 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim-to-real Transfer of Deep Reinforcement Learning Agents for Online Coverage Path Planning
Jun 07, 2024



Sim-to-real transfer presents a difficult challenge, where models trained in simulation are to be deployed in the real world. The distribution shift between the two settings leads to biased representations of the perceived real-world environment, and thus to suboptimal predictions. In this work, we tackle the challenge of sim-to-real transfer of reinforcement learning (RL) agents for coverage path planning (CPP). In CPP, the task is for a robot to find a path that visits every point of a confined area. Specifically, we consider the case where the environment is unknown, and the agent needs to plan the path online while mapping the environment. We bridge the sim-to-real gap through a semi-virtual environment with a simulated sensor and obstacles, while including real robot kinematics and real-time aspects. We investigate what level of fine-tuning is needed for adapting to a realistic setting, comparing to an agent trained solely in simulation. We find that a high model inference frequency is sufficient for reducing the sim-to-real gap, while fine-tuning degrades performance initially. By training the model in simulation and deploying it at a high inference frequency, we transfer state-of-the-art results from simulation to the real domain, where direct learning would take in the order of weeks with manual interaction, i.e., would be completely infeasible.
End-to-end Reinforcement Learning for Online Coverage Path Planning in Unknown Environments
Jun 29, 2023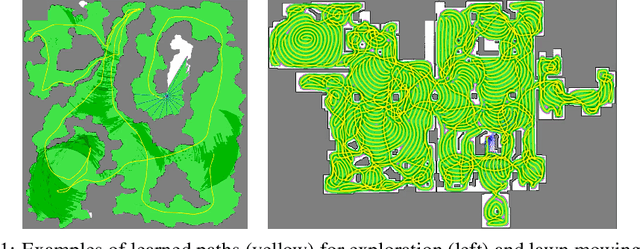
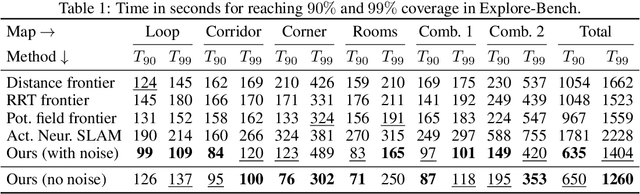
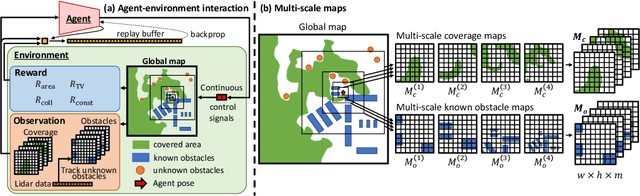
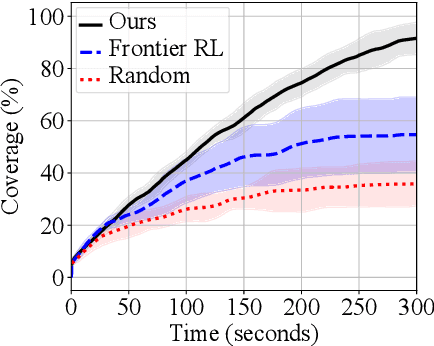
Coverage path planning is the problem of finding the shortest path that covers the entire free space of a given confined area, with applications ranging from robotic lawn mowing and vacuum cleaning, to demining and search-and-rescue tasks. While offline methods can find provably complete, and in some cases optimal, paths for known environments, their value is limited in online scenarios where the environment is not known beforehand, especially in the presence of non-static obstacles. We propose an end-to-end reinforcement learning-based approach in continuous state and action space, for the online coverage path planning problem that can handle unknown environments. We construct the observation space from both global maps and local sensory inputs, allowing the agent to plan a long-term path, and simultaneously act on short-term obstacle detections. To account for large-scale environments, we propose to use a multi-scale map input representation. Furthermore, we propose a novel total variation reward term for eliminating thin strips of uncovered space in the learned path. To validate the effectiveness of our approach, we perform extensive experiments in simulation with a distance sensor, surpassing the performance of a recent reinforcement learning-based approach.
High-fidelity Pseudo-labels for Boosting Weakly-Supervised Segmentation
Apr 05, 2023



The task of image-level weakly-supervised semantic segmentation (WSSS) has gained popularity in recent years, as it reduces the vast data annotation cost for training segmentation models. The typical approach for WSSS involves training an image classification network using global average pooling (GAP) on convolutional feature maps. This enables the estimation of object locations based on class activation maps (CAMs), which identify the importance of image regions. The CAMs are then used to generate pseudo-labels, in the form of segmentation masks, to supervise a segmentation model in the absence of pixel-level ground truth. In case of the SEAM baseline, a previous work proposed to improve CAM learning in two ways: (1) Importance sampling, which is a substitute for GAP, and (2) the feature similarity loss, which utilizes a heuristic that object contours almost exclusively align with color edges in images. In this work, we propose a different probabilistic interpretation of CAMs for these techniques, rendering the likelihood more appropriate than the multinomial posterior. As a result, we propose an add-on method that can boost essentially any previous WSSS method, improving both the region similarity and contour quality of all implemented state-of-the-art baselines. This is demonstrated on a wide variety of baselines on the PASCAL VOC dataset. Experiments on the MS COCO dataset show that performance gains can also be achieved in a large-scale setting. Our code is available at https://github.com/arvijj/hfpl.
Balanced Product of Experts for Long-Tailed Recognition
Jun 10, 2022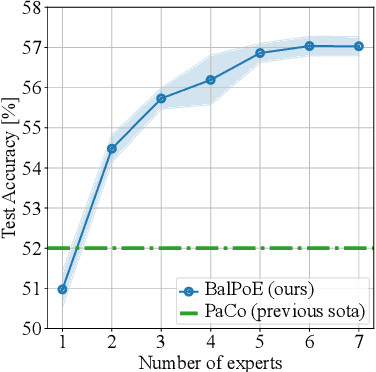
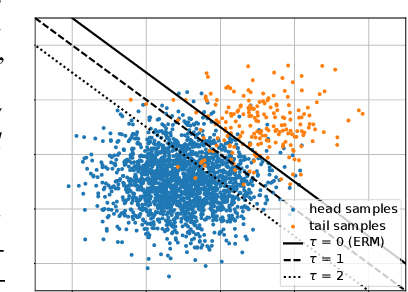
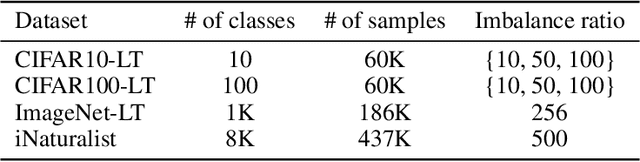
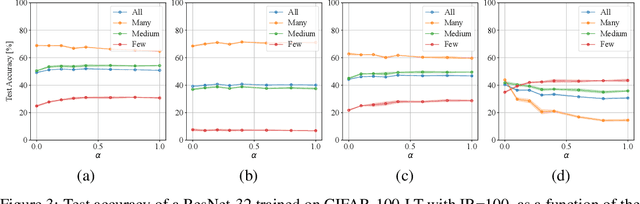
Many real-world recognition problems suffer from an imbalanced or long-tailed label distribution. Those distributions make representation learning more challenging due to limited generalization over the tail classes. If the test distribution differs from the training distribution, e.g. uniform versus long-tailed, the problem of the distribution shift needs to be addressed. To this aim, recent works have extended softmax cross-entropy using margin modifications, inspired by Bayes' theorem. In this paper, we generalize several approaches with a Balanced Product of Experts (BalPoE), which combines a family of models with different test-time target distributions to tackle the imbalance in the data. The proposed experts are trained in a single stage, either jointly or independently, and fused seamlessly into a BalPoE. We show that BalPoE is Fisher consistent for minimizing the balanced error and perform extensive experiments to validate the effectiveness of our approach. Finally, we investigate the effect of Mixup in this setting, discovering that regularization is a key ingredient for learning calibrated experts. Our experiments show that a regularized BalPoE can perform remarkably well in test accuracy and calibration metrics, leading to state-of-the-art results on CIFAR-100-LT, ImageNet-LT, and iNaturalist-2018 datasets. The code will be made publicly available upon paper acceptance.
Activation-Based Sampling for Pixel- to Image-Level Aggregation in Weakly-Supervised Segmentation
Mar 23, 2022
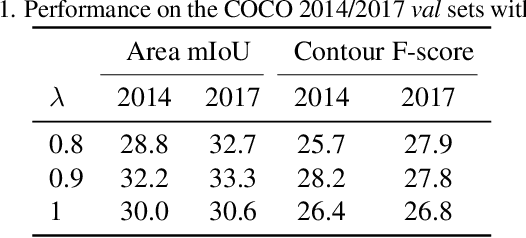


Classification networks can be used to localize and segment objects in images by means of class activation maps (CAMs). However, without pixel-level annotations, they are known to (1) mainly focus on discriminative regions, and (2) to produce diffuse CAMs without well-defined prediction contours. In this work, we approach both problems with two contributions for improving CAM learning. First, we incorporate importance sampling based on the class-wise probability mass function induced by the CAMs to produce stochastic image-level class predictions. This results in CAMs which activate over a larger extent of the objects. Second, we formulate a feature similarity loss term which aims to match the prediction contours with edges in the image. As a third contribution, we conduct experiments on the PASCAL VOC and MS-COCO benchmark datasets to demonstrate that these modifications significantly increase the performance in terms of contour accuracy, while being comparable to current state-of-the-art methods in terms of region similarity.