 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Earth Observation Data into Causal Inference: Challenges and Opportunities
Jan 30, 2023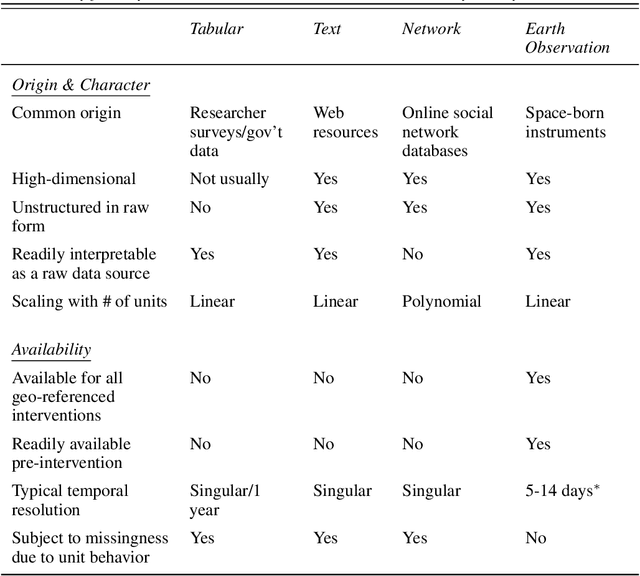


Observational studies require adjustment for confounding factors that are correlated with both the treatment and outcome. In the setting where the observed variables are tabular quantities such as average income in a neighborhood, tools have been developed for addressing such confounding. However, in many parts of the developing world, features about local communities may be scarce. In this context, satellite imagery can play an important role, serving as a proxy for the confounding variables otherwise unobserved. In this paper, we study confounder adjustment in this non-tabular setting, where patterns or objects found in satellite images contribute to the confounder bias. Using the evaluation of anti-poverty aid programs in Africa as our running example, we formalize the challenge of performing causal adjustment with such unstructured data -- what conditions are sufficient to identify causal effects, how to perform estimation, and how to quantify the ways in which certain aspects of the unstructured image object are most predictive of the treatment decision. Via simulation, we also explore the sensitivity of satellite image-based observational inference to image resolution and to misspecification of the image-associated confounder. Finally, we apply these tools in estimating the effect of anti-poverty interventions in African communities from satellite imagery.
Sharing pattern submodels for prediction with missing values
Jun 22, 2022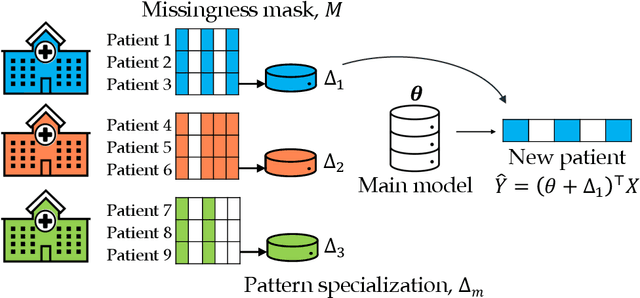
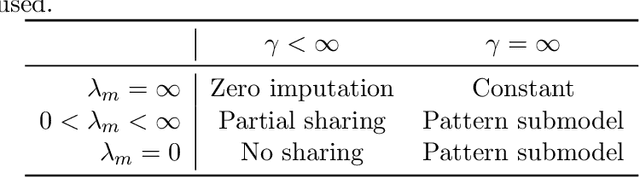
Missing values are unavoidable in many applications of machine learning and present a challenge both during training and at test time. When variables are missing in recurring patterns, fitting separate pattern submodels have been proposed as a solution. However, independent models do not make efficient use of all available data. Conversely, fitting a shared model to the full data set typically relies on imputation which may be suboptimal when missingness depends on unobserved factors. We propose an alternative approach, called sharing pattern submodels, which make predictions that are a) robust to missing values at test time, b) maintains or improves the predictive power of pattern submodels, and c) has a short description enabling improved interpretability. We identify cases where sharing is provably optimal, even when missingness itself is predictive and when the prediction target depends on unobserved variables. Classification and regression experiments on synthetic data and two healthcare data sets demonstrate that our models achieve a favorable trade-off between pattern specialization and information sharing.
Image-based Treatment Effect Heterogeneity
Jun 13, 2022
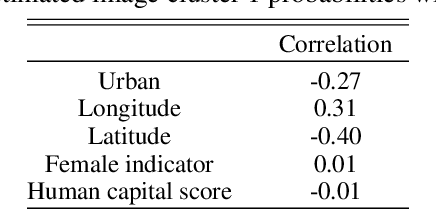

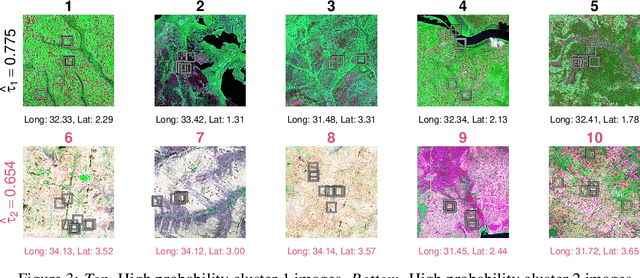
Randomized controlled trials (RCTs) are considered the gold standard for estimating the effects of interventions. Recent work has studied effect heterogeneity in RCTs by conditioning estimates on tabular variables such as age and ethnicity. However, such variables are often only observed near the time of the experiment and may fail to capture historical or geographical reasons for effect variation. When experiment units are associated with a particular location, satellite imagery can provide such historical and geographical information, yet there is no method which incorporates it for describing effect heterogeneity. In this paper, we develop such a method which estimates, using a deep probabilistic modeling framework, the clusters of images having the same distribution over treatment effects. We compare the proposed methods against alternatives in simulation and in an application to estimating the effects of an anti-poverty intervention in Uganda. A causal regularization penalty is introduced to ensure reliability of the cluster model in recovering Average Treatment Effects (ATEs). Finally, we discuss feasibility, limitations, and the applicability of these methods to other domains, such as medicine and climate science, where image information is prevalent. We make code for all modeling strategies publicly available in an open-source software package.
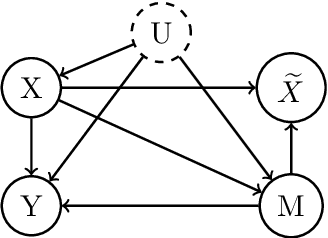
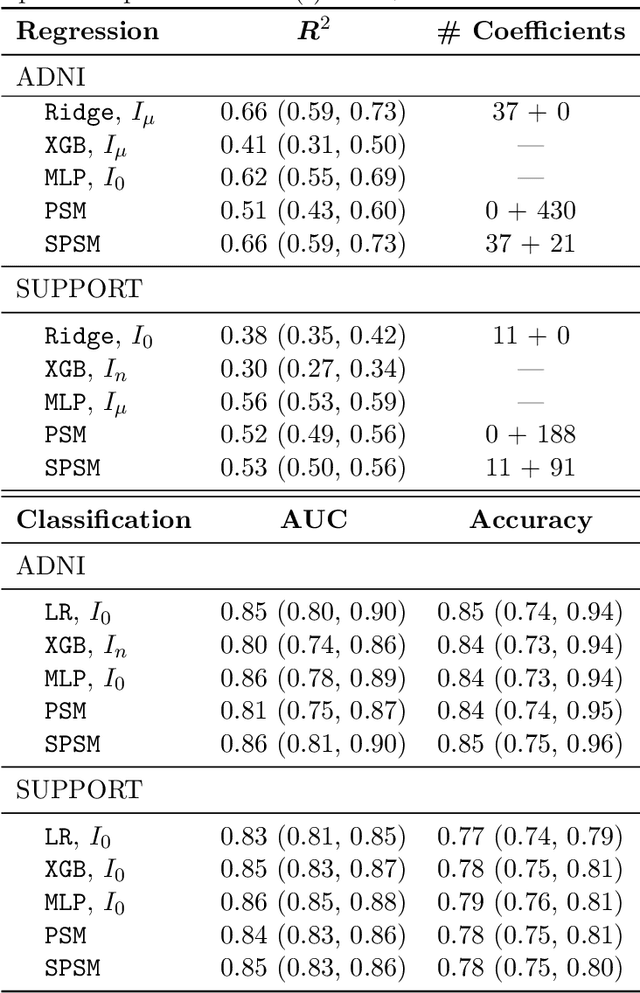
Estimating Causal Effects Under Image Confounding Bias with an Application to Poverty in Africa
Jun 13, 2022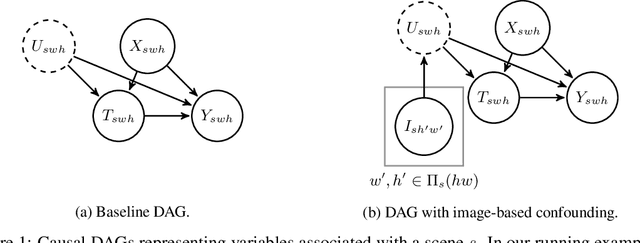

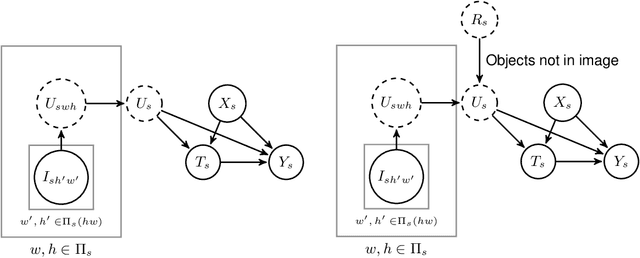
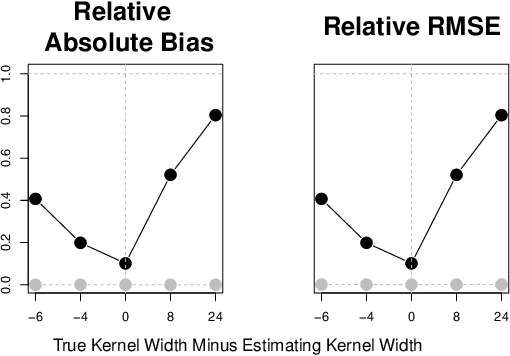
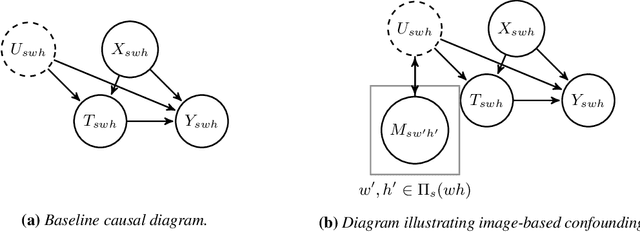
Observational studies of causal effects require adjustment for confounding factors. In the tabular setting, where these factors are well-defined, separate random variables, the effect of confounding is well understood. However, in public policy, ecology, and in medicine, decisions are often made in non-tabular settings, informed by patterns or objects detected in images (e.g., maps, satellite or tomography imagery). Using such imagery for causal inference presents an opportunity because objects in the image may be related to the treatment and outcome of interest. In these cases, we rely on the images to adjust for confounding but observed data do not directly label the existence of the important objects. Motivated by real-world applications, we formalize this challenge, how it can be handled, and what conditions are sufficient to identify and estimate causal effects. We analyze finite-sample performance using simulation experiments, estimating effects using a propensity adjustment algorithm that employs a machine learning model to estimate the image confounding. Our experiments also examine sensitivity to misspecification of the image pattern mechanism. Finally, we use our methodology to estimate the effects of policy interventions on poverty in African communities from satellite imagery.
Evaluating Reinforcement Learning Algorithms in Observational Health Settings
May 31, 2018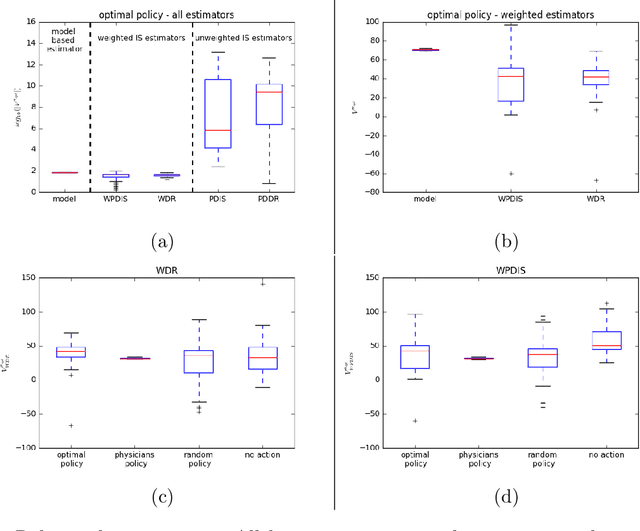
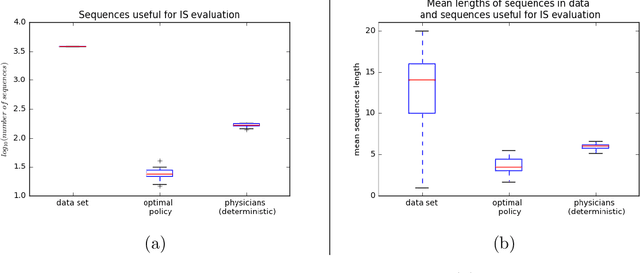
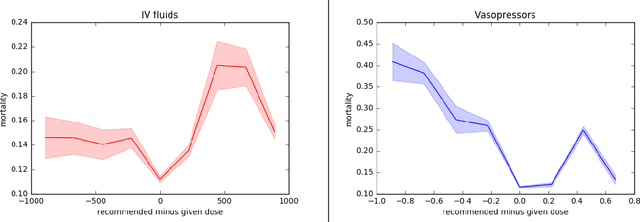
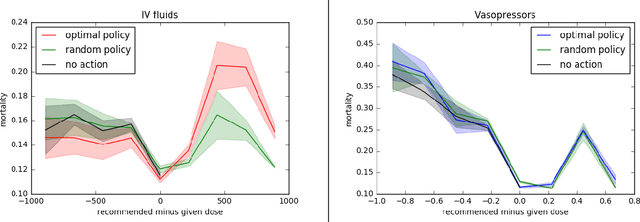
Much attention has been devoted recently to the development of machine learning algorithms with the goal of improving treatment policies in healthcare. Reinforcement learning (RL) is a sub-field within machine learning that is concerned with learning how to make sequences of decisions so as to optimize long-term effects. Already, RL algorithms have been proposed to identify decision-making strategies for mechanical ventilation, sepsis management and treatment of schizophrenia. However, before implementing treatment policies learned by black-box algorithms in high-stakes clinical decision problems, special care must be taken in the evaluation of these policies. In this document, our goal is to expose some of the subtleties associated with evaluating RL algorithms in healthcare. We aim to provide a conceptual starting point for clinical and computational researchers to ask the right questions when designing and evaluating algorithms for new ways of treating patients. In the following, we describe how choices about how to summarize a history, variance of statistical estimators, and confounders in more ad-hoc measures can result in unreliable, even misleading estimates of the quality of a treatment policy. We also provide suggestions for mitigating these effects---for while there is much promise for mining observational health data to uncover better treatment policies, evaluation must be performed thoughtfully.