 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Hebrew Bible as Data: Laboratory - Sharing - Experiences
Paper and Code
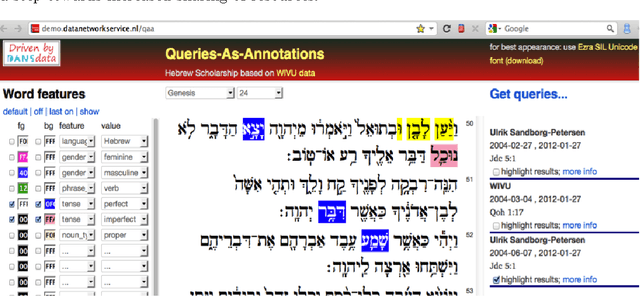


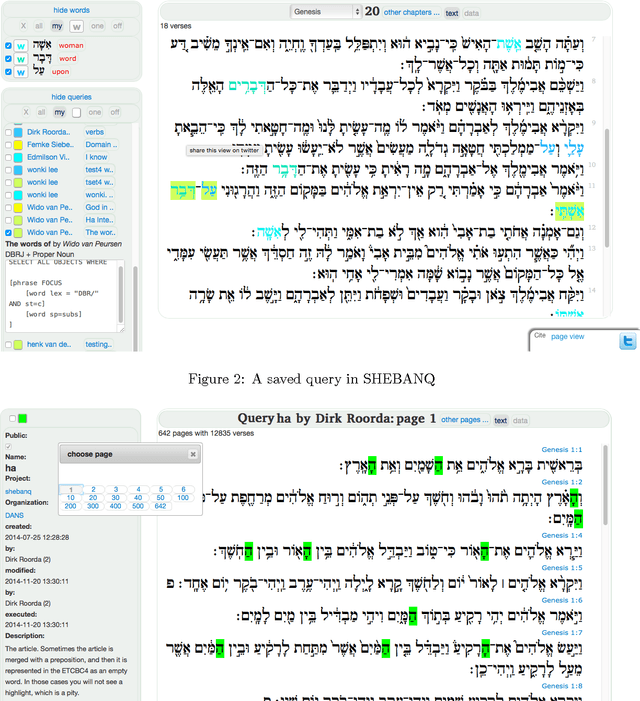
The systematic study of ancient texts including their production, transmission and interpretation is greatly aided by the digital methods that started taking off in the 1970s. But how is that research in turn transmitted to new generations of researchers? We tell a story of Bible and computer across the decades and then point out the current challenges: (1) finding a stable data representation for changing methods of computation; (2) sharing results in inter- and intra-disciplinary ways, for reproducibility and cross-fertilization. We report recent developments in meeting these challenges. The scene is the text database of the Hebrew Bible, constructed by the Eep Talstra Centre for Bible and Computer (ETCBC), which is still growing in detail and sophistication. We show how a subtle mix of computational ingredients enable scholars to research the transmission and interpretation of the Hebrew Bible in new ways: (1) a standard data format, Linguistic Annotation Framework (LAF); (2) the methods of scientific computing, made accessible by (interactive) Python and its associated ecosystem. Additionally, we show how these efforts have culminated in the construction of a new, publicly accessible search engine SHEBANQ, where the text of the Hebrew Bible and its underlying data can be queried in a simple, yet powerful query language MQL, and where those queries can be saved and shared.