 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensitivity Analysis to Unobserved Confounding with Copula-based Normalizing Flows
Aug 12, 2025We propose a novel method for sensitivity analysis to unobserved confounding in causal inference. The method builds on a copula-based causal graphical normalizing flow that we term $\rho$-GNF, where $\rho \in [-1,+1]$ is the sensitivity parameter. The parameter represents the non-causal association between exposure and outcome due to unobserved confounding, which is modeled as a Gaussian copula. In other words, the $\rho$-GNF enables scholars to estimate the average causal effect (ACE) as a function of $\rho$, accounting for various confounding strengths. The output of the $\rho$-GNF is what we term the $\rho_{curve}$, which provides the bounds for the ACE given an interval of assumed $\rho$ values. The $\rho_{curve}$ also enables scholars to identify the confounding strength required to nullify the ACE. We also propose a Bayesian version of our sensitivity analysis method. Assuming a prior over the sensitivity parameter $\rho$ enables us to derive the posterior distribution over the ACE, which enables us to derive credible intervals. Finally, leveraging on experiments from simulated and real-world data, we show the benefits of our sensitivity analysis method.
Deep Learning With DAGs
Jan 12, 2024Social science theories often postulate causal relationships among a set of variables or events. Although directed acyclic graphs (DAGs) are increasingly used to represent these theories, their full potential has not yet been realized in practice. As non-parametric causal models, DAGs require no assumptions about the functional form of the hypothesized relationships. Nevertheless, to simplify the task of empirical evaluation, researchers tend to invoke such assumptions anyway, even though they are typically arbitrary and do not reflect any theoretical content or prior knowledge. Moreover, functional form assumptions can engender bias, whenever they fail to accurately capture the complexity of the causal system under investigation. In this article, we introduce causal-graphical normalizing flows (cGNFs), a novel approach to causal inference that leverages deep neural networks to empirically evaluate theories represented as DAGs. Unlike conventional approaches, cGNFs model the full joint distribution of the data according to a DAG supplied by the analyst, without relying on stringent assumptions about functional form. In this way, the method allows for flexible, semi-parametric estimation of any causal estimand that can be identified from the DAG, including total effects, conditional effects, direct and indirect effects, and path-specific effects. We illustrate the method with a reanalysis of Blau and Duncan's (1967) model of status attainment and Zhou's (2019) model of conditional versus controlled mobility. To facilitate adoption, we provide open-source software together with a series of online tutorials for implementing cGNFs. The article concludes with a discussion of current limitations and directions for future development.
$ρ$-GNF : A Novel Sensitivity Analysis Approach Under Unobserved Confounders
Sep 15, 2022
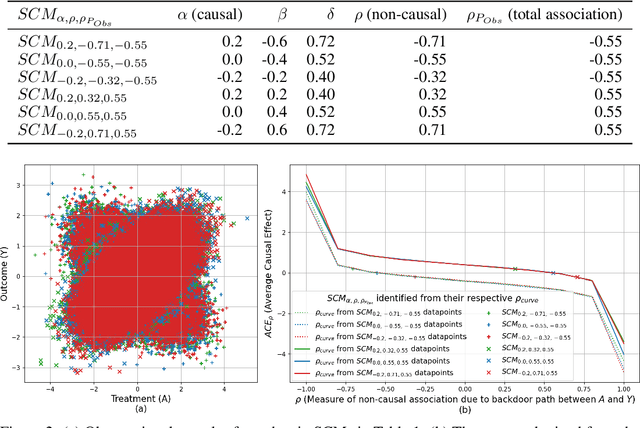


We propose a new sensitivity analysis model that combines copulas and normalizing flows for causal inference under unobserved confounding. We refer to the new model as $\rho$-GNF ($\rho$-Graphical Normalizing Flow), where $\rho{\in}[-1,+1]$ is a bounded sensitivity parameter representing the backdoor non-causal association due to unobserved confounding modeled using the most well studied and widely popular Gaussian copula. Specifically, $\rho$-GNF enables us to estimate and analyse the frontdoor causal effect or average causal effect (ACE) as a function of $\rho$. We call this the $\rho_{curve}$. The $\rho_{curve}$ enables us to specify the confounding strength required to nullify the ACE. We call this the $\rho_{value}$. Further, the $\rho_{curve}$ also enables us to provide bounds for the ACE given an interval of $\rho$ values. We illustrate the benefits of $\rho$-GNF with experiments on simulated and real-world data in terms of our empirical ACE bounds being narrower than other popular ACE bounds.
Counterfactual Analysis of the Impact of the IMF Program on Child Poverty in the Global-South Region using Causal-Graphical Normalizing Flows
Feb 17, 2022


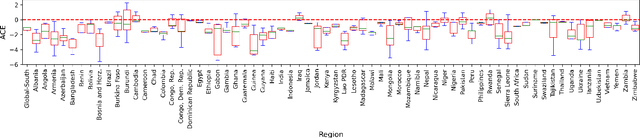
This work demonstrates the application of a particular branch of causal inference and deep learning models: \emph{causal-Graphical Normalizing Flows (c-GNFs)}. In a recent contribution, scholars showed that normalizing flows carry certain properties, making them particularly suitable for causal and counterfactual analysis. However, c-GNFs have only been tested in a simulated data setting and no contribution to date have evaluated the application of c-GNFs on large-scale real-world data. Focusing on the \emph{AI for social good}, our study provides a counterfactual analysis of the impact of the International Monetary Fund (IMF) program on child poverty using c-GNFs. The analysis relies on a large-scale real-world observational data: 1,941,734 children under the age of 18, cared for by 567,344 families residing in the 67 countries from the Global-South. While the primary objective of the IMF is to support governments in achieving economic stability, our results find that an IMF program reduces child poverty as a positive side-effect by about 1.2$\pm$0.24 degree (`0' equals no poverty and `7' is maximum poverty). Thus, our article shows how c-GNFs further the use of deep learning and causal inference in AI for social good. It shows how learning algorithms can be used for addressing the untapped potential for a significant social impact through counterfactual inference at population level (ACE), sub-population level (CACE), and individual level (ICE). In contrast to most works that model ACE or CACE but not ICE, c-GNFs enable personalization using \emph{`The First Law of Causal Inference'}.
Personalized Public Policy Analysis in Social Sciences using Causal-Graphical Normalizing Flows
Feb 07, 2022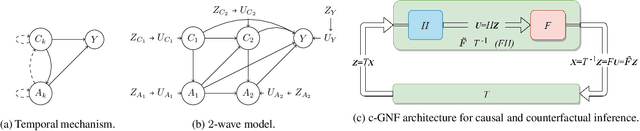
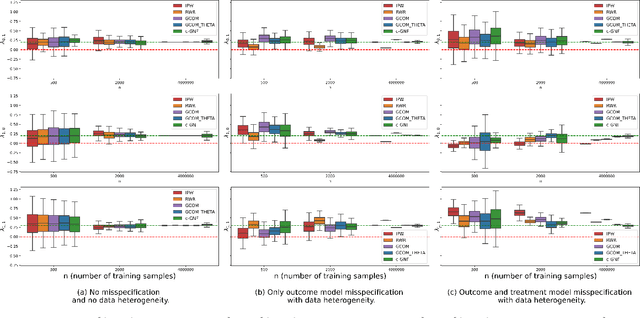
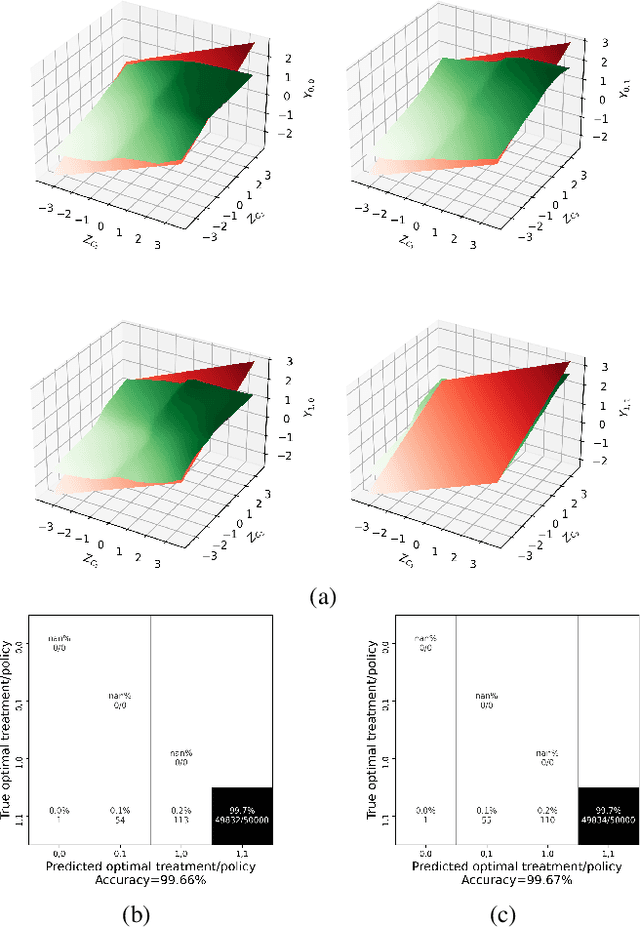
Structural Equation/Causal Models (SEMs/SCMs) are widely used in epidemiology and social sciences to identify and analyze the average treatment effect (ATE) and conditional ATE (CATE). Traditional causal effect estimation methods such as Inverse Probability Weighting (IPW) and more recently Regression-With-Residuals (RWR) are widely used - as they avoid the challenging task of identifying the SCM parameters - to estimate ATE and CATE. However, much work remains before traditional estimation methods can be used for counterfactual inference, and for the benefit of Personalized Public Policy Analysis (P$^3$A) in the social sciences. While doctors rely on personalized medicine to tailor treatments to patients in laboratory settings (relatively closed systems), P$^3$A draws inspiration from such tailoring but adapts it for open social systems. In this article, we develop a method for counterfactual inference that we name causal-Graphical Normalizing Flow (c-GNF), facilitating P$^3$A. First, we show how c-GNF captures the underlying SCM without making any assumption about functional forms. Second, we propose a novel dequantization trick to deal with discrete variables, which is a limitation of normalizing flows in general. Third, we demonstrate in experiments that c-GNF performs on-par with IPW and RWR in terms of bias and variance for estimating the ATE, when the true functional forms are known, and better when they are unknown. Fourth and most importantly, we conduct counterfactual inference with c-GNFs, demonstrating promising empirical performance. Because IPW and RWR, like other traditional methods, lack the capability of counterfactual inference, c-GNFs will likely play a major role in tailoring personalized treatment, facilitating P$^3$A, optimizing social interventions - in contrast to the current `one-size-fits-all' approach of existing methods.
Contradistinguisher: A Vapnik's Imperative to Unsupervised Domain Adaptation
Jun 10, 2020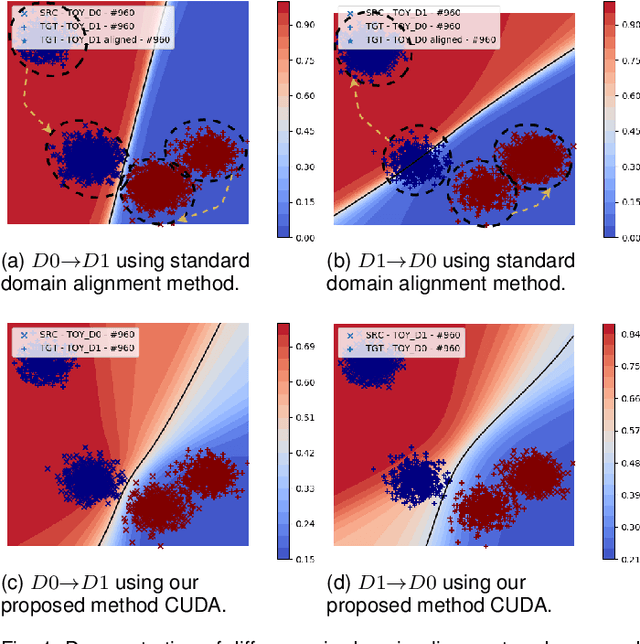


A complex combination of simultaneous supervised-unsupervised learning is believed to be the key to humans performing tasks seamlessly across multiple domains or tasks. This phenomenon of cross-domain learning has been very well studied in domain adaptation literature. Recent domain adaptation works rely on an indirect way of first aligning the source and target domain distributions and then train a classifier on the labeled source domain to classify the target domain. However, this approach has the main drawback that obtaining a near-perfect alignment of the domains in itself might be difficult/impossible (e.g., language domains). To address this, we follow Vapnik's imperative of statistical learning that states any desired problem should be solved in the most direct way rather than solving a more general intermediate task and propose a direct approach to domain adaptation that does not require domain alignment. We propose a model referred Contradistinguisher that learns contrastive features and whose objective is to jointly learn to contradistinguish the unlabeled target domain in an unsupervised way and classify in a supervised way on the source domain. We achieve the state-of-the-art on Office-31 and VisDA-2017 datasets in both single-source and multi-source settings. We also demonstrate that the contradistinguish loss improves the model performance by increasing the shape bias.
CUDA: Contradistinguisher for Unsupervised Domain Adaptation
Sep 08, 2019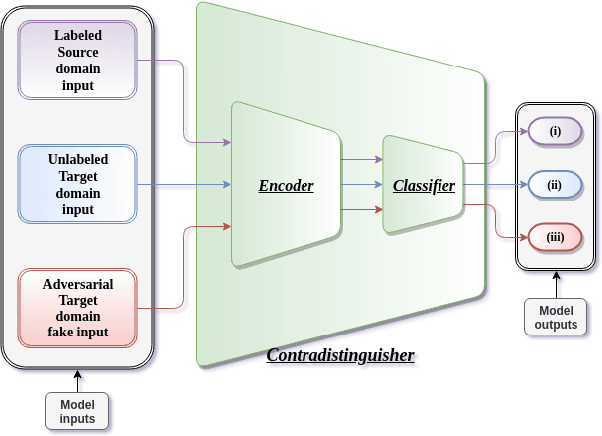

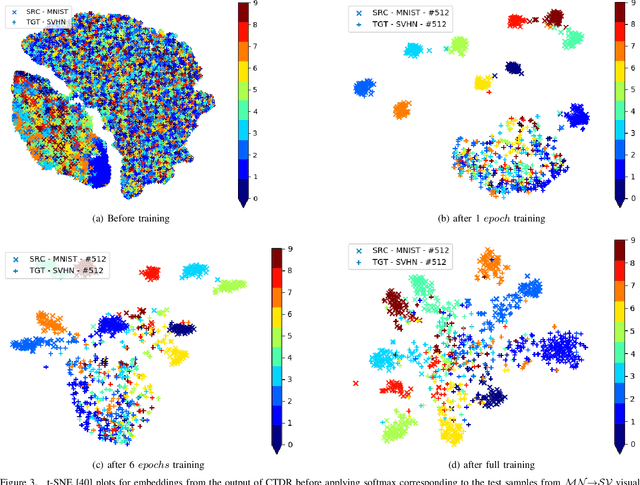
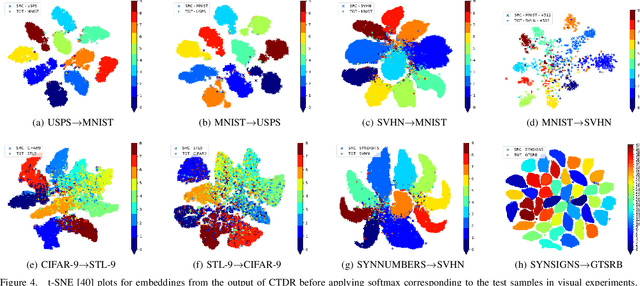
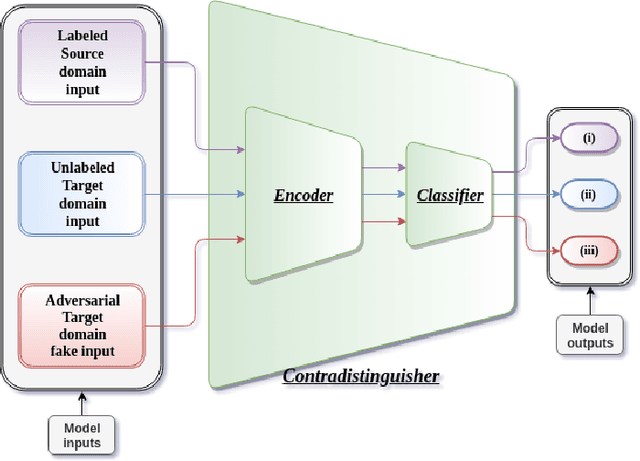
In this paper, we propose a simple model referred as Contradistinguisher (CTDR) for unsupervised domain adaptation whose objective is to jointly learn to contradistinguish on unlabeled target domain in a fully unsupervised manner along with prior knowledge acquired by supervised learning on an entirely different domain. Most recent works in domain adaptation rely on an indirect way of first aligning the source and target domain distributions and then learn a classifier on a labeled source domain to classify target domain. This approach of an indirect way of addressing the real task of unlabeled target domain classification has three main drawbacks. (i) The sub-task of obtaining a perfect alignment of the domain in itself might be impossible due to large domain shift (e.g., language domains). (ii) The use of multiple classifiers to align the distributions unnecessarily increases the complexity of the neural networks leading to over-fitting in many cases. (iii) Due to distribution alignment, the domain-specific information is lost as the domains get morphed. In this work, we propose a simple and direct approach that does not require domain alignment. We jointly learn CTDR on both source and target distribution for unsupervised domain adaptation task using contradistinguish loss for the unlabeled target domain in conjunction with a supervised loss for labeled source domain. Our experiments show that avoiding domain alignment by directly addressing the task of unlabeled target domain classification using CTDR achieves state-of-the-art results on eight visual and four language benchmark domain adaptation datasets.