 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePragmatic Policy Development via Interpretable Behavior Cloning
Jul 22, 2025Offline reinforcement learning (RL) holds great promise for deriving optimal policies from observational data, but challenges related to interpretability and evaluation limit its practical use in safety-critical domains. Interpretability is hindered by the black-box nature of unconstrained RL policies, while evaluation -- typically performed off-policy -- is sensitive to large deviations from the data-collecting behavior policy, especially when using methods based on importance sampling. To address these challenges, we propose a simple yet practical alternative: deriving treatment policies from the most frequently chosen actions in each patient state, as estimated by an interpretable model of the behavior policy. By using a tree-based model, which is specifically designed to exploit patterns in the data, we obtain a natural grouping of states with respect to treatment. The tree structure ensures interpretability by design, while varying the number of actions considered controls the degree of overlap with the behavior policy, enabling reliable off-policy evaluation. This pragmatic approach to policy development standardizes frequent treatment patterns, capturing the collective clinical judgment embedded in the data. Using real-world examples in rheumatoid arthritis and sepsis care, we demonstrate that policies derived under this framework can outperform current practice, offering interpretable alternatives to those obtained via offline RL.
Prediction Models That Learn to Avoid Missing Values
May 06, 2025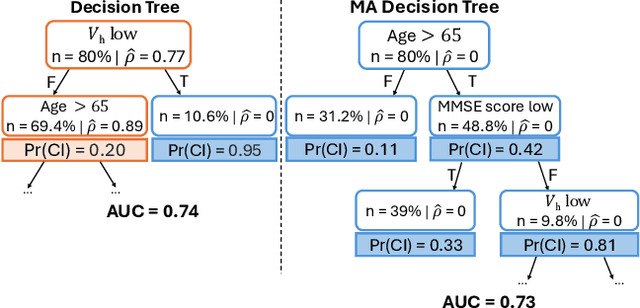
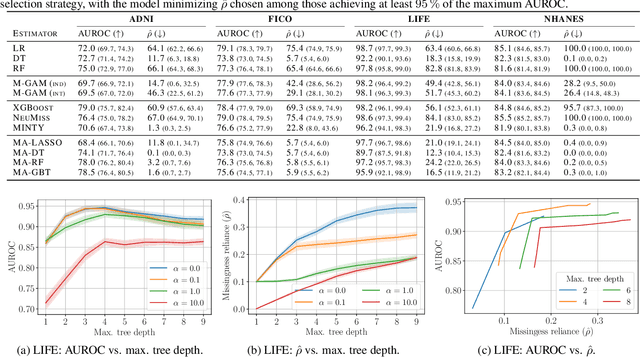
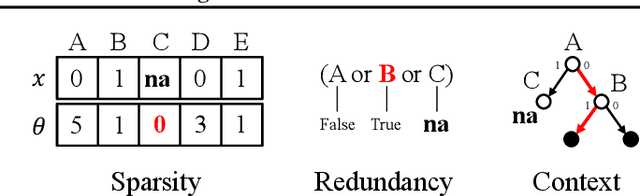

Handling missing values at test time is challenging for machine learning models, especially when aiming for both high accuracy and interpretability. Established approaches often add bias through imputation or excessive model complexity via missingness indicators. Moreover, either method can obscure interpretability, making it harder to understand how the model utilizes the observed variables in predictions. We propose missingness-avoiding (MA) machine learning, a general framework for training models to rarely require the values of missing (or imputed) features at test time. We create tailored MA learning algorithms for decision trees, tree ensembles, and sparse linear models by incorporating classifier-specific regularization terms in their learning objectives. The tree-based models leverage contextual missingness by reducing reliance on missing values based on the observed context. Experiments on real-world datasets demonstrate that MA-DT, MA-LASSO, MA-RF, and MA-GBT effectively reduce the reliance on features with missing values while maintaining predictive performance competitive with their unregularized counterparts. This shows that our framework gives practitioners a powerful tool to maintain interpretability in predictions with test-time missing values.
How Should We Represent History in Interpretable Models of Clinical Policies?
Dec 10, 2024



Modeling policies for sequential clinical decision-making based on observational data is useful for describing treatment practices, standardizing frequent patterns in treatment, and evaluating alternative policies. For each task, it is essential that the policy model is interpretable. Learning accurate models requires effectively capturing the state of a patient, either through sequence representation learning or carefully crafted summaries of their medical history. While recent work has favored the former, it remains a question as to how histories should best be represented for interpretable policy modeling. Focused on model fit, we systematically compare diverse approaches to summarizing patient history for interpretable modeling of clinical policies across four sequential decision-making tasks. We illustrate differences in the policies learned using various representations by breaking down evaluations by patient subgroups, critical states, and stages of treatment, highlighting challenges specific to common use cases. We find that interpretable sequence models using learned representations perform on par with black-box models across all tasks. Interpretable models using hand-crafted representations perform substantially worse when ignoring history entirely, but are made competitive by incorporating only a few aggregated and recent elements of patient history. The added benefits of using a richer representation are pronounced for subgroups and in specific use cases. This underscores the importance of evaluating policy models in the context of their intended use.
Unsupervised domain adaptation by learning using privileged information
Mar 17, 2023



Successful unsupervised domain adaptation (UDA) is guaranteed only under strong assumptions such as covariate shift and overlap between input domains. The latter is often violated in high-dimensional applications such as image classification which, despite this challenge, continues to serve as inspiration and benchmark for algorithm development. In this work, we show that access to side information about examples from the source and target domains can help relax these assumptions and increase sample efficiency in learning, at the cost of collecting a richer variable set. We call this domain adaptation by learning using privileged information (DALUPI). Tailored for this task, we propose a simple two-stage learning algorithm inspired by our analysis and a practical end-to-end algorithm for multi-label image classification. In a suite of experiments, including an application to medical image analysis, we demonstrate that incorporating privileged information in learning can reduce errors in domain transfer compared to classical learning.
Case-based off-policy policy evaluation using prototype learning
Nov 22, 2021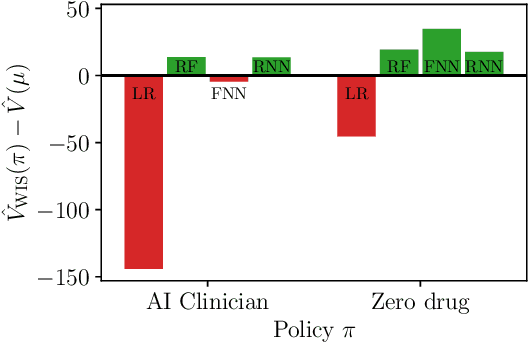
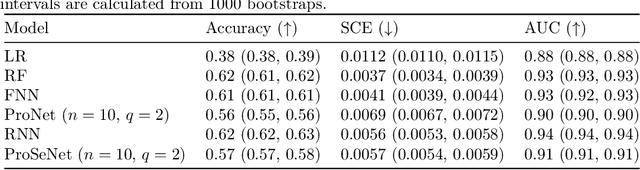
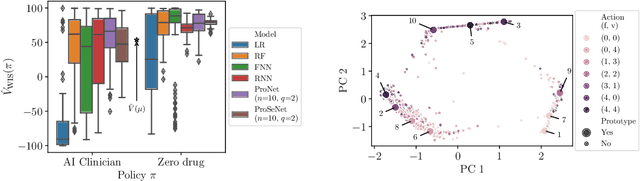
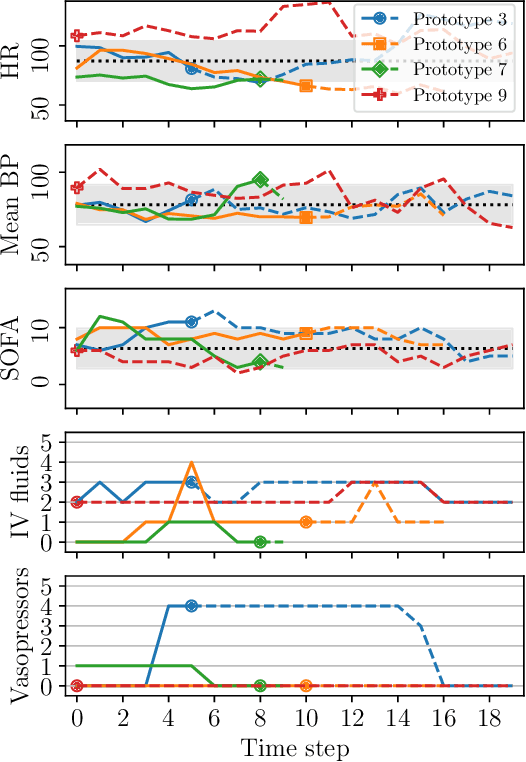
Importance sampling (IS) is often used to perform off-policy policy evaluation but is prone to several issues, especially when the behavior policy is unknown and must be estimated from data. Significant differences between the target and behavior policies can result in uncertain value estimates due to, for example, high variance and non-evaluated actions. If the behavior policy is estimated using black-box models, it can be hard to diagnose potential problems and to determine for which inputs the policies differ in their suggested actions and resulting values. To address this, we propose estimating the behavior policy for IS using prototype learning. We apply this approach in the evaluation of policies for sepsis treatment, demonstrating how the prototypes give a condensed summary of differences between the target and behavior policies while retaining an accuracy comparable to baseline estimators. We also describe estimated values in terms of the prototypes to better understand which parts of the target policies have the most impact on the estimates. Using a simulator, we study the bias resulting from restricting models to use prototypes.