 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEHR-GPT: A Scalable Multi-Task Foundation Model for Electronic Health Records
Sep 03, 2025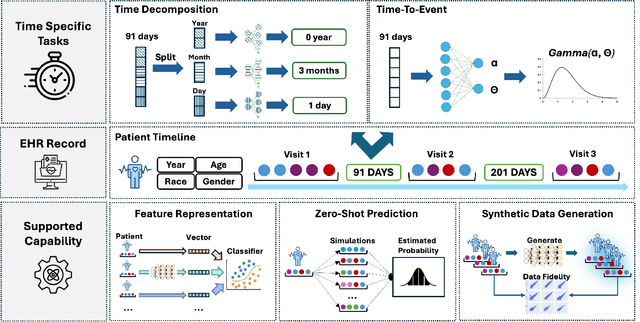

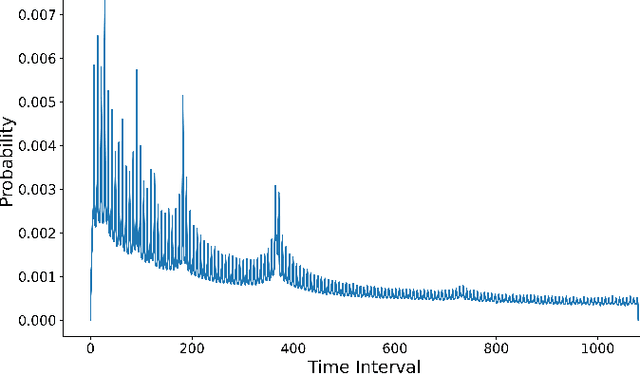

Electronic Health Records (EHRs) provide a rich, longitudinal view of patient health and hold significant potential for advancing clinical decision support, risk prediction, and data-driven healthcare research. However, most artificial intelligence (AI) models for EHRs are designed for narrow, single-purpose tasks, limiting their generalizability and utility in real-world settings. Here, we present CEHR-GPT, a general-purpose foundation model for EHR data that unifies three essential capabilities - feature representation, zero-shot prediction, and synthetic data generation - within a single architecture. To support temporal reasoning over clinical sequences, \cehrgpt{} incorporates a novel time-token-based learning framework that explicitly encodes patients' dynamic timelines into the model structure. CEHR-GPT demonstrates strong performance across all three tasks and generalizes effectively to external datasets through vocabulary expansion and fine-tuning. Its versatility enables rapid model development, cohort discovery, and patient outcome forecasting without the need for task-specific retraining.
Going from a Representative Agent to Counterfactuals in Combinatorial Choice
May 29, 2025We study decision-making problems where data comprises points from a collection of binary polytopes, capturing aggregate information stemming from various combinatorial selection environments. We propose a nonparametric approach for counterfactual inference in this setting based on a representative agent model, where the available data is viewed as arising from maximizing separable concave utility functions over the respective binary polytopes. Our first contribution is to precisely characterize the selection probabilities representable under this model and show that verifying the consistency of any given aggregated selection dataset reduces to solving a polynomial-sized linear program. Building on this characterization, we develop a nonparametric method for counterfactual prediction. When data is inconsistent with the model, finding a best-fitting approximation for prediction reduces to solving a compact mixed-integer convex program. Numerical experiments based on synthetic data demonstrate the method's flexibility, predictive accuracy, and strong representational power even under model misspecification.
FoMoH: A clinically meaningful foundation model evaluation for structured electronic health records
May 22, 2025Foundation models hold significant promise in healthcare, given their capacity to extract meaningful representations independent of downstream tasks. This property has enabled state-of-the-art performance across several clinical applications trained on structured electronic health record (EHR) data, even in settings with limited labeled data, a prevalent challenge in healthcare. However, there is little consensus on these models' potential for clinical utility due to the lack of desiderata of comprehensive and meaningful tasks and sufficiently diverse evaluations to characterize the benefit over conventional supervised learning. To address this gap, we propose a suite of clinically meaningful tasks spanning patient outcomes, early prediction of acute and chronic conditions, including desiderata for robust evaluations. We evaluate state-of-the-art foundation models on EHR data consisting of 5 million patients from Columbia University Irving Medical Center (CUMC), a large urban academic medical center in New York City, across 14 clinically relevant tasks. We measure overall accuracy, calibration, and subpopulation performance to surface tradeoffs based on the choice of pre-training, tokenization, and data representation strategies. Our study aims to advance the empirical evaluation of structured EHR foundation models and guide the development of future healthcare foundation models.
CEHR-GPT: Generating Electronic Health Records with Chronological Patient Timelines
Feb 06, 2024



Synthetic Electronic Health Records (EHR) have emerged as a pivotal tool in advancing healthcare applications and machine learning models, particularly for researchers without direct access to healthcare data. Although existing methods, like rule-based approaches and generative adversarial networks (GANs), generate synthetic data that resembles real-world EHR data, these methods often use a tabular format, disregarding temporal dependencies in patient histories and limiting data replication. Recently, there has been a growing interest in leveraging Generative Pre-trained Transformers (GPT) for EHR data. This enables applications like disease progression analysis, population estimation, counterfactual reasoning, and synthetic data generation. In this work, we focus on synthetic data generation and demonstrate the capability of training a GPT model using a particular patient representation derived from CEHR-BERT, enabling us to generate patient sequences that can be seamlessly converted to the Observational Medical Outcomes Partnership (OMOP) data format.
The Limit of the Marginal Distribution Model in Consumer Choice
Aug 12, 2022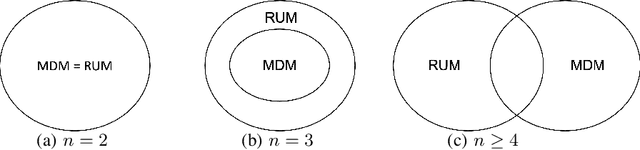

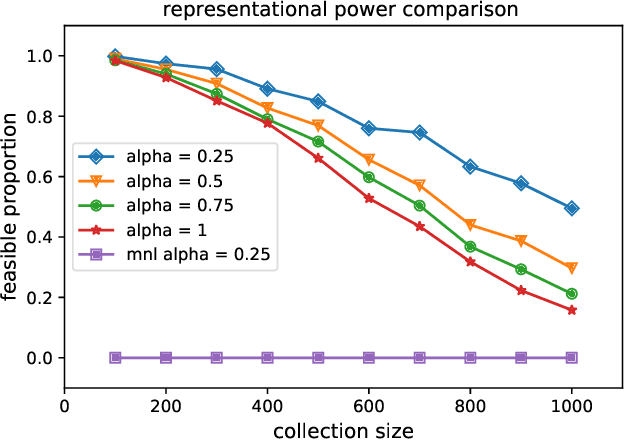
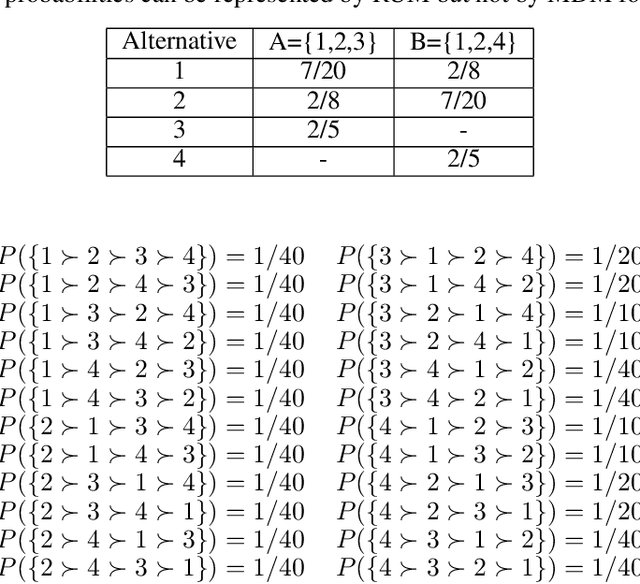
Given data on choices made by consumers for different assortments, a key challenge is to develop parsimonious models that describe and predict consumer choice behavior. One such choice model is the marginal distribution model which requires only the specification of the marginal distributions of the random utilities of the alternatives to explain choice data. In this paper, we develop an exact characterisation of the set of choice probabilities which are representable by the marginal distribution model consistently across any collection of assortments. Allowing for the possibility of alternatives to be grouped based on the marginal distribution of their utilities, we show (a) verifying consistency of choice probability data with this model is possible in polynomial time and (b) finding the closest fit reduces to solving a mixed integer convex program. Our results show that the marginal distribution model provides much better representational power as compared to multinomial logit and much better computational performance as compared to the random utility model.
Discrete Optimal Transport with Independent Marginals is #P-Hard
Mar 02, 2022We study the computational complexity of the optimal transport problem that evaluates the Wasserstein distance between the distributions of two K-dimensional discrete random vectors. The best known algorithms for this problem run in polynomial time in the maximum of the number of atoms of the two distributions. However, if the components of either random vector are independent, then this number can be exponential in K even though the size of the problem description scales linearly with K. We prove that the described optimal transport problem is #P-hard even if all components of the first random vector are independent uniform Bernoulli random variables, while the second random vector has merely two atoms, and even if only approximate solutions are sought. We also develop a dynamic programming-type algorithm that approximates the Wasserstein distance in pseudo-polynomial time when the components of the first random vector follow arbitrary independent discrete distributions, and we identify special problem instances that can be solved exactly in strongly polynomial time.
CEHR-BERT: Incorporating temporal information from structured EHR data to improve prediction tasks
Nov 10, 2021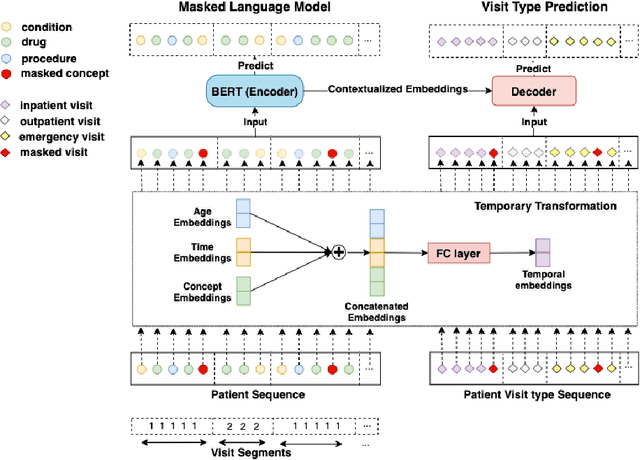

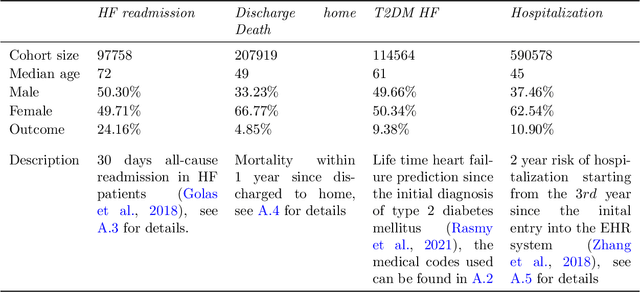

Embedding algorithms are increasingly used to represent clinical concepts in healthcare for improving machine learning tasks such as clinical phenotyping and disease prediction. Recent studies have adapted state-of-the-art bidirectional encoder representations from transformers (BERT) architecture to structured electronic health records (EHR) data for the generation of contextualized concept embeddings, yet do not fully incorporate temporal data across multiple clinical domains. Therefore we developed a new BERT adaptation, CEHR-BERT, to incorporate temporal information using a hybrid approach by augmenting the input to BERT using artificial time tokens, incorporating time, age, and concept embeddings, and introducing a new second learning objective for visit type. CEHR-BERT was trained on a subset of Columbia University Irving Medical Center-York Presbyterian Hospital's clinical data, which includes 2.4M patients, spanning over three decades, and tested using 4-fold cross-validation on the following prediction tasks: hospitalization, death, new heart failure (HF) diagnosis, and HF readmission. Our experiments show that CEHR-BERT outperformed existing state-of-the-art clinical BERT adaptations and baseline models across all 4 prediction tasks in both ROC-AUC and PR-AUC. CEHR-BERT also demonstrated strong transfer learning capability, as our model trained on only 5% of data outperformed comparison models trained on the entire data set. Ablation studies to better understand the contribution of each time component showed incremental gains with every element, suggesting that CEHR-BERT's incorporation of artificial time tokens, time and age embeddings with concept embeddings, and the addition of the second learning objective represents a promising approach for future BERT-based clinical embeddings.
Correlation Robust Influence Maximization
Oct 24, 2020
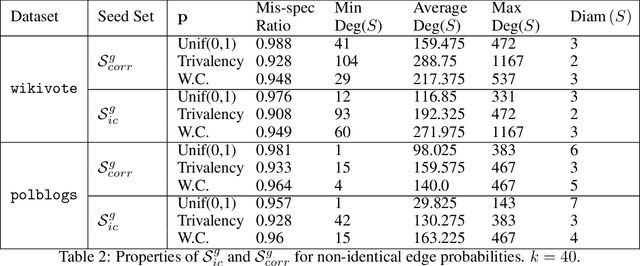
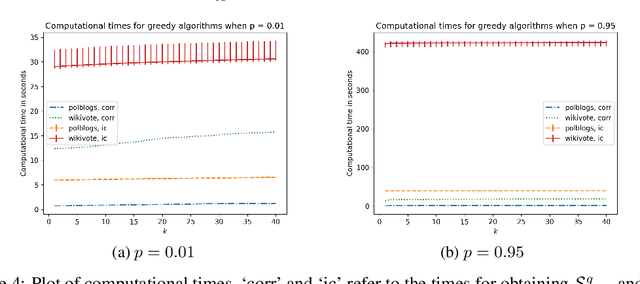

We propose a distributionally robust model for the influence maximization problem. Unlike the classic independent cascade model \citep{kempe2003maximizing}, this model's diffusion process is adversarially adapted to the choice of seed set. Hence, instead of optimizing under the assumption that all influence relationships in the network are independent, we seek a seed set whose expected influence under the worst correlation, i.e. the "worst-case, expected influence", is maximized. We show that this worst-case influence can be efficiently computed, and though the optimization is NP-hard, a ($1 - 1/e$) approximation guarantee holds. We also analyze the structure to the adversary's choice of diffusion process, and contrast with established models. Beyond the key computational advantages, we also highlight the extent to which the independence assumption may cost optimality, and provide insights from numerical experiments comparing the adversarial and independent cascade model.