 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Preference Learning for Ordering Items In- and Out-of-sample
May 05, 2024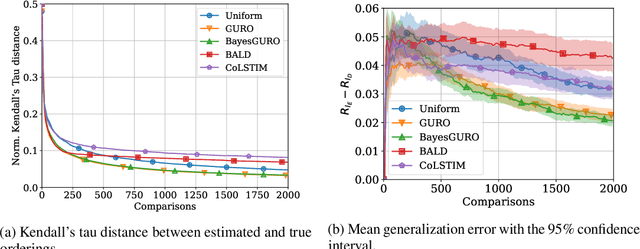

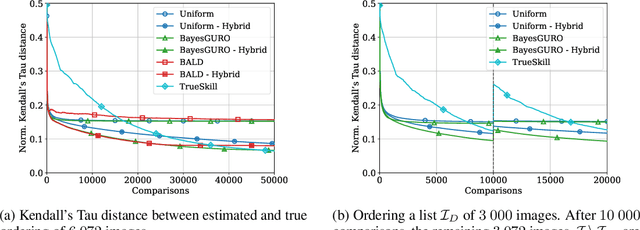

Learning an ordering of items based on noisy pairwise comparisons is useful when item-specific labels are difficult to assign, for example, when annotators have to make subjective assessments. Algorithms have been proposed for actively sampling comparisons of items to minimize the number of annotations necessary for learning an accurate ordering. However, many ignore shared structure between items, treating them as unrelated, limiting sample efficiency and precluding generalization to new items. In this work, we study active learning with pairwise preference feedback for ordering items with contextual attributes, both in- and out-of-sample. We give an upper bound on the expected ordering error incurred by active learning strategies under a logistic preference model, in terms of the aleatoric and epistemic uncertainty in comparisons, and propose two algorithms designed to greedily minimize this bound. We evaluate these algorithms in two realistic image ordering tasks, including one with comparisons made by human annotators, and demonstrate superior sample efficiency compared to non-contextual ranking approaches and active preference learning baselines.