 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Contextual Runtime Monitors for Safe AI-Based Autonomy
Jan 28, 2026We introduce a novel framework for learning context-aware runtime monitors for AI-based control ensembles. Machine-learning (ML) controllers are increasingly deployed in (autonomous) cyber-physical systems because of their ability to solve complex decision-making tasks. However, their accuracy can degrade sharply in unfamiliar environments, creating significant safety concerns. Traditional ensemble methods aim to improve robustness by averaging or voting across multiple controllers, yet this often dilutes the specialized strengths that individual controllers exhibit in different operating contexts. We argue that, rather than blending controller outputs, a monitoring framework should identify and exploit these contextual strengths. In this paper, we reformulate the design of safe AI-based control ensembles as a contextual monitoring problem. A monitor continuously observes the system's context and selects the controller best suited to the current conditions. To achieve this, we cast monitor learning as a contextual learning task and draw on techniques from contextual multi-armed bandits. Our approach comes with two key benefits: (1) theoretical safety guarantees during controller selection, and (2) improved utilization of controller diversity. We validate our framework in two simulated autonomous driving scenarios, demonstrating significant improvements in both safety and performance compared to non-contextual baselines.
Latent Preference Bandits
Aug 07, 2025Bandit algorithms are guaranteed to solve diverse sequential decision-making problems, provided that a sufficient exploration budget is available. However, learning from scratch is often too costly for personalization tasks where a single individual faces only a small number of decision points. Latent bandits offer substantially reduced exploration times for such problems, given that the joint distribution of a latent state and the rewards of actions is known and accurate. In practice, finding such a model is non-trivial, and there may not exist a small number of latent states that explain the responses of all individuals. For example, patients with similar latent conditions may have the same preference in treatments but rate their symptoms on different scales. With this in mind, we propose relaxing the assumptions of latent bandits to require only a model of the \emph{preference ordering} of actions in each latent state. This allows problem instances with the same latent state to vary in their reward distributions, as long as their preference orderings are equal. We give a posterior-sampling algorithm for this problem and demonstrate that its empirical performance is competitive with latent bandits that have full knowledge of the reward distribution when this is well-specified, and outperforms them when reward scales differ between instances with the same latent state.
Variational Quantum Optimization with Continuous Bandits
Feb 06, 2025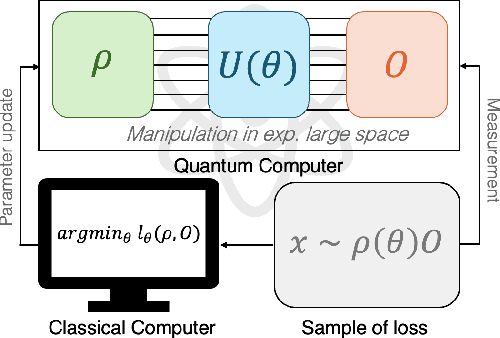
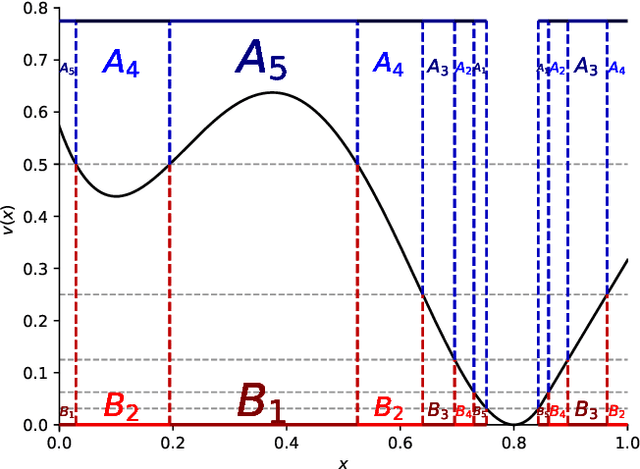
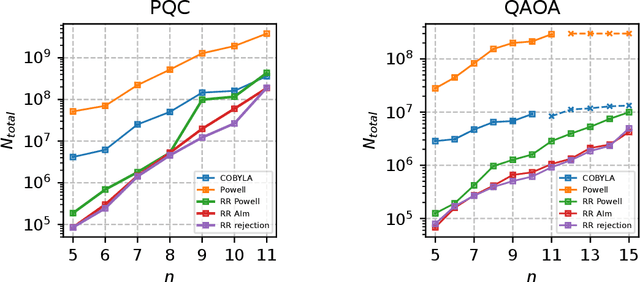
We introduce a novel approach to variational Quantum algorithms (VQA) via continuous bandits. VQA are a class of hybrid Quantum-classical algorithms where the parameters of Quantum circuits are optimized by classical algorithms. Previous work has used zero and first order gradient based methods, however such algorithms suffer from the barren plateau (BP) problem where gradients and loss differences are exponentially small. We introduce an approach using bandits methods which combine global exploration with local exploitation. We show how VQA can be formulated as a best arm identification problem in a continuous space of arms with Lipschitz smoothness. While regret minimization has been addressed in this setting, existing methods for pure exploration only cover discrete spaces. We give the first results for pure exploration in a continuous setting and derive a fixed-confidence, information-theoretic, instance specific lower bound. Under certain assumptions on the expected payoff, we derive a simple algorithm, which is near-optimal with respect to our lower bound. Finally, we apply our continuous bandit algorithm to two VQA schemes: a PQC and a QAOA quantum circuit, showing that we significantly outperform the previously known state of the art methods (which used gradient based methods).
Learning Efficient Recursive Numeral Systems via Reinforcement Learning
Sep 11, 2024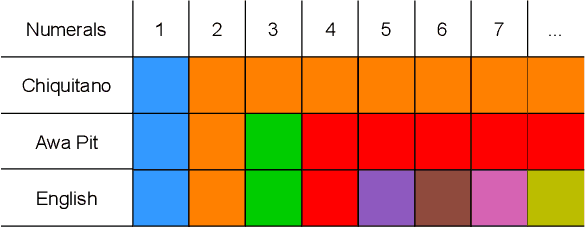

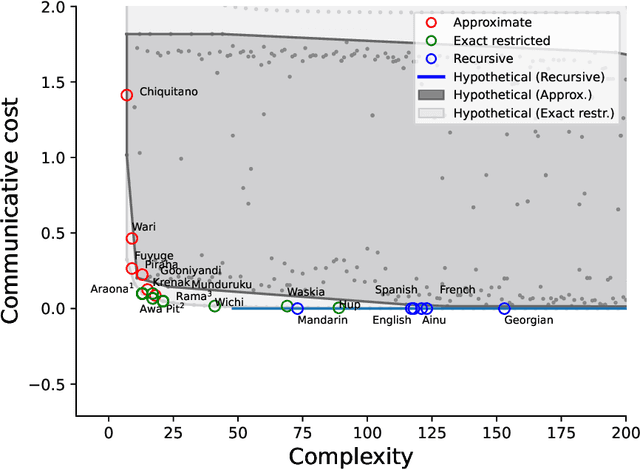

The emergence of mathematical concepts, such as number systems, is an understudied area in AI for mathematics and reasoning. It has previously been shown Carlsson et al. (2021) that by using reinforcement learning (RL), agents can derive simple approximate and exact-restricted numeral systems. However, it is a major challenge to show how more complex recursive numeral systems, similar to the one utilised in English, could arise via a simple learning mechanism such as RL. Here, we introduce an approach towards deriving a mechanistic explanation of the emergence of recursive number systems where we consider an RL agent which directly optimizes a lexicon under a given meta-grammar. Utilising a slightly modified version of the seminal meta-grammar of Hurford (1975), we demonstrate that our RL agent can effectively modify the lexicon towards Pareto-optimal configurations which are comparable to those observed within human numeral systems.
Identifiable latent bandits: Combining observational data and exploration for personalized healthcare
Jul 29, 2024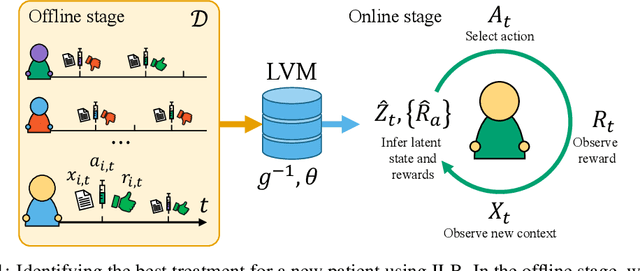
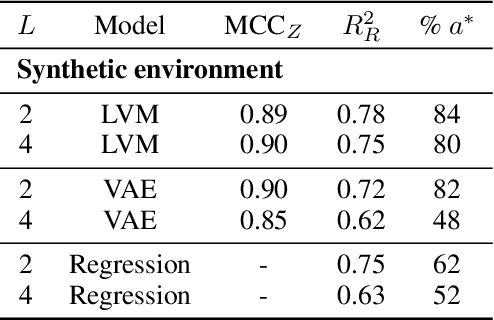
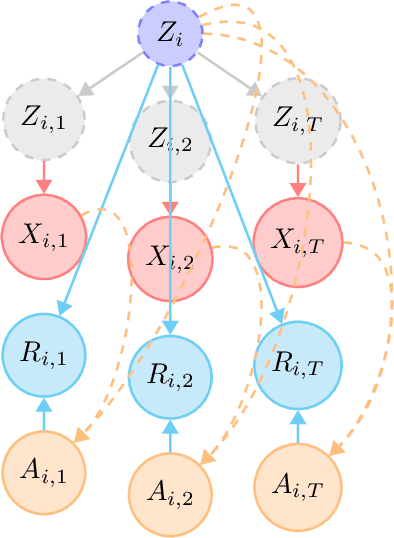

Bandit algorithms hold great promise for improving personalized decision-making but are notoriously sample-hungry. In most health applications, it is infeasible to fit a new bandit for each patient, and observable variables are often insufficient to determine optimal treatments, ruling out applying contextual bandits learned from multiple patients. Latent bandits offer both rapid exploration and personalization beyond what context variables can reveal but require that a latent variable model can be learned consistently. In this work, we propose bandit algorithms based on nonlinear independent component analysis that can be provably identified from observational data to a degree sufficient to infer the optimal action in a new bandit instance consistently. We verify this strategy in simulated data, showing substantial improvement over learning independent multi-armed bandits for every instance.
Active Preference Learning for Ordering Items In- and Out-of-sample
May 05, 2024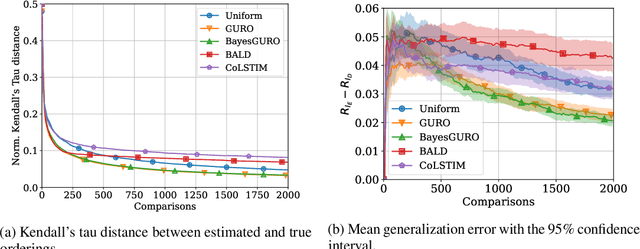

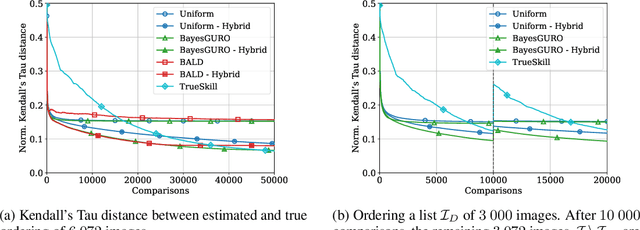

Learning an ordering of items based on noisy pairwise comparisons is useful when item-specific labels are difficult to assign, for example, when annotators have to make subjective assessments. Algorithms have been proposed for actively sampling comparisons of items to minimize the number of annotations necessary for learning an accurate ordering. However, many ignore shared structure between items, treating them as unrelated, limiting sample efficiency and precluding generalization to new items. In this work, we study active learning with pairwise preference feedback for ordering items with contextual attributes, both in- and out-of-sample. We give an upper bound on the expected ordering error incurred by active learning strategies under a logistic preference model, in terms of the aleatoric and epistemic uncertainty in comparisons, and propose two algorithms designed to greedily minimize this bound. We evaluate these algorithms in two realistic image ordering tasks, including one with comparisons made by human annotators, and demonstrate superior sample efficiency compared to non-contextual ranking approaches and active preference learning baselines.
Pure Exploration in Bandits with Linear Constraints
Jun 22, 2023We address the problem of identifying the optimal policy with a fixed confidence level in a multi-armed bandit setup, when \emph{the arms are subject to linear constraints}. Unlike the standard best-arm identification problem which is well studied, the optimal policy in this case may not be deterministic and could mix between several arms. This changes the geometry of the problem which we characterize via an information-theoretic lower bound. We introduce two asymptotically optimal algorithms for this setting, one based on the Track-and-Stop method and the other based on a game-theoretic approach. Both these algorithms try to track an optimal allocation based on the lower bound and computed by a weighted projection onto the boundary of a normal cone. Finally, we provide empirical results that validate our bounds and visualize how constraints change the hardness of the problem.
Pragmatic Reasoning in Structured Signaling Games
May 17, 2023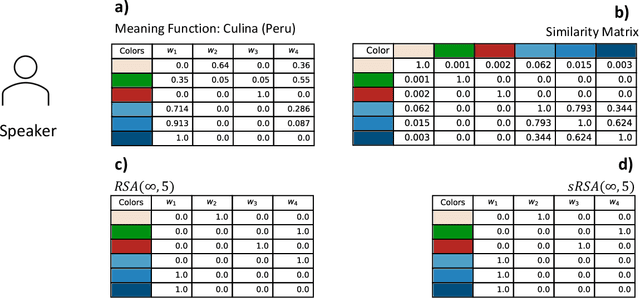
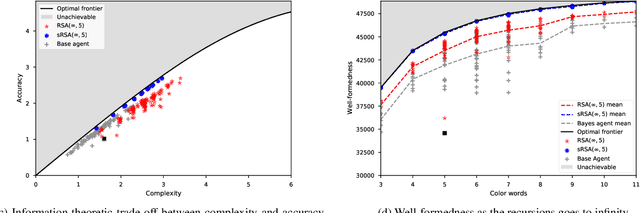
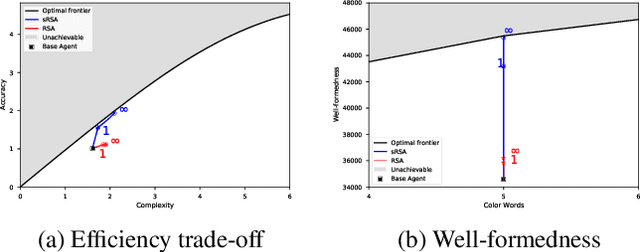
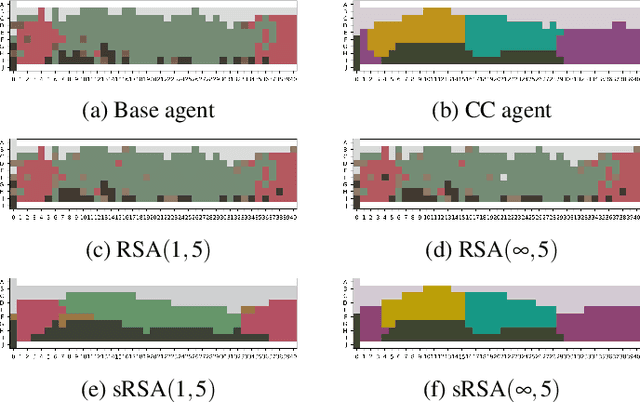
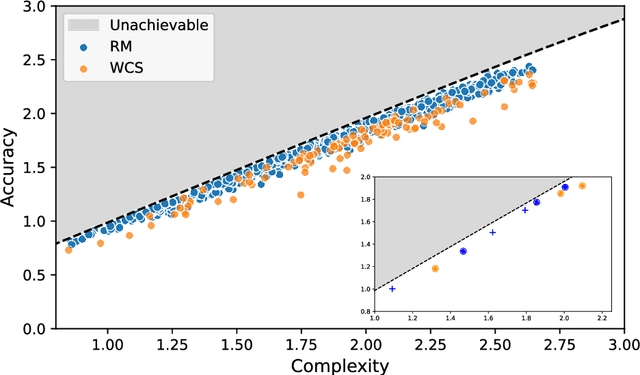
In this work we introduce a structured signaling game, an extension of the classical signaling game with a similarity structure between meanings in the context, along with a variant of the Rational Speech Act (RSA) framework which we call structured-RSA (sRSA) for pragmatic reasoning in structured domains. We explore the behavior of the sRSA in the domain of color and show that pragmatic agents using sRSA on top of semantic representations, derived from the World Color Survey, attain efficiency very close to the information theoretic limit after only 1 or 2 levels of recursion. We also explore the interaction between pragmatic reasoning and learning in multi-agent reinforcement learning framework. Our results illustrate that artificial agents using sRSA develop communication closer to the information theoretic frontier compared to agents using RSA and just reinforcement learning. We also find that the ambiguity of the semantic representation increases as the pragmatic agents are allowed to perform deeper reasoning about each other during learning.
Iterated learning and communication jointly explain efficient color naming systems
May 17, 2023
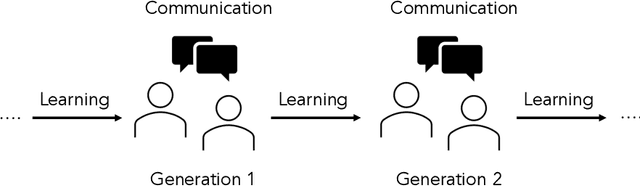
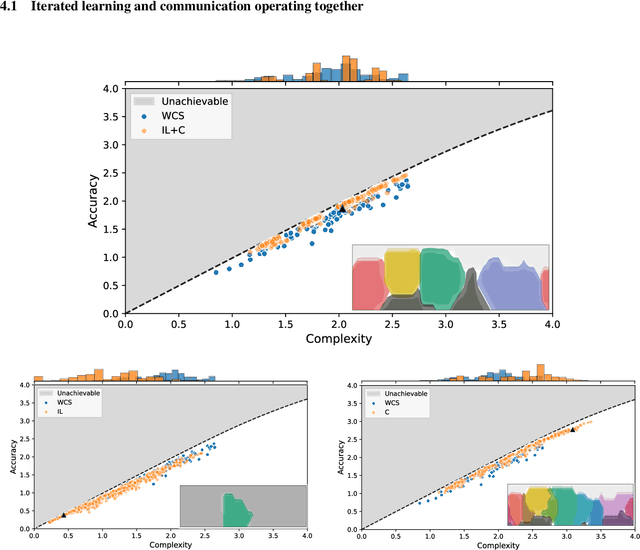
It has been argued that semantic systems reflect pressure for efficiency, and a current debate concerns the cultural evolutionary process that produces this pattern. We consider efficiency as instantiated in the Information Bottleneck (IB) principle, and a model of cultural evolution that combines iterated learning and communication. We show that this model, instantiated in neural networks, converges to color naming systems that are efficient in the IB sense and similar to human color naming systems. We also show that iterated learning alone, and communication alone, do not yield the same outcome as clearly.
Towards Learning Abstractions via Reinforcement Learning
Dec 28, 2022



In this paper we take the first steps in studying a new approach to synthesis of efficient communication schemes in multi-agent systems, trained via reinforcement learning. We combine symbolic methods with machine learning, in what is referred to as a neuro-symbolic system. The agents are not restricted to only use initial primitives: reinforcement learning is interleaved with steps to extend the current language with novel higher-level concepts, allowing generalisation and more informative communication via shorter messages. We demonstrate that this approach allow agents to converge more quickly on a small collaborative construction task.