 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashHead: Efficient Drop-In Replacement for the Classification Head in Language Model Inference
Mar 15, 2026Language models are increasingly adopting smaller architectures optimized for consumer devices. In this setting, inference efficiency is the primary constraint. Meanwhile, vocabulary sizes continue to grow rapidly, making the classification head a critical bottleneck that accounts for up to 60\% of model parameters, and 50\% of inference compute. We introduce FlashHead, the first efficient drop-in replacement for the dense classification head that is training-free and hardware-friendly. FlashHead builds on principles from information retrieval, reframing that computation at the output head as a retrieval problem rather than a dense classification over the full vocabulary. FlashHead introduces four key innovations: (1) a balanced clustering scheme that structures vocabulary partitions into compact hardware-efficient tensors, (2) extending multiprobe retrieval to language model heads, enabling thousands of clusters to be scored in parallel, (3) a novel inference-time sampling mechanism that extends retrieval beyond top tokens, enabling probabilistic sampling across the full vocabulary, and (4) selective quantization, enabling effective low-bit computation in the head. Experiments on Llama-3.2, Gemma-3, and Qwen-3 show that FlashHead delivers model-level inference speedups of up to \textbf{1.75x} which maintaining output accuracy compared to the original head. By overcoming the classification head bottleneck, FlashHead establishes a new benchmark for efficient inference and removes a key barrier to developing smaller, capable models for consumer hardware.
Evaluating the relationship between regularity and learnability in recursive numeral systems using Reinforcement Learning
Feb 25, 2026Human recursive numeral systems (i.e., counting systems such as English base-10 numerals), like many other grammatical systems, are highly regular. Following prior work that relates cross-linguistic tendencies to biases in learning, we ask whether regular systems are common because regularity facilitates learning. Adopting methods from the Reinforcement Learning literature, we confirm that highly regular human(-like) systems are easier to learn than unattested but possible irregular systems. This asymmetry emerges under the natural assumption that recursive numeral systems are designed for generalisation from limited data to represent all integers exactly. We also find that the influence of regularity on learnability is absent for unnatural, highly irregular systems, whose learnability is influenced instead by signal length, suggesting that different pressures may influence learnability differently in different parts of the space of possible numeral systems. Our results contribute to the body of work linking learnability to cross-linguistic prevalence.
Learning Contextual Runtime Monitors for Safe AI-Based Autonomy
Jan 28, 2026We introduce a novel framework for learning context-aware runtime monitors for AI-based control ensembles. Machine-learning (ML) controllers are increasingly deployed in (autonomous) cyber-physical systems because of their ability to solve complex decision-making tasks. However, their accuracy can degrade sharply in unfamiliar environments, creating significant safety concerns. Traditional ensemble methods aim to improve robustness by averaging or voting across multiple controllers, yet this often dilutes the specialized strengths that individual controllers exhibit in different operating contexts. We argue that, rather than blending controller outputs, a monitoring framework should identify and exploit these contextual strengths. In this paper, we reformulate the design of safe AI-based control ensembles as a contextual monitoring problem. A monitor continuously observes the system's context and selects the controller best suited to the current conditions. To achieve this, we cast monitor learning as a contextual learning task and draw on techniques from contextual multi-armed bandits. Our approach comes with two key benefits: (1) theoretical safety guarantees during controller selection, and (2) improved utilization of controller diversity. We validate our framework in two simulated autonomous driving scenarios, demonstrating significant improvements in both safety and performance compared to non-contextual baselines.
Recursive numeral systems are highly regular and easy to process
Oct 30, 2025Previous work has argued that recursive numeral systems optimise the trade-off between lexicon size and average morphosyntatic complexity (Deni\'c and Szymanik, 2024). However, showing that only natural-language-like systems optimise this tradeoff has proven elusive, and the existing solution has relied on ad-hoc constraints to rule out unnatural systems (Yang and Regier, 2025). Here, we argue that this issue arises because the proposed trade-off has neglected regularity, a crucial aspect of complexity central to human grammars in general. Drawing on the Minimum Description Length (MDL) approach, we propose that recursive numeral systems are better viewed as efficient with regard to their regularity and processing complexity. We show that our MDL-based measures of regularity and processing complexity better capture the key differences between attested, natural systems and unattested but possible ones, including "optimal" recursive numeral systems from previous work, and that the ad-hoc constraints from previous literature naturally follow from regularity. Our approach highlights the need to incorporate regularity across sets of forms in studies that attempt to measure and explain optimality in language.
Variational Quantum Optimization with Continuous Bandits
Feb 06, 2025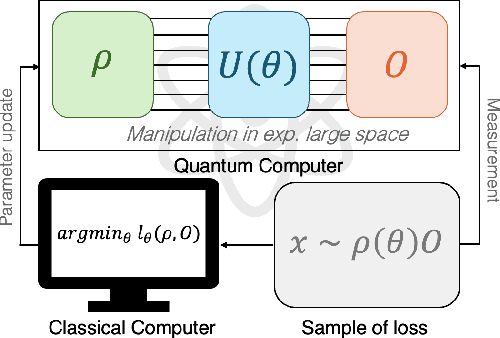
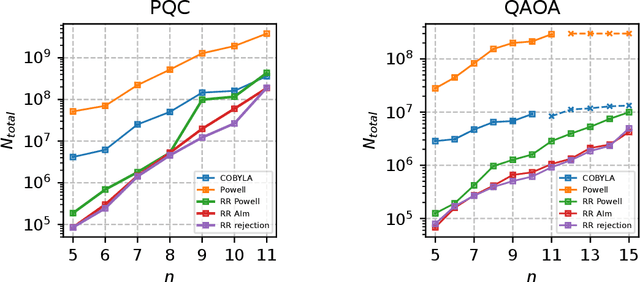
We introduce a novel approach to variational Quantum algorithms (VQA) via continuous bandits. VQA are a class of hybrid Quantum-classical algorithms where the parameters of Quantum circuits are optimized by classical algorithms. Previous work has used zero and first order gradient based methods, however such algorithms suffer from the barren plateau (BP) problem where gradients and loss differences are exponentially small. We introduce an approach using bandits methods which combine global exploration with local exploitation. We show how VQA can be formulated as a best arm identification problem in a continuous space of arms with Lipschitz smoothness. While regret minimization has been addressed in this setting, existing methods for pure exploration only cover discrete spaces. We give the first results for pure exploration in a continuous setting and derive a fixed-confidence, information-theoretic, instance specific lower bound. Under certain assumptions on the expected payoff, we derive a simple algorithm, which is near-optimal with respect to our lower bound. Finally, we apply our continuous bandit algorithm to two VQA schemes: a PQC and a QAOA quantum circuit, showing that we significantly outperform the previously known state of the art methods (which used gradient based methods).
ACE: Abstractions for Communicating Efficiently
Sep 30, 2024A central but unresolved aspect of problem-solving in AI is the capability to introduce and use abstractions, something humans excel at. Work in cognitive science has demonstrated that humans tend towards higher levels of abstraction when engaged in collaborative task-oriented communication, enabling gradually shorter and more information-efficient utterances. Several computational methods have attempted to replicate this phenomenon, but all make unrealistic simplifying assumptions about how abstractions are introduced and learned. Our method, Abstractions for Communicating Efficiently (ACE), overcomes these limitations through a neuro-symbolic approach. On the symbolic side, we draw on work from library learning for proposing abstractions. We combine this with neural methods for communication and reinforcement learning, via a novel use of bandit algorithms for controlling the exploration and exploitation trade-off in introducing new abstractions. ACE exhibits similar tendencies to humans on a collaborative construction task from the cognitive science literature, where one agent (the architect) instructs the other (the builder) to reconstruct a scene of block-buildings. ACE results in the emergence of an efficient language as a by-product of collaborative communication. Beyond providing mechanistic insights into human communication, our work serves as a first step to providing conversational agents with the ability for human-like communicative abstractions.
Learning Efficient Recursive Numeral Systems via Reinforcement Learning
Sep 11, 2024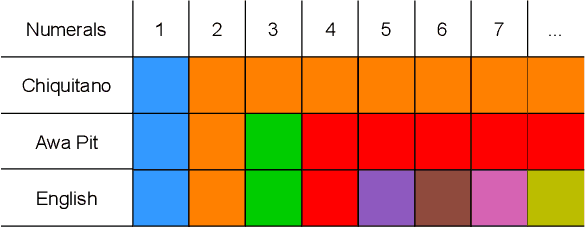

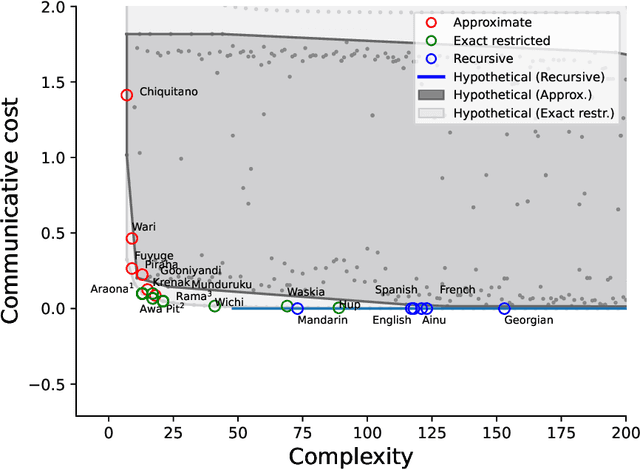

The emergence of mathematical concepts, such as number systems, is an understudied area in AI for mathematics and reasoning. It has previously been shown Carlsson et al. (2021) that by using reinforcement learning (RL), agents can derive simple approximate and exact-restricted numeral systems. However, it is a major challenge to show how more complex recursive numeral systems, similar to the one utilised in English, could arise via a simple learning mechanism such as RL. Here, we introduce an approach towards deriving a mechanistic explanation of the emergence of recursive number systems where we consider an RL agent which directly optimizes a lexicon under a given meta-grammar. Utilising a slightly modified version of the seminal meta-grammar of Hurford (1975), we demonstrate that our RL agent can effectively modify the lexicon towards Pareto-optimal configurations which are comparable to those observed within human numeral systems.
Predicting Ground State Properties: Constant Sample Complexity and Deep Learning Algorithms
May 28, 2024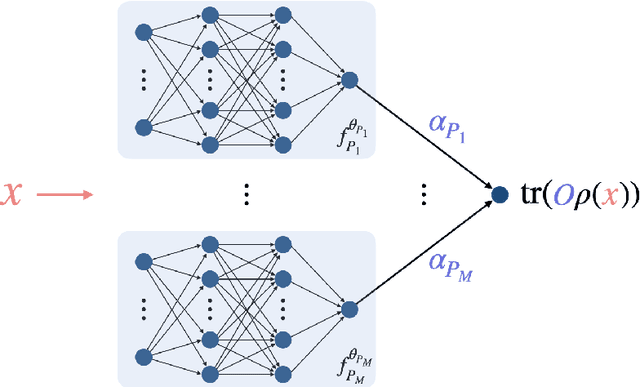
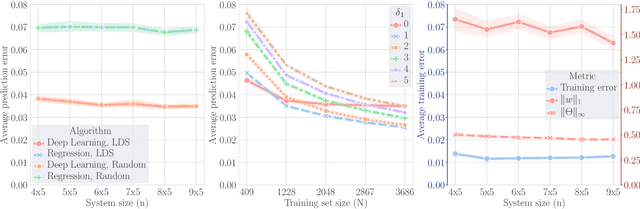
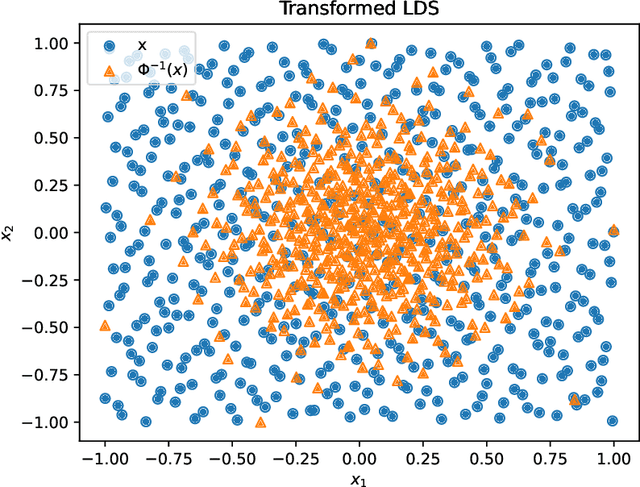
A fundamental problem in quantum many-body physics is that of finding ground states of local Hamiltonians. A number of recent works gave provably efficient machine learning (ML) algorithms for learning ground states. Specifically, [Huang et al. Science 2022], introduced an approach for learning properties of the ground state of an $n$-qubit gapped local Hamiltonian $H$ from only $n^{\mathcal{O}(1)}$ data points sampled from Hamiltonians in the same phase of matter. This was subsequently improved by [Lewis et al. Nature Communications 2024], to $\mathcal{O}(\log n)$ samples when the geometry of the $n$-qubit system is known. In this work, we introduce two approaches that achieve a constant sample complexity, independent of system size $n$, for learning ground state properties. Our first algorithm consists of a simple modification of the ML model used by Lewis et al. and applies to a property of interest known beforehand. Our second algorithm, which applies even if a description of the property is not known, is a deep neural network model. While empirical results showing the performance of neural networks have been demonstrated, to our knowledge, this is the first rigorous sample complexity bound on a neural network model for predicting ground state properties. We also perform numerical experiments that confirm the improved scaling of our approach compared to earlier results.
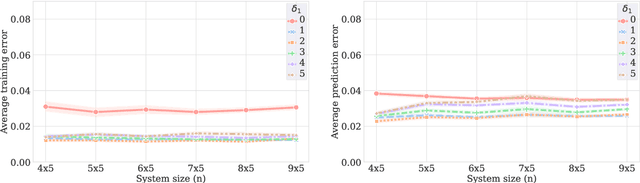
Active Preference Learning for Ordering Items In- and Out-of-sample
May 05, 2024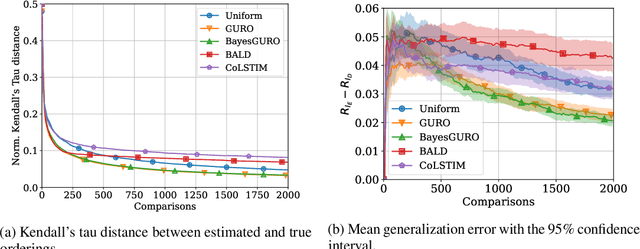

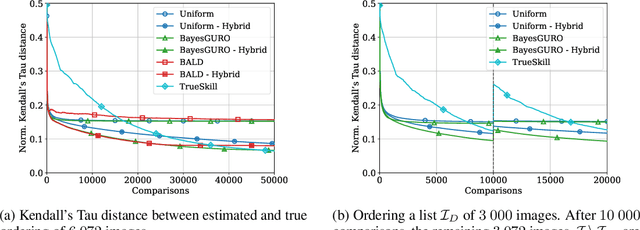

Learning an ordering of items based on noisy pairwise comparisons is useful when item-specific labels are difficult to assign, for example, when annotators have to make subjective assessments. Algorithms have been proposed for actively sampling comparisons of items to minimize the number of annotations necessary for learning an accurate ordering. However, many ignore shared structure between items, treating them as unrelated, limiting sample efficiency and precluding generalization to new items. In this work, we study active learning with pairwise preference feedback for ordering items with contextual attributes, both in- and out-of-sample. We give an upper bound on the expected ordering error incurred by active learning strategies under a logistic preference model, in terms of the aleatoric and epistemic uncertainty in comparisons, and propose two algorithms designed to greedily minimize this bound. We evaluate these algorithms in two realistic image ordering tasks, including one with comparisons made by human annotators, and demonstrate superior sample efficiency compared to non-contextual ranking approaches and active preference learning baselines.
Pure Exploration in Bandits with Linear Constraints
Jun 22, 2023We address the problem of identifying the optimal policy with a fixed confidence level in a multi-armed bandit setup, when \emph{the arms are subject to linear constraints}. Unlike the standard best-arm identification problem which is well studied, the optimal policy in this case may not be deterministic and could mix between several arms. This changes the geometry of the problem which we characterize via an information-theoretic lower bound. We introduce two asymptotically optimal algorithms for this setting, one based on the Track-and-Stop method and the other based on a game-theoretic approach. Both these algorithms try to track an optimal allocation based on the lower bound and computed by a weighted projection onto the boundary of a normal cone. Finally, we provide empirical results that validate our bounds and visualize how constraints change the hardness of the problem.