 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Alignment of Discourse Relations of Different Discourse Annotation Frameworks
Apr 06, 2024



Existing discourse corpora are annotated based on different frameworks, which show significant dissimilarities in definitions of arguments and relations and structural constraints. Despite surface differences, these frameworks share basic understandings of discourse relations. The relationship between these frameworks has been an open research question, especially the correlation between relation inventories utilized in different frameworks. Better understanding of this question is helpful for integrating discourse theories and enabling interoperability of discourse corpora annotated under different frameworks. However, studies that explore correlations between discourse relation inventories are hindered by different criteria of discourse segmentation, and expert knowledge and manual examination are typically needed. Some semi-automatic methods have been proposed, but they rely on corpora annotated in multiple frameworks in parallel. In this paper, we introduce a fully automatic approach to address the challenges. Specifically, we extend the label-anchored contrastive learning method introduced by Zhang et al. (2022b) to learn label embeddings during a classification task. These embeddings are then utilized to map discourse relations from different frameworks. We show experimental results on RST-DT (Carlson et al., 2001) and PDTB 3.0 (Prasad et al., 2018).
Discourse Relations Classification and Cross-Framework Discourse Relation Classification Through the Lens of Cognitive Dimensions: An Empirical Investigation
Nov 01, 2023Existing discourse formalisms use different taxonomies of discourse relations, which require expert knowledge to understand, posing a challenge for annotation and automatic classification. We show that discourse relations can be effectively captured by some simple cognitively inspired dimensions proposed by Sanders et al.(2018). Our experiments on cross-framework discourse relation classification (PDTB & RST) demonstrate that it is possible to transfer knowledge of discourse relations for one framework to another framework by means of these dimensions, in spite of differences in discourse segmentation of the two frameworks. This manifests the effectiveness of these dimensions in characterizing discourse relations across frameworks. Ablation studies reveal that different dimensions influence different types of discourse relations. The patterns can be explained by the role of dimensions in characterizing and distinguishing different relations. We also report our experimental results on automatic prediction of these dimensions.
Towards Unification of Discourse Annotation Frameworks
Apr 16, 2022
Discourse information is difficult to represent and annotate. Among the major frameworks for annotating discourse information, RST, PDTB and SDRT are widely discussed and used, each having its own theoretical foundation and focus. Corpora annotated under different frameworks vary considerably. To make better use of the existing discourse corpora and achieve the possible synergy of different frameworks, it is worthwhile to investigate the systematic relations between different frameworks and devise methods of unifying the frameworks. Although the issue of framework unification has been a topic of discussion for a long time, there is currently no comprehensive approach which considers unifying both discourse structure and discourse relations and evaluates the unified framework intrinsically and extrinsically. We plan to use automatic means for the unification task and evaluate the result with structural complexity and downstream tasks. We will also explore the application of the unified framework in multi-task learning and graphical models.
Biaffine Discourse Dependency Parsing
Jan 12, 2022
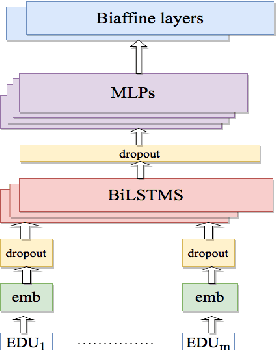
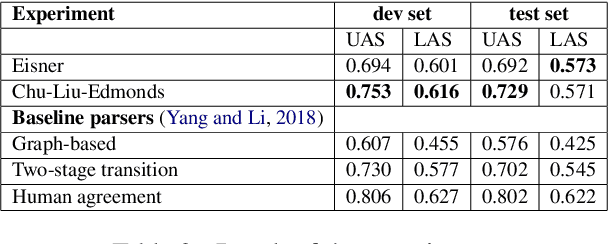
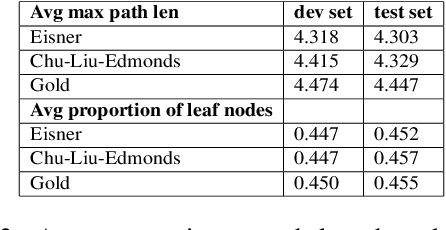
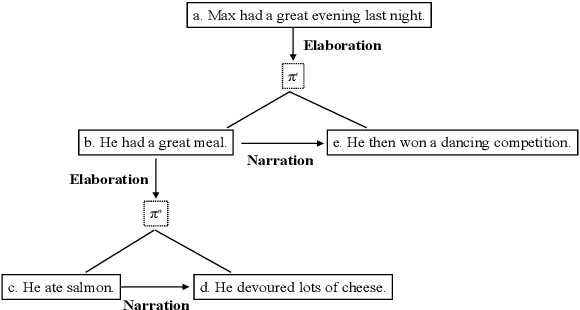
We provide a study of using the biaffine model for neural discourse dependency parsing and achieve significant performance improvement compared with the baseline parsers. We compare the Eisner algorithm and the Chu-Liu-Edmonds algorithm in the task and find that using the Chu-Liu-Edmonds algorithm generates deeper trees and achieves better performance. We also evaluate the structure of the output of the parser with average maximum path length and average proportion of leaf nodes and find that the dependency trees generated by the parser are close to the gold trees. As the corpus allows non-projective structures, we analyze the complexity of non-projectivity of the corpus and find that the dependency structures in this corpus have gap degree at most one and edge degree at most one.
Automatic Classification of Human Translation and Machine Translation: A Study from the Perspective of Lexical Diversity
May 10, 2021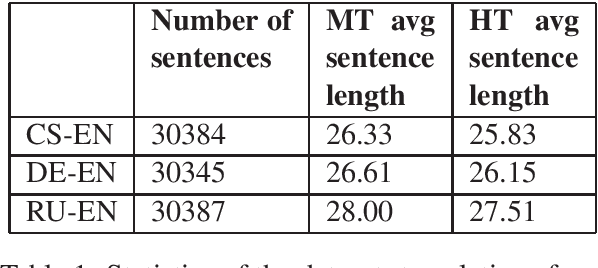
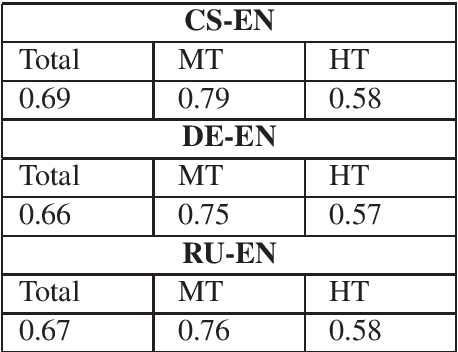
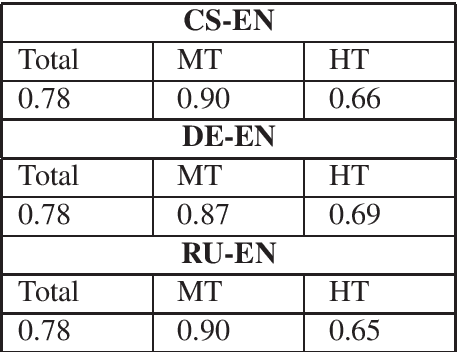
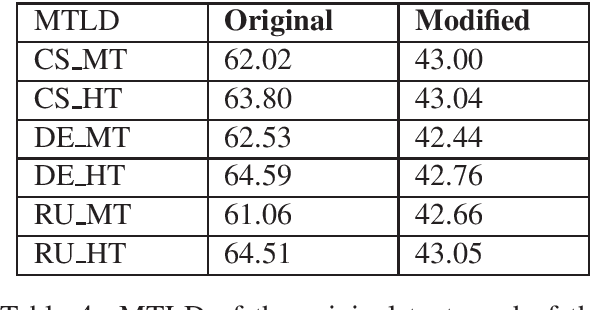
By using a trigram model and fine-tuning a pretrained BERT model for sequence classification, we show that machine translation and human translation can be classified with an accuracy above chance level, which suggests that machine translation and human translation are different in a systematic way. The classification accuracy of machine translation is much higher than of human translation. We show that this may be explained by the difference in lexical diversity between machine translation and human translation. If machine translation has independent patterns from human translation, automatic metrics which measure the deviation of machine translation from human translation may conflate difference with quality. Our experiment with two different types of automatic metrics shows correlation with the result of the classification task. Therefore, we suggest the difference in lexical diversity between machine translation and human translation be given more attention in machine translation evaluation.
A Pattern-mining Driven Study on Differences of Newspapers in Expressing Temporal Information
Nov 24, 2020

This paper studies the differences between different types of newspapers in expressing temporal information, which is a topic that has not received much attention. Techniques from the fields of temporal processing and pattern mining are employed to investigate this topic. First, a corpus annotated with temporal information is created by the author. Then, sequences of temporal information tags mixed with part-of-speech tags are extracted from the corpus. The TKS algorithm is used to mine skip-gram patterns from the sequences. With these patterns, the signatures of the four newspapers are obtained. In order to make the signatures uniquely characterize the newspapers, we revise the signatures by removing reference patterns. Through examining the number of patterns in the signatures and revised signatures, the proportion of patterns containing temporal information tags and the specific patterns containing temporal information tags, it is found that newspapers differ in ways of expressing temporal information.
* 19 pages