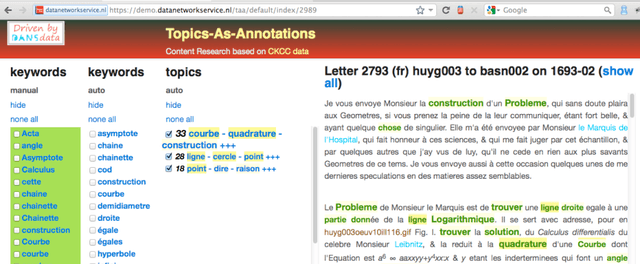
We outline a paradigm to preserve results of digital scholarship, whether they are query results, feature values, or topic assignments. This paradigm is characterized by using annotations as multifunctional carriers and making them portable. The testing grounds we have chosen are two significant enterprises, one in the history of science, and one in Hebrew scholarship. The first one (CKCC) focuses on the results of a project where a Dutch consortium of universities, research institutes, and cultural heritage institutions experimented for 4 years with language techniques and topic modeling methods with the aim to analyze the emergence of scholarly debates. The data: a complex set of about 20.000 letters. The second one (DTHB) is a multi-year effort to express the linguistic features of the Hebrew bible in a text database, which is still growing in detail and sophistication. Versions of this database are packaged in commercial bible study software. We state that the results of these forms of scholarship require new knowledge management and archive practices. Only when researchers can build efficiently on each other's (intermediate) results, they can achieve the aggregations of quality data by which new questions can be answered, and hidden patterns visualized. Archives are required to find a balance between preserving authoritative versions of sources and supporting collaborative efforts in digital scholarship. Annotations are promising vehicles for preserving and reusing research results. Keywords annotation, portability, archiving, queries, features, topics, keywords, Republic of Letters, Hebrew text databases.
* http://depot.knaw.nl/13026/
LAF-Fabric: a data analysis tool for Linguistic Annotation Framework with an application to the Hebrew Bible
Oct 01, 2014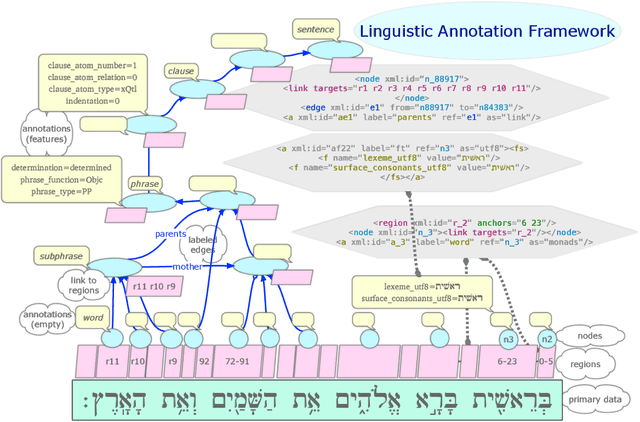
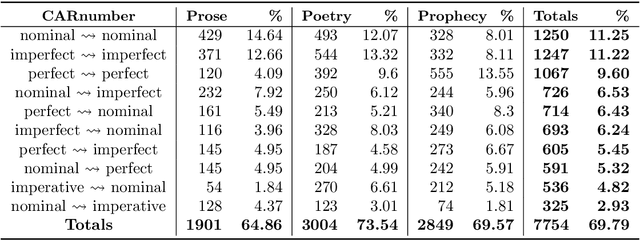


The Linguistic Annotation Framework (LAF) provides a general, extensible stand-off markup system for corpora. This paper discusses LAF-Fabric, a new tool to analyse LAF resources in general with an extension to process the Hebrew Bible in particular. We first walk through the history of the Hebrew Bible as text database in decennium-wide steps. Then we describe how LAF-Fabric may serve as an analysis tool for this corpus. Finally, we describe three analytic projects/workflows that benefit from the new LAF representation: 1) the study of linguistic variation: extract cooccurrence data of common nouns between the books of the Bible (Martijn Naaijer); 2) the study of the grammar of Hebrew poetry in the Psalms: extract clause typology (Gino Kalkman); 3) construction of a parser of classical Hebrew by Data Oriented Parsing: generate tree structures from the database (Andreas van Cranenburgh).