 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Advances, Applications, and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2023 Symposium
Mar 03, 2024The third ML4H symposium was held in person on December 10, 2023, in New Orleans, Louisiana, USA. The symposium included research roundtable sessions to foster discussions between participants and senior researchers on timely and relevant topics for the \ac{ML4H} community. Encouraged by the successful virtual roundtables in the previous year, we organized eleven in-person roundtables and four virtual roundtables at ML4H 2022. The organization of the research roundtables at the conference involved 17 Senior Chairs and 19 Junior Chairs across 11 tables. Each roundtable session included invited senior chairs (with substantial experience in the field), junior chairs (responsible for facilitating the discussion), and attendees from diverse backgrounds with interest in the session's topic. Herein we detail the organization process and compile takeaways from these roundtable discussions, including recent advances, applications, and open challenges for each topic. We conclude with a summary and lessons learned across all roundtables. This document serves as a comprehensive review paper, summarizing the recent advancements in machine learning for healthcare as contributed by foremost researchers in the field.
CEHR-GPT: Generating Electronic Health Records with Chronological Patient Timelines
Feb 06, 2024



Synthetic Electronic Health Records (EHR) have emerged as a pivotal tool in advancing healthcare applications and machine learning models, particularly for researchers without direct access to healthcare data. Although existing methods, like rule-based approaches and generative adversarial networks (GANs), generate synthetic data that resembles real-world EHR data, these methods often use a tabular format, disregarding temporal dependencies in patient histories and limiting data replication. Recently, there has been a growing interest in leveraging Generative Pre-trained Transformers (GPT) for EHR data. This enables applications like disease progression analysis, population estimation, counterfactual reasoning, and synthetic data generation. In this work, we focus on synthetic data generation and demonstrate the capability of training a GPT model using a particular patient representation derived from CEHR-BERT, enabling us to generate patient sequences that can be seamlessly converted to the Observational Medical Outcomes Partnership (OMOP) data format.
A Bayesian Causal Inference Approach for Assessing Fairness in Clinical Decision-Making
Nov 21, 2022



Fairness in clinical decision-making is a critical element of health equity, but assessing fairness of clinical decisions from observational data is challenging. Recently, many fairness notions have been proposed to quantify fairness in decision-making, among which causality-based fairness notions have gained increasing attention due to its potential in adjusting for confounding and reasoning about bias. However, causal fairness notions remain under-explored in the context of clinical decision-making with large-scale healthcare data. In this work, we propose a Bayesian causal inference approach for assessing a causal fairness notion called principal fairness in clinical settings. We demonstrate our approach using both simulated data and electronic health records (EHR) data.
The Medical Deconfounder: Assessing Treatment Effect with Electronic Health Records (EHRs)
Apr 03, 2019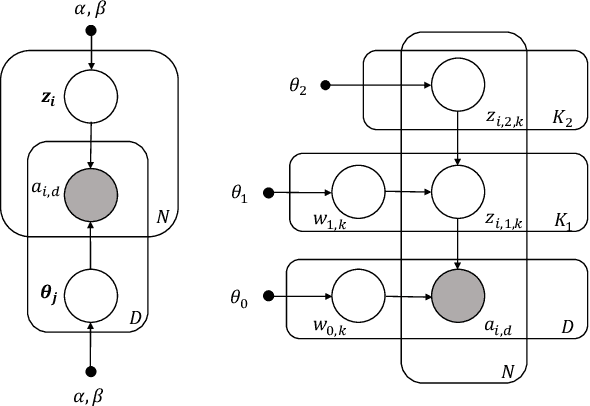
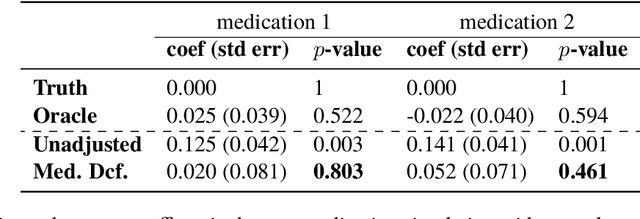
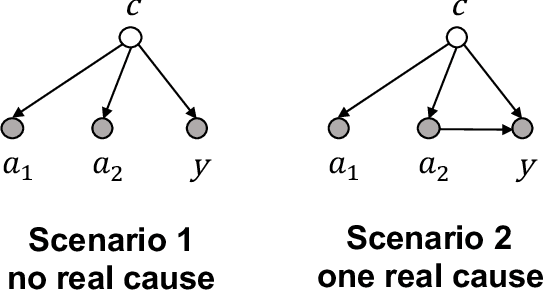
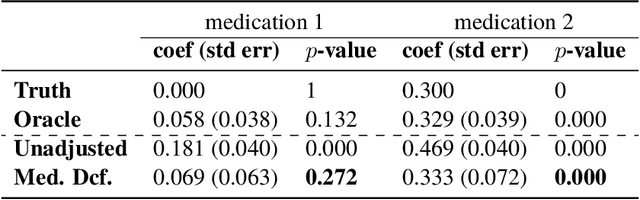
Causal estimation of treatment effect has an important role in guiding physicians' decision process for drug prescription. While treatment effect is classically assessed with randomized controlled trials (RCTs), the availability of electronic health records (EHRs) bring an unprecedented opportunity for more efficient estimation. However, the presence of unobserved confounders makes treatment effect assessment from EHRs a challenging task. Confounders are the variables that affect both drug prescription and the patient's outcome; examples include a patient's gender, race, social economic status and comorbidities. When these confounders are unobserved, they bias the estimation. To adjust for unobserved confounders, we develop the medical deconfounder, a machine learning algorithm that unbiasedly estimates treatment effect from EHRs. The medical deconfounder first constructs a substitute confounder by modeling which drugs were prescribed to each patient; this substitute confounder is guaranteed to capture all multi-drug confounders, observed or unobserved (Wang and Blei, 2018). It then uses this substitute confounder to adjust for the confounding bias in the analysis. We validate the medical deconfounder on simulations and two medical data sets. The medical deconfounder produces closer-to-truth estimates in simulations and identifies effective medications that are more consistent with the findings reported in the medical literature compared to classical approaches.
Evaluating Reinforcement Learning Algorithms in Observational Health Settings
May 31, 2018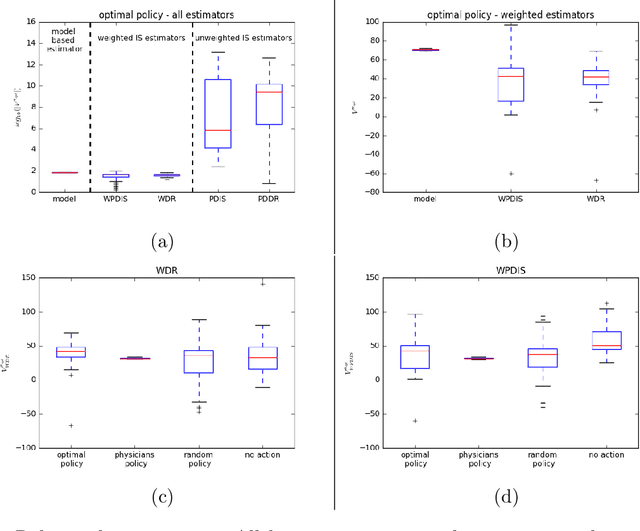
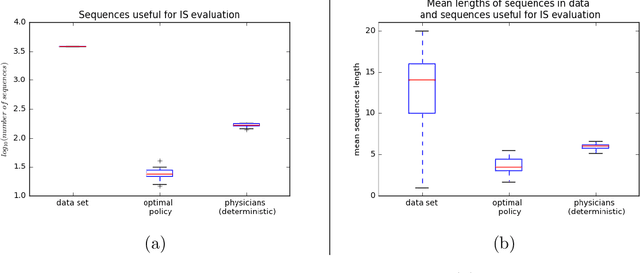
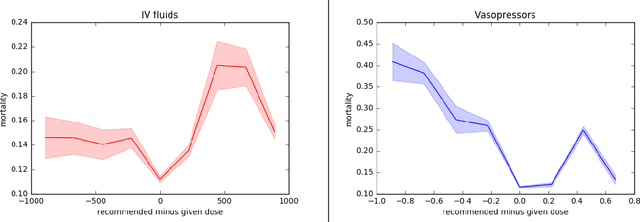
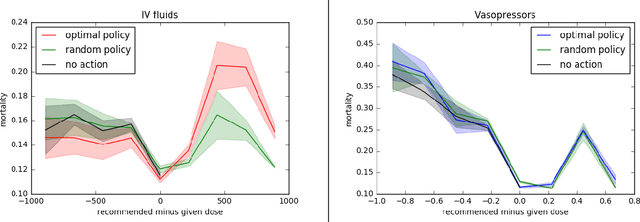
Much attention has been devoted recently to the development of machine learning algorithms with the goal of improving treatment policies in healthcare. Reinforcement learning (RL) is a sub-field within machine learning that is concerned with learning how to make sequences of decisions so as to optimize long-term effects. Already, RL algorithms have been proposed to identify decision-making strategies for mechanical ventilation, sepsis management and treatment of schizophrenia. However, before implementing treatment policies learned by black-box algorithms in high-stakes clinical decision problems, special care must be taken in the evaluation of these policies. In this document, our goal is to expose some of the subtleties associated with evaluating RL algorithms in healthcare. We aim to provide a conceptual starting point for clinical and computational researchers to ask the right questions when designing and evaluating algorithms for new ways of treating patients. In the following, we describe how choices about how to summarize a history, variance of statistical estimators, and confounders in more ad-hoc measures can result in unreliable, even misleading estimates of the quality of a treatment policy. We also provide suggestions for mitigating these effects---for while there is much promise for mining observational health data to uncover better treatment policies, evaluation must be performed thoughtfully.