 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Heterogeneous and Private Label Sets
Aug 26, 2025Although common in real-world applications, heterogeneous client label sets are rarely investigated in federated learning (FL). Furthermore, in the cases they are, clients are assumed to be willing to share their entire label sets with other clients. Federated learning with private label sets, shared only with the central server, adds further constraints on learning algorithms and is, in general, a more difficult problem to solve. In this work, we study the effects of label set heterogeneity on model performance, comparing the public and private label settings -- when the union of label sets in the federation is known to clients and when it is not. We apply classical methods for the classifier combination problem to FL using centralized tuning, adapt common FL methods to the private label set setting, and discuss the justification of both approaches under practical assumptions. Our experiments show that reducing the number of labels available to each client harms the performance of all methods substantially. Centralized tuning of client models for representational alignment can help remedy this, but often at the cost of higher variance. Throughout, our proposed adaptations of standard FL methods perform well, showing similar performance in the private label setting as the standard methods achieve in the public setting. This shows that clients can enjoy increased privacy at little cost to model accuracy.
Latent Preference Bandits
Aug 07, 2025Bandit algorithms are guaranteed to solve diverse sequential decision-making problems, provided that a sufficient exploration budget is available. However, learning from scratch is often too costly for personalization tasks where a single individual faces only a small number of decision points. Latent bandits offer substantially reduced exploration times for such problems, given that the joint distribution of a latent state and the rewards of actions is known and accurate. In practice, finding such a model is non-trivial, and there may not exist a small number of latent states that explain the responses of all individuals. For example, patients with similar latent conditions may have the same preference in treatments but rate their symptoms on different scales. With this in mind, we propose relaxing the assumptions of latent bandits to require only a model of the \emph{preference ordering} of actions in each latent state. This allows problem instances with the same latent state to vary in their reward distributions, as long as their preference orderings are equal. We give a posterior-sampling algorithm for this problem and demonstrate that its empirical performance is competitive with latent bandits that have full knowledge of the reward distribution when this is well-specified, and outperforms them when reward scales differ between instances with the same latent state.
Pragmatic Policy Development via Interpretable Behavior Cloning
Jul 22, 2025Offline reinforcement learning (RL) holds great promise for deriving optimal policies from observational data, but challenges related to interpretability and evaluation limit its practical use in safety-critical domains. Interpretability is hindered by the black-box nature of unconstrained RL policies, while evaluation -- typically performed off-policy -- is sensitive to large deviations from the data-collecting behavior policy, especially when using methods based on importance sampling. To address these challenges, we propose a simple yet practical alternative: deriving treatment policies from the most frequently chosen actions in each patient state, as estimated by an interpretable model of the behavior policy. By using a tree-based model, which is specifically designed to exploit patterns in the data, we obtain a natural grouping of states with respect to treatment. The tree structure ensures interpretability by design, while varying the number of actions considered controls the degree of overlap with the behavior policy, enabling reliable off-policy evaluation. This pragmatic approach to policy development standardizes frequent treatment patterns, capturing the collective clinical judgment embedded in the data. Using real-world examples in rheumatoid arthritis and sepsis care, we demonstrate that policies derived under this framework can outperform current practice, offering interpretable alternatives to those obtained via offline RL.
Prediction Models That Learn to Avoid Missing Values
May 06, 2025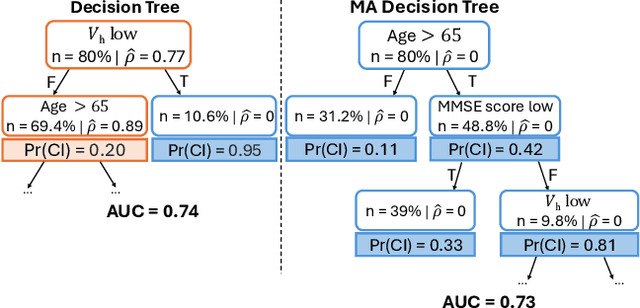
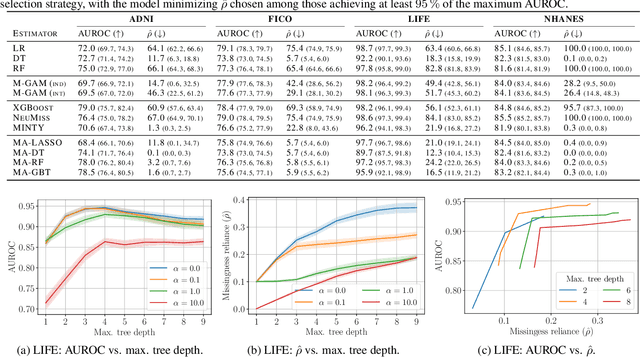
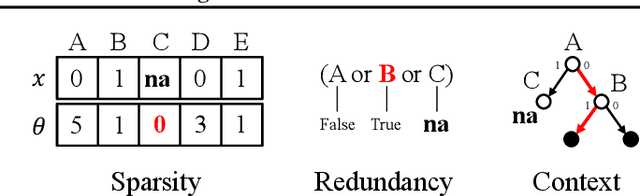

Handling missing values at test time is challenging for machine learning models, especially when aiming for both high accuracy and interpretability. Established approaches often add bias through imputation or excessive model complexity via missingness indicators. Moreover, either method can obscure interpretability, making it harder to understand how the model utilizes the observed variables in predictions. We propose missingness-avoiding (MA) machine learning, a general framework for training models to rarely require the values of missing (or imputed) features at test time. We create tailored MA learning algorithms for decision trees, tree ensembles, and sparse linear models by incorporating classifier-specific regularization terms in their learning objectives. The tree-based models leverage contextual missingness by reducing reliance on missing values based on the observed context. Experiments on real-world datasets demonstrate that MA-DT, MA-LASSO, MA-RF, and MA-GBT effectively reduce the reliance on features with missing values while maintaining predictive performance competitive with their unregularized counterparts. This shows that our framework gives practitioners a powerful tool to maintain interpretability in predictions with test-time missing values.
How Should We Represent History in Interpretable Models of Clinical Policies?
Dec 10, 2024



Modeling policies for sequential clinical decision-making based on observational data is useful for describing treatment practices, standardizing frequent patterns in treatment, and evaluating alternative policies. For each task, it is essential that the policy model is interpretable. Learning accurate models requires effectively capturing the state of a patient, either through sequence representation learning or carefully crafted summaries of their medical history. While recent work has favored the former, it remains a question as to how histories should best be represented for interpretable policy modeling. Focused on model fit, we systematically compare diverse approaches to summarizing patient history for interpretable modeling of clinical policies across four sequential decision-making tasks. We illustrate differences in the policies learned using various representations by breaking down evaluations by patient subgroups, critical states, and stages of treatment, highlighting challenges specific to common use cases. We find that interpretable sequence models using learned representations perform on par with black-box models across all tasks. Interpretable models using hand-crafted representations perform substantially worse when ignoring history entirely, but are made competitive by incorporating only a few aggregated and recent elements of patient history. The added benefits of using a richer representation are pronounced for subgroups and in specific use cases. This underscores the importance of evaluating policy models in the context of their intended use.
Expert Study on Interpretable Machine Learning Models with Missing Data
Nov 14, 2024



Inherently interpretable machine learning (IML) models provide valuable insights for clinical decision-making but face challenges when features have missing values. Classical solutions like imputation or excluding incomplete records are often unsuitable in applications where values are missing at test time. In this work, we conducted a survey with 71 clinicians from 29 trauma centers across France, including 20 complete responses to study the interaction between medical professionals and IML applied to data with missing values. This provided valuable insights into how missing data is interpreted in clinical machine learning. We used the prediction of hemorrhagic shock as a concrete example to gauge the willingness and readiness of the participants to adopt IML models from three classes of methods. Our findings show that, while clinicians value interpretability and are familiar with common IML methods, classical imputation techniques often misalign with their intuition, and that models that natively handle missing values are preferred. These results emphasize the need to integrate clinical intuition into future IML models for better human-computer interaction.
Overcoming label shift in targeted federated learning
Nov 06, 2024



Federated learning enables multiple actors to collaboratively train models without sharing private data. This unlocks the potential for scaling machine learning to diverse applications. Existing algorithms for this task are well-justified when clients and the intended target domain share the same distribution of features and labels, but this assumption is often violated in real-world scenarios. One common violation is label shift, where the label distributions differ across clients or between clients and the target domain, which can significantly degrade model performance. To address this problem, we propose FedPALS, a novel model aggregation scheme that adapts to label shifts by leveraging knowledge of the target label distribution at the central server. Our approach ensures unbiased updates under stochastic gradient descent, ensuring robust generalization across clients with diverse, label-shifted data. Extensive experiments on image classification demonstrate that FedPALS consistently outperforms standard baselines by aligning model aggregation with the target domain. Our findings reveal that conventional federated learning methods suffer severely in cases of extreme client sparsity, highlighting the critical need for target-aware aggregation. FedPALS offers a principled and practical solution to mitigate label distribution mismatch, ensuring models trained in federated settings can generalize effectively to label-shifted target domains.
Identifiable latent bandits: Combining observational data and exploration for personalized healthcare
Jul 29, 2024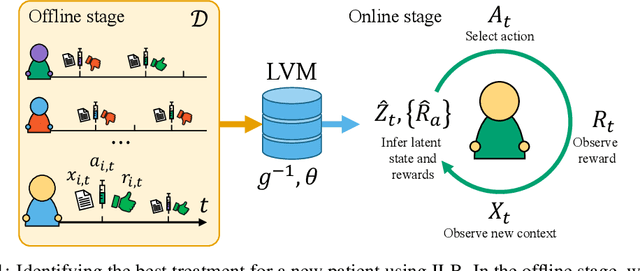
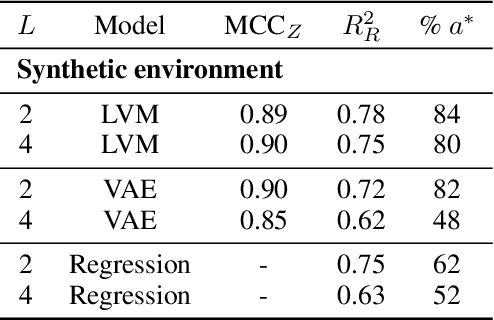
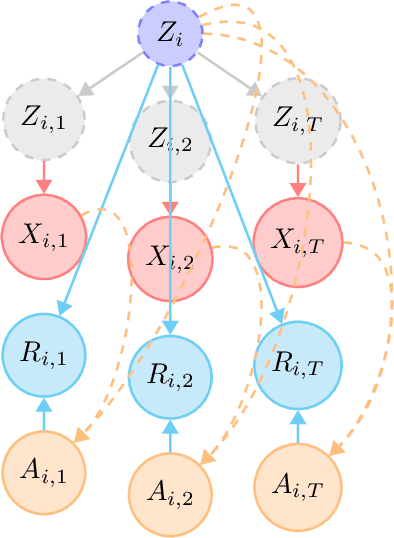

Bandit algorithms hold great promise for improving personalized decision-making but are notoriously sample-hungry. In most health applications, it is infeasible to fit a new bandit for each patient, and observable variables are often insufficient to determine optimal treatments, ruling out applying contextual bandits learned from multiple patients. Latent bandits offer both rapid exploration and personalization beyond what context variables can reveal but require that a latent variable model can be learned consistently. In this work, we propose bandit algorithms based on nonlinear independent component analysis that can be provably identified from observational data to a degree sufficient to infer the optimal action in a new bandit instance consistently. We verify this strategy in simulated data, showing substantial improvement over learning independent multi-armed bandits for every instance.
IncomeSCM: From tabular data set to time-series simulator and causal estimation benchmark
May 25, 2024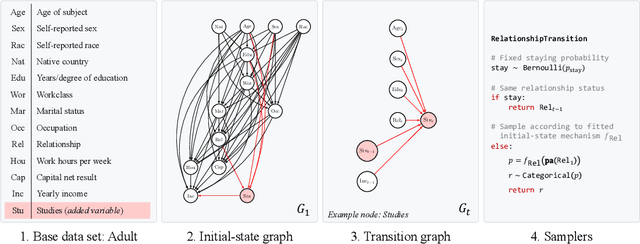
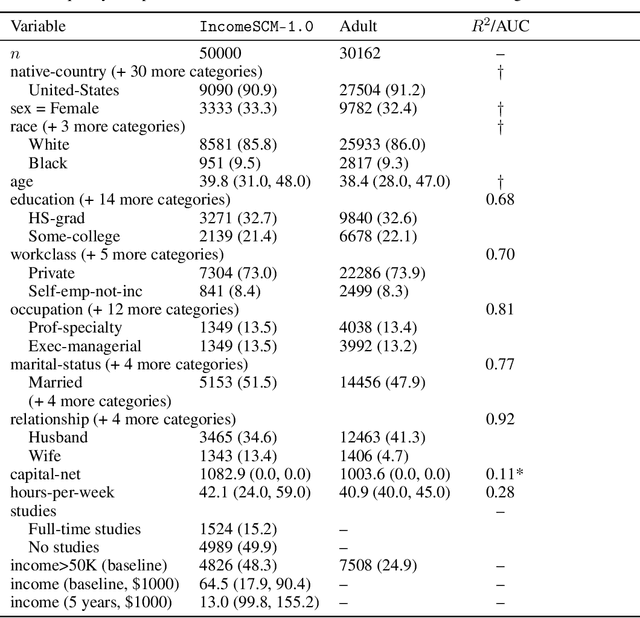
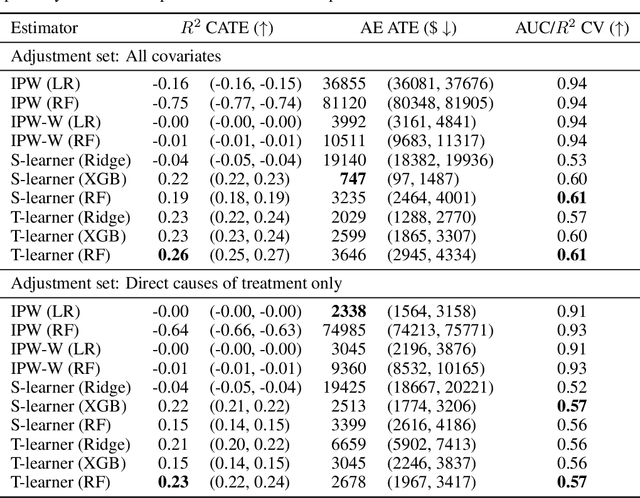
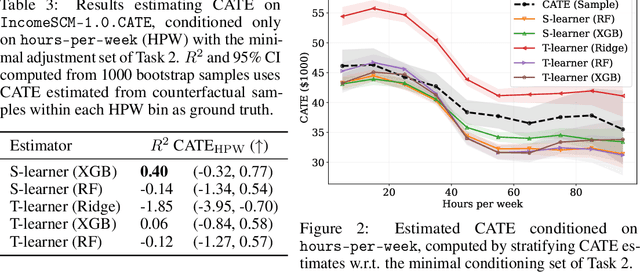
Evaluating observational estimators of causal effects demands information that is rarely available: unconfounded interventions and outcomes from the population of interest, created either by randomization or adjustment. As a result, it is customary to fall back on simulators when creating benchmark tasks. Simulators offer great control but are often too simplistic to make challenging tasks, either because they are hand-designed and lack the nuances of real-world data, or because they are fit to observational data without structural constraints. In this work, we propose a general, repeatable strategy for turning observational data into sequential structural causal models and challenging estimation tasks by following two simple principles: 1) fitting real-world data where possible, and 2) creating complexity by composing simple, hand-designed mechanisms. We implement these ideas in a highly configurable software package and apply it to the well-known Adult income data set to construct the IncomeSCM simulator. From this, we devise multiple estimation tasks and sample data sets to compare established estimators of causal effects. The tasks present a suitable challenge, with effect estimates varying greatly in quality between methods, despite similar performance in the modeling of factual outcomes, highlighting the need for dedicated causal estimators and model selection criteria.
Active Preference Learning for Ordering Items In- and Out-of-sample
May 05, 2024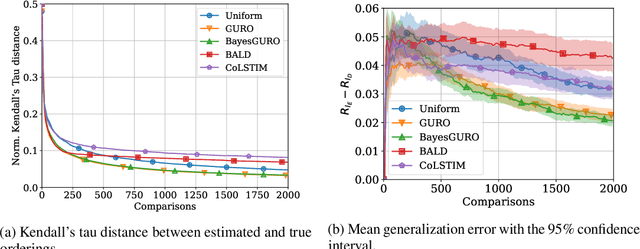

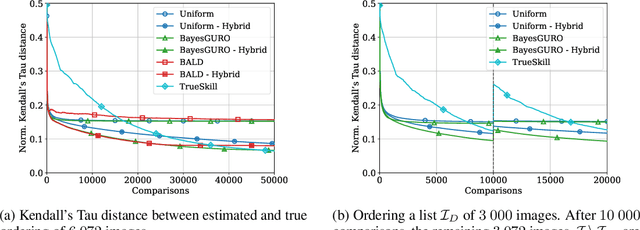

Learning an ordering of items based on noisy pairwise comparisons is useful when item-specific labels are difficult to assign, for example, when annotators have to make subjective assessments. Algorithms have been proposed for actively sampling comparisons of items to minimize the number of annotations necessary for learning an accurate ordering. However, many ignore shared structure between items, treating them as unrelated, limiting sample efficiency and precluding generalization to new items. In this work, we study active learning with pairwise preference feedback for ordering items with contextual attributes, both in- and out-of-sample. We give an upper bound on the expected ordering error incurred by active learning strategies under a logistic preference model, in terms of the aleatoric and epistemic uncertainty in comparisons, and propose two algorithms designed to greedily minimize this bound. We evaluate these algorithms in two realistic image ordering tasks, including one with comparisons made by human annotators, and demonstrate superior sample efficiency compared to non-contextual ranking approaches and active preference learning baselines.