 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting and Mitigating Treatment Leakage in Text-Based Causal Inference: Distillation and Sensitivity Analysis
Dec 30, 2025Text-based causal inference increasingly employs textual data as proxies for unobserved confounders, yet this approach introduces a previously undertheorized source of bias: treatment leakage. Treatment leakage occurs when text intended to capture confounding information also contains signals predictive of treatment status, thereby inducing post-treatment bias in causal estimates. Critically, this problem can arise even when documents precede treatment assignment, as authors may employ future-referencing language that anticipates subsequent interventions. Despite growing recognition of this issue, no systematic methods exist for identifying and mitigating treatment leakage in text-as-confounder applications. This paper addresses this gap through three contributions. First, we provide formal statistical and set-theoretic definitions of treatment leakage that clarify when and why bias occurs. Second, we propose four text distillation methods -- similarity-based passage removal, distant supervision classification, salient feature removal, and iterative nullspace projection -- designed to eliminate treatment-predictive content while preserving confounder information. Third, we validate these methods through simulations using synthetic text and an empirical application examining International Monetary Fund structural adjustment programs and child mortality. Our findings indicate that moderate distillation optimally balances bias reduction against confounder retention, whereas overly stringent approaches degrade estimate precision.
Beyond Interaction Effects: Two Logics for Studying Population Inequalities
Dec 26, 2025When sociologists and other social scientist ask whether the return to college differs by race and gender, they face a choice between two fundamentally different modes of inquiry. Traditional interaction models follow deductive logic: the researcher specifies which variables moderate effects and tests these hypotheses. Machine learning methods follow inductive logic: algorithms search across vast combinatorial spaces to discover patterns of heterogeneity. This article develops a framework for navigating between these approaches. We show that the choice between deduction and induction reflects a tradeoff between interpretability and flexibility, and we demonstrate through simulation when each approach excels. Our framework is particularly relevant for inequality research, where understanding how treatment effects vary across intersecting social subpopulation is substantively central.
Sensitivity Analysis to Unobserved Confounding with Copula-based Normalizing Flows
Aug 12, 2025We propose a novel method for sensitivity analysis to unobserved confounding in causal inference. The method builds on a copula-based causal graphical normalizing flow that we term $\rho$-GNF, where $\rho \in [-1,+1]$ is the sensitivity parameter. The parameter represents the non-causal association between exposure and outcome due to unobserved confounding, which is modeled as a Gaussian copula. In other words, the $\rho$-GNF enables scholars to estimate the average causal effect (ACE) as a function of $\rho$, accounting for various confounding strengths. The output of the $\rho$-GNF is what we term the $\rho_{curve}$, which provides the bounds for the ACE given an interval of assumed $\rho$ values. The $\rho_{curve}$ also enables scholars to identify the confounding strength required to nullify the ACE. We also propose a Bayesian version of our sensitivity analysis method. Assuming a prior over the sensitivity parameter $\rho$ enables us to derive the posterior distribution over the ACE, which enables us to derive credible intervals. Finally, leveraging on experiments from simulated and real-world data, we show the benefits of our sensitivity analysis method.
Benchmarking Debiasing Methods for LLM-based Parameter Estimates
Jun 11, 2025Large language models (LLMs) offer an inexpensive yet powerful way to annotate text, but are often inconsistent when compared with experts. These errors can bias downstream estimates of population parameters such as regression coefficients and causal effects. To mitigate this bias, researchers have developed debiasing methods such as Design-based Supervised Learning (DSL) and Prediction-Powered Inference (PPI), which promise valid estimation by combining LLM annotations with a limited number of expensive expert annotations. Although these methods produce consistent estimates under theoretical assumptions, it is unknown how they compare in finite samples of sizes encountered in applied research. We make two contributions: First, we study how each method's performance scales with the number of expert annotations, highlighting regimes where LLM bias or limited expert labels significantly affect results. Second, we compare DSL and PPI across a range of tasks, finding that although both achieve low bias with large datasets, DSL often outperforms PPI on bias reduction and empirical efficiency, but its performance is less consistent across datasets. Our findings indicate that there is a bias-variance tradeoff at the level of debiasing methods, calling for more research on developing metrics for quantifying their efficiency in finite samples.
Analyzing Poverty through Intra-Annual Time-Series: A Wavelet Transform Approach
Nov 05, 2024
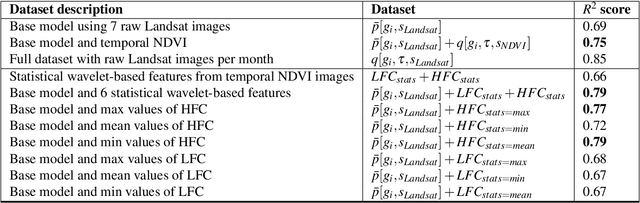
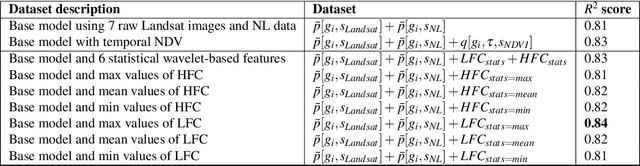
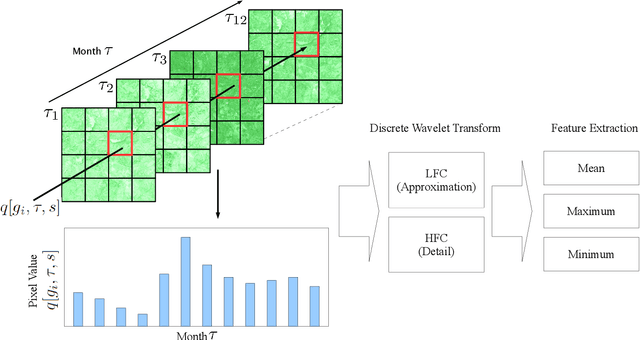
Reducing global poverty is a key objective of the Sustainable Development Goals (SDGs). Achieving this requires high-frequency, granular data to capture neighborhood-level changes, particularly in data scarce regions such as low- and middle-income countries. To fill in the data gaps, recent computer vision methods combining machine learning (ML) with earth observation (EO) data to improve poverty estimation. However, while much progress have been made, they often omit intra-annual variations, which are crucial for estimating poverty in agriculturally dependent countries. We explored the impact of integrating intra-annual NDVI information with annual multi-spectral data on model accuracy. To evaluate our method, we created a simulated dataset using Landsat imagery and nighttime light data to evaluate EO-ML methods that use intra-annual EO data. Additionally, we evaluated our method against the Demographic and Health Survey (DHS) dataset across Africa. Our results indicate that integrating specific NDVI-derived features with multi-spectral data provides valuable insights for poverty analysis, emphasizing the importance of retaining intra-annual information.
Mapping Africa Settlements: High Resolution Urban and Rural Map by Deep Learning and Satellite Imagery
Nov 05, 2024Accurate Land Use and Land Cover (LULC) maps are essential for understanding the drivers of sustainable development, in terms of its complex interrelationships between human activities and natural resources. However, existing LULC maps often lack precise urban and rural classifications, particularly in diverse regions like Africa. This study presents a novel construction of a high-resolution rural-urban map using deep learning techniques and satellite imagery. We developed a deep learning model based on the DeepLabV3 architecture, which was trained on satellite imagery from Landsat-8 and the ESRI LULC dataset, augmented with human settlement data from the GHS-SMOD. The model utilizes semantic segmentation to classify land into detailed categories, including urban and rural areas, at a 10-meter resolution. Our findings demonstrate that incorporating LULC along with urban and rural classifications significantly enhances the model's ability to accurately distinguish between urban, rural, and non-human settlement areas. Therefore, our maps can support more informed decision-making for policymakers, researchers, and stakeholders. We release a continent wide urban-rural map, covering the period 2016 and 2022.
Encoding Multi-level Dynamics in Effect Heterogeneity Estimation
Nov 04, 2024


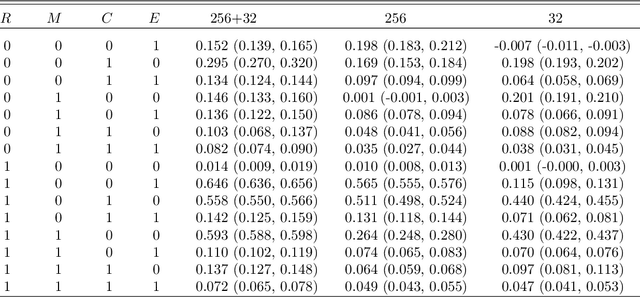
Earth Observation (EO) data are increasingly used in policy analysis by enabling granular estimation of treatment effects. However, a challenge in EO-based causal inference lies in balancing the trade-off between capturing fine-grained individual heterogeneity and broader contextual information. This paper introduces Multi-scale Concatenation, a family of composable procedures that transform arbitrary single-scale CATE estimation algorithms into multi-scale algorithms. We benchmark the performance of Multi-scale Concatenation on a CATE estimation pipeline combining Vision Transformer (ViT) models fine-tuned on satellite images to encode images of different scales with Causal Forests to obtain the final CATE estimate. We first perform simulation studies, showing how a multi-scale approach captures multi-level dynamics that single-scale ViT models fail to capture. We then apply the multi-scale method to two randomized controlled trials (RCTs) conducted in Peru and Uganda using Landsat satellite imagery. In the RCT analysis, the Rank Average Treatment Effect Ratio (RATE Ratio) measure is employed to assess performance without ground truth individual treatment effects. Results indicate that Multi-scale Concatenation improves the performance of deep learning models in EO-based CATE estimation without the complexity of designing new multi-scale architectures for a specific use case.
Planetary Causal Inference: Implications for the Geography of Poverty
May 30, 2024Earth observation data such as satellite imagery can, when combined with machine learning, have profound impacts on our understanding of the geography of poverty through the prediction of living conditions, especially where government-derived economic indicators are either unavailable or potentially untrustworthy. Recent work has progressed in using EO data not only to predict spatial economic outcomes, but also to explore cause and effect, an understanding which is critical for downstream policy analysis. In this review, we first document the growth of interest in EO-ML analyses in the causal space. We then trace the relationship between spatial statistics and EO-ML methods before discussing the four ways in which EO data has been used in causal ML pipelines -- (1.) poverty outcome imputation for downstream causal analysis, (2.) EO image deconfounding, (3.) EO-based treatment effect heterogeneity, and (4.) EO-based transportability analysis. We conclude by providing a workflow for how researchers can incorporate EO data in causal ML analysis going forward.
Can Large Language Models (or Humans) Distill Text?
Mar 25, 2024We investigate the potential of large language models (LLMs) to distill text: to remove the textual traces of an undesired forbidden variable. We employ a range of LLMs with varying architectures and training approaches to distill text by identifying and removing information about the target variable while preserving other relevant signals. Our findings shed light on the strengths and limitations of LLMs in addressing the distillation and provide insights into the strategies for leveraging these models in computational social science investigations involving text data. In particular, we show that in the strong test of removing sentiment, the statistical association between the processed text and sentiment is still clearly detectable to machine learning classifiers post-LLM-distillation. Furthermore, we find that human annotators also struggle to distill sentiment while preserving other semantic content. This suggests there may be limited separability between concept variables in some text contexts, highlighting limitations of methods relying on text-level transformations and also raising questions about the robustness of distillation methods that achieve statistical independence in representation space if this is difficult for human coders operating on raw text to attain.
Deep Learning With DAGs
Jan 12, 2024Social science theories often postulate causal relationships among a set of variables or events. Although directed acyclic graphs (DAGs) are increasingly used to represent these theories, their full potential has not yet been realized in practice. As non-parametric causal models, DAGs require no assumptions about the functional form of the hypothesized relationships. Nevertheless, to simplify the task of empirical evaluation, researchers tend to invoke such assumptions anyway, even though they are typically arbitrary and do not reflect any theoretical content or prior knowledge. Moreover, functional form assumptions can engender bias, whenever they fail to accurately capture the complexity of the causal system under investigation. In this article, we introduce causal-graphical normalizing flows (cGNFs), a novel approach to causal inference that leverages deep neural networks to empirically evaluate theories represented as DAGs. Unlike conventional approaches, cGNFs model the full joint distribution of the data according to a DAG supplied by the analyst, without relying on stringent assumptions about functional form. In this way, the method allows for flexible, semi-parametric estimation of any causal estimand that can be identified from the DAG, including total effects, conditional effects, direct and indirect effects, and path-specific effects. We illustrate the method with a reanalysis of Blau and Duncan's (1967) model of status attainment and Zhou's (2019) model of conditional versus controlled mobility. To facilitate adoption, we provide open-source software together with a series of online tutorials for implementing cGNFs. The article concludes with a discussion of current limitations and directions for future development.