 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the relationship between regularity and learnability in recursive numeral systems using Reinforcement Learning
Feb 25, 2026Human recursive numeral systems (i.e., counting systems such as English base-10 numerals), like many other grammatical systems, are highly regular. Following prior work that relates cross-linguistic tendencies to biases in learning, we ask whether regular systems are common because regularity facilitates learning. Adopting methods from the Reinforcement Learning literature, we confirm that highly regular human(-like) systems are easier to learn than unattested but possible irregular systems. This asymmetry emerges under the natural assumption that recursive numeral systems are designed for generalisation from limited data to represent all integers exactly. We also find that the influence of regularity on learnability is absent for unnatural, highly irregular systems, whose learnability is influenced instead by signal length, suggesting that different pressures may influence learnability differently in different parts of the space of possible numeral systems. Our results contribute to the body of work linking learnability to cross-linguistic prevalence.
Recursive numeral systems are highly regular and easy to process
Oct 30, 2025Previous work has argued that recursive numeral systems optimise the trade-off between lexicon size and average morphosyntatic complexity (Deni\'c and Szymanik, 2024). However, showing that only natural-language-like systems optimise this tradeoff has proven elusive, and the existing solution has relied on ad-hoc constraints to rule out unnatural systems (Yang and Regier, 2025). Here, we argue that this issue arises because the proposed trade-off has neglected regularity, a crucial aspect of complexity central to human grammars in general. Drawing on the Minimum Description Length (MDL) approach, we propose that recursive numeral systems are better viewed as efficient with regard to their regularity and processing complexity. We show that our MDL-based measures of regularity and processing complexity better capture the key differences between attested, natural systems and unattested but possible ones, including "optimal" recursive numeral systems from previous work, and that the ad-hoc constraints from previous literature naturally follow from regularity. Our approach highlights the need to incorporate regularity across sets of forms in studies that attempt to measure and explain optimality in language.
Benchmarking Debiasing Methods for LLM-based Parameter Estimates
Jun 11, 2025Large language models (LLMs) offer an inexpensive yet powerful way to annotate text, but are often inconsistent when compared with experts. These errors can bias downstream estimates of population parameters such as regression coefficients and causal effects. To mitigate this bias, researchers have developed debiasing methods such as Design-based Supervised Learning (DSL) and Prediction-Powered Inference (PPI), which promise valid estimation by combining LLM annotations with a limited number of expensive expert annotations. Although these methods produce consistent estimates under theoretical assumptions, it is unknown how they compare in finite samples of sizes encountered in applied research. We make two contributions: First, we study how each method's performance scales with the number of expert annotations, highlighting regimes where LLM bias or limited expert labels significantly affect results. Second, we compare DSL and PPI across a range of tasks, finding that although both achieve low bias with large datasets, DSL often outperforms PPI on bias reduction and empirical efficiency, but its performance is less consistent across datasets. Our findings indicate that there is a bias-variance tradeoff at the level of debiasing methods, calling for more research on developing metrics for quantifying their efficiency in finite samples.
Lemmanaid: Neuro-Symbolic Lemma Conjecturing
Apr 07, 2025Automatically conjecturing useful, interesting and novel lemmas would greatly improve automated reasoning tools and lower the bar for formalizing mathematics in proof assistants. It is however a very challenging task for both neural and symbolic approaches. We present the first steps towards a practical neuro-symbolic lemma conjecturing tool, Lemmanaid, that combines Large Language Models (LLMs) and symbolic methods, and evaluate it on proof libraries for the Isabelle proof assistant. We train an LLM to generate lemma templates that describe the shape of a lemma, and use symbolic methods to fill in the details. We compare Lemmanaid against an LLM trained to generate complete lemma statements as well as previous fully symbolic conjecturing methods. Our results indicate that neural and symbolic techniques are complementary. By leveraging the best of both symbolic and neural methods we can generate useful lemmas for a wide range of input domains, facilitating computer-assisted theory development and formalization.
Fact Recall, Heuristics or Pure Guesswork? Precise Interpretations of Language Models for Fact Completion
Oct 18, 2024Previous interpretations of language models (LMs) miss important distinctions in how these models process factual information. For example, given the query "Astrid Lindgren was born in" with the corresponding completion "Sweden", no difference is made between whether the prediction was based on having the exact knowledge of the birthplace of the Swedish author or assuming that a person with a Swedish-sounding name was born in Sweden. In this paper, we investigate four different prediction scenarios for which the LM can be expected to show distinct behaviors. These scenarios correspond to different levels of model reliability and types of information being processed - some being less desirable for factual predictions. To facilitate precise interpretations of LMs for fact completion, we propose a model-specific recipe called PrISM for constructing datasets with examples of each scenario based on a set of diagnostic criteria. We apply a popular interpretability method, causal tracing (CT), to the four prediction scenarios and find that while CT produces different results for each scenario, aggregations over a set of mixed examples may only represent the results from the scenario with the strongest measured signal. In summary, we contribute tools for a more granular study of fact completion in language models and analyses that provide a more nuanced understanding of how LMs process fact-related queries.
ACE: Abstractions for Communicating Efficiently
Sep 30, 2024A central but unresolved aspect of problem-solving in AI is the capability to introduce and use abstractions, something humans excel at. Work in cognitive science has demonstrated that humans tend towards higher levels of abstraction when engaged in collaborative task-oriented communication, enabling gradually shorter and more information-efficient utterances. Several computational methods have attempted to replicate this phenomenon, but all make unrealistic simplifying assumptions about how abstractions are introduced and learned. Our method, Abstractions for Communicating Efficiently (ACE), overcomes these limitations through a neuro-symbolic approach. On the symbolic side, we draw on work from library learning for proposing abstractions. We combine this with neural methods for communication and reinforcement learning, via a novel use of bandit algorithms for controlling the exploration and exploitation trade-off in introducing new abstractions. ACE exhibits similar tendencies to humans on a collaborative construction task from the cognitive science literature, where one agent (the architect) instructs the other (the builder) to reconstruct a scene of block-buildings. ACE results in the emergence of an efficient language as a by-product of collaborative communication. Beyond providing mechanistic insights into human communication, our work serves as a first step to providing conversational agents with the ability for human-like communicative abstractions.
Setting the AI Agenda -- Evidence from Sweden in the ChatGPT Era
Sep 25, 2024This paper examines the development of the Artificial Intelligence (AI) meta-debate in Sweden before and after the release of ChatGPT. From the perspective of agenda-setting theory, we propose that it is an elite outside of party politics that is leading the debate -- i.e. that the politicians are relatively silent when it comes to this rapid development. We also suggest that the debate has become more substantive and risk-oriented in recent years. To investigate this claim, we draw on an original dataset of elite-level documents from the early 2010s to the present, using op-eds published in a number of leading Swedish newspapers. By conducting a qualitative content analysis of these materials, our preliminary findings lend support to the expectation that an academic, rather than a political elite is steering the debate.
Learning Efficient Recursive Numeral Systems via Reinforcement Learning
Sep 11, 2024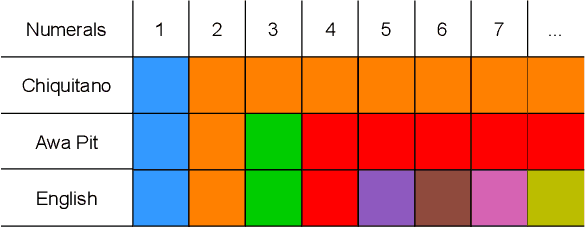

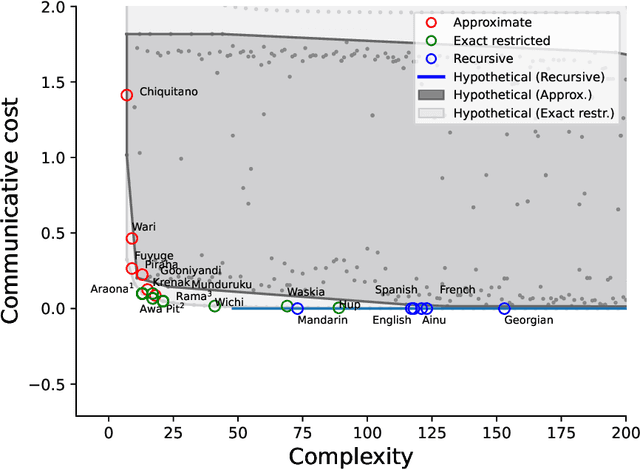

The emergence of mathematical concepts, such as number systems, is an understudied area in AI for mathematics and reasoning. It has previously been shown Carlsson et al. (2021) that by using reinforcement learning (RL), agents can derive simple approximate and exact-restricted numeral systems. However, it is a major challenge to show how more complex recursive numeral systems, similar to the one utilised in English, could arise via a simple learning mechanism such as RL. Here, we introduce an approach towards deriving a mechanistic explanation of the emergence of recursive number systems where we consider an RL agent which directly optimizes a lexicon under a given meta-grammar. Utilising a slightly modified version of the seminal meta-grammar of Hurford (1975), we demonstrate that our RL agent can effectively modify the lexicon towards Pareto-optimal configurations which are comparable to those observed within human numeral systems.
Specify What? Enhancing Neural Specification Synthesis by Symbolic Methods
Jun 21, 2024



We investigate how combinations of Large Language Models (LLMs) and symbolic analyses can be used to synthesise specifications of C programs. The LLM prompts are augmented with outputs from two formal methods tools in the Frama-C ecosystem, Pathcrawler and EVA, to produce C program annotations in the specification language ACSL. We demonstrate how the addition of symbolic analysis to the workflow impacts the quality of annotations: information about input/output examples from Pathcrawler produce more context-aware annotations, while the inclusion of EVA reports yields annotations more attuned to runtime errors. In addition, we show that the method infers rather the programs intent than its behaviour, by generating specifications for buggy programs and observing robustness of the result against bugs.
Can Large Language Models (or Humans) Distill Text?
Mar 25, 2024We investigate the potential of large language models (LLMs) to distill text: to remove the textual traces of an undesired forbidden variable. We employ a range of LLMs with varying architectures and training approaches to distill text by identifying and removing information about the target variable while preserving other relevant signals. Our findings shed light on the strengths and limitations of LLMs in addressing the distillation and provide insights into the strategies for leveraging these models in computational social science investigations involving text data. In particular, we show that in the strong test of removing sentiment, the statistical association between the processed text and sentiment is still clearly detectable to machine learning classifiers post-LLM-distillation. Furthermore, we find that human annotators also struggle to distill sentiment while preserving other semantic content. This suggests there may be limited separability between concept variables in some text contexts, highlighting limitations of methods relying on text-level transformations and also raising questions about the robustness of distillation methods that achieve statistical independence in representation space if this is difficult for human coders operating on raw text to attain.