 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoing from a Representative Agent to Counterfactuals in Combinatorial Choice
May 29, 2025We study decision-making problems where data comprises points from a collection of binary polytopes, capturing aggregate information stemming from various combinatorial selection environments. We propose a nonparametric approach for counterfactual inference in this setting based on a representative agent model, where the available data is viewed as arising from maximizing separable concave utility functions over the respective binary polytopes. Our first contribution is to precisely characterize the selection probabilities representable under this model and show that verifying the consistency of any given aggregated selection dataset reduces to solving a polynomial-sized linear program. Building on this characterization, we develop a nonparametric method for counterfactual prediction. When data is inconsistent with the model, finding a best-fitting approximation for prediction reduces to solving a compact mixed-integer convex program. Numerical experiments based on synthetic data demonstrate the method's flexibility, predictive accuracy, and strong representational power even under model misspecification.
The Limit of the Marginal Distribution Model in Consumer Choice
Aug 12, 2022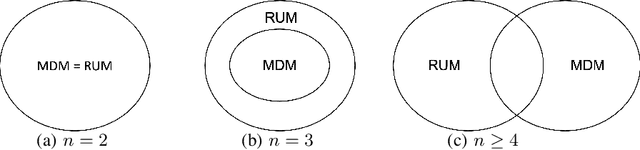

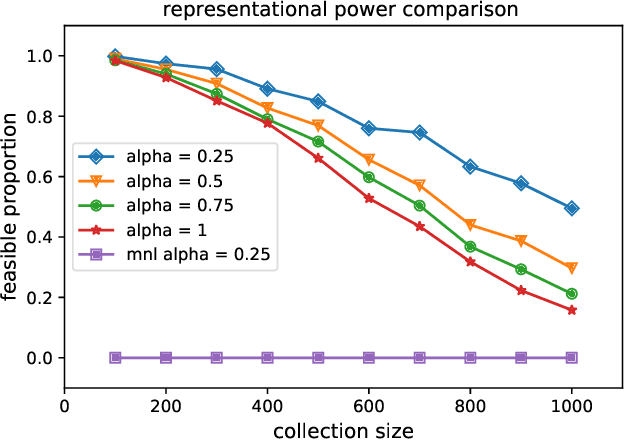
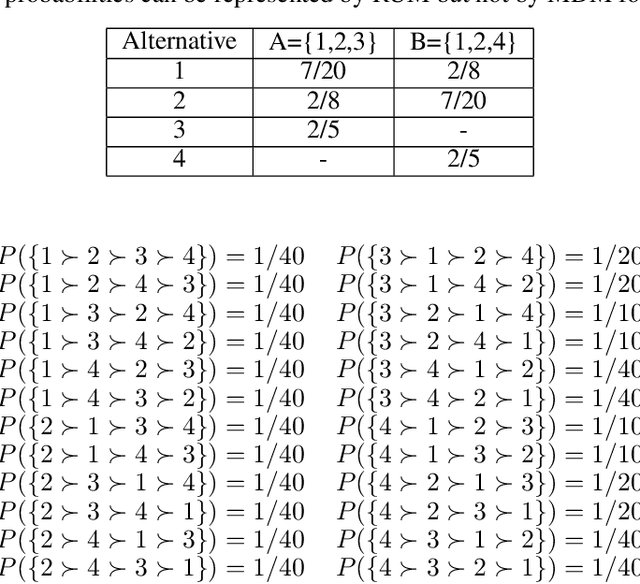
Given data on choices made by consumers for different assortments, a key challenge is to develop parsimonious models that describe and predict consumer choice behavior. One such choice model is the marginal distribution model which requires only the specification of the marginal distributions of the random utilities of the alternatives to explain choice data. In this paper, we develop an exact characterisation of the set of choice probabilities which are representable by the marginal distribution model consistently across any collection of assortments. Allowing for the possibility of alternatives to be grouped based on the marginal distribution of their utilities, we show (a) verifying consistency of choice probability data with this model is possible in polynomial time and (b) finding the closest fit reduces to solving a mixed integer convex program. Our results show that the marginal distribution model provides much better representational power as compared to multinomial logit and much better computational performance as compared to the random utility model.
Statistical Analysis of Wasserstein Distributionally Robust Estimators
Aug 04, 2021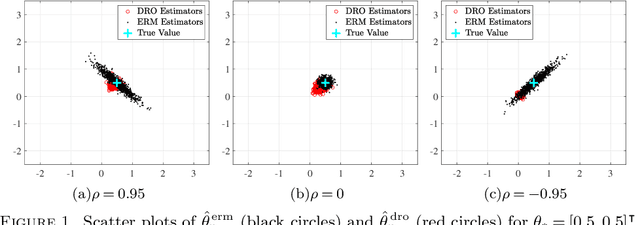
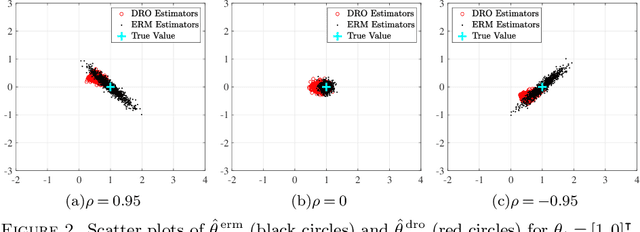
We consider statistical methods which invoke a min-max distributionally robust formulation to extract good out-of-sample performance in data-driven optimization and learning problems. Acknowledging the distributional uncertainty in learning from limited samples, the min-max formulations introduce an adversarial inner player to explore unseen covariate data. The resulting Distributionally Robust Optimization (DRO) formulations, which include Wasserstein DRO formulations (our main focus), are specified using optimal transportation phenomena. Upon describing how these infinite-dimensional min-max problems can be approached via a finite-dimensional dual reformulation, the tutorial moves into its main component, namely, explaining a generic recipe for optimally selecting the size of the adversary's budget. This is achieved by studying the limit behavior of an optimal transport projection formulation arising from an inquiry on the smallest confidence region that includes the unknown population risk minimizer. Incidentally, this systematic prescription coincides with those in specific examples in high-dimensional statistics and results in error bounds that are free from the curse of dimensions. Equipped with this prescription, we present a central limit theorem for the DRO estimator and provide a recipe for constructing compatible confidence regions that are useful for uncertainty quantification. The rest of the tutorial is devoted to insights into the nature of the optimizers selected by the min-max formulations and additional applications of optimal transport projections.
Efficient Black-Box Importance Sampling for VaR and CVaR Estimation
Jun 16, 2021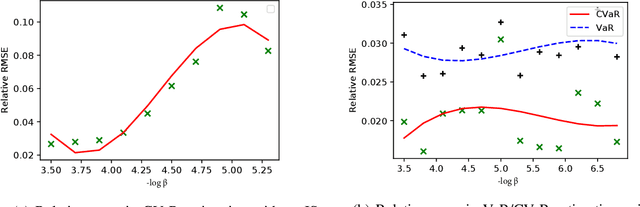
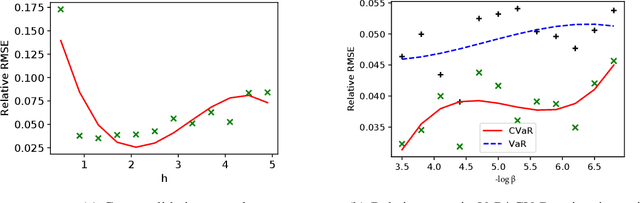
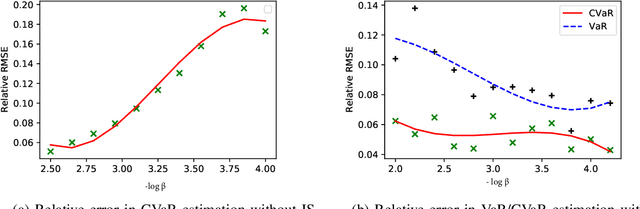
This paper considers Importance Sampling (IS) for the estimation of tail risks of a loss defined in terms of a sophisticated object such as a machine learning feature map or a mixed integer linear optimisation formulation. Assuming only black-box access to the loss and the distribution of the underlying random vector, the paper presents an efficient IS algorithm for estimating the Value at Risk and Conditional Value at Risk. The key challenge in any IS procedure, namely, identifying an appropriate change-of-measure, is automated with a self-structuring IS transformation that learns and replicates the concentration properties of the conditional excess from less rare samples. The resulting estimators enjoy asymptotically optimal variance reduction when viewed in the logarithmic scale. Simulation experiments highlight the efficacy and practicality of the proposed scheme
Testing Group Fairness via Optimal Transport Projections
Jun 02, 2021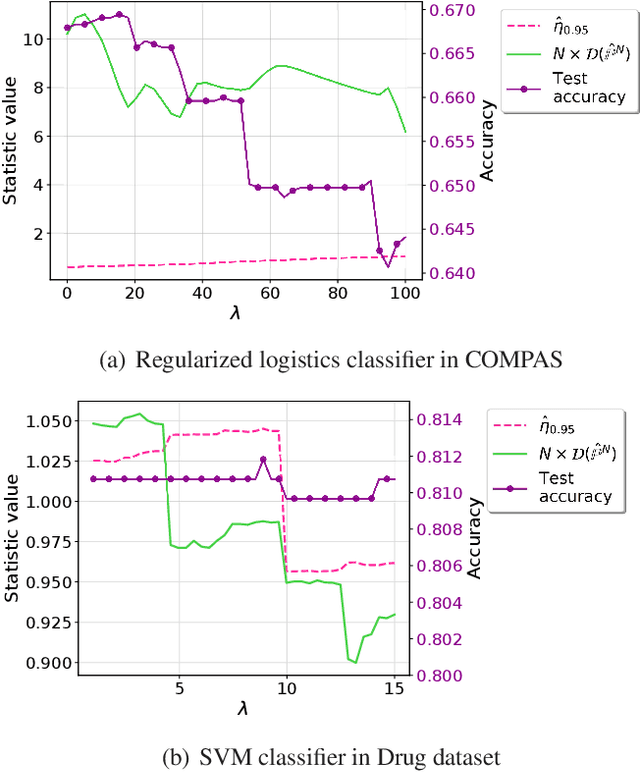


We present a statistical testing framework to detect if a given machine learning classifier fails to satisfy a wide range of group fairness notions. The proposed test is a flexible, interpretable, and statistically rigorous tool for auditing whether exhibited biases are intrinsic to the algorithm or due to the randomness in the data. The statistical challenges, which may arise from multiple impact criteria that define group fairness and which are discontinuous on model parameters, are conveniently tackled by projecting the empirical measure onto the set of group-fair probability models using optimal transport. This statistic is efficiently computed using linear programming and its asymptotic distribution is explicitly obtained. The proposed framework can also be used to test for testing composite fairness hypotheses and fairness with multiple sensitive attributes. The optimal transport testing formulation improves interpretability by characterizing the minimal covariate perturbations that eliminate the bias observed in the audit.
Achieving Efficiency in Black Box Simulation of Distribution Tails with Self-structuring Importance Samplers
Feb 14, 2021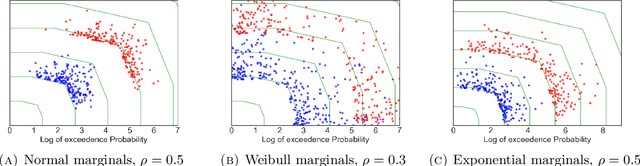

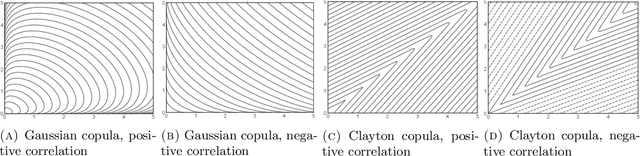

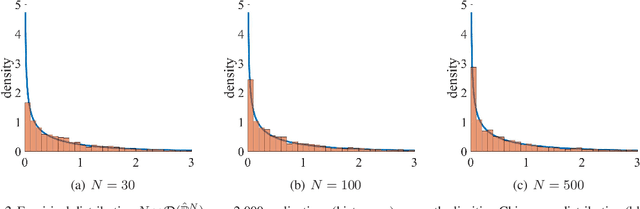
Motivated by the increasing adoption of models which facilitate greater automation in risk management and decision-making, this paper presents a novel Importance Sampling (IS) scheme for measuring distribution tails of objectives modelled with enabling tools such as feature-based decision rules, mixed integer linear programs, deep neural networks, etc. Conventional efficient IS approaches suffer from feasibility and scalability concerns due to the need to intricately tailor the sampler to the underlying probability distribution and the objective. This challenge is overcome in the proposed black-box scheme by automating the selection of an effective IS distribution with a transformation that implicitly learns and replicates the concentration properties observed in less rare samples. This novel approach is guided by a large deviations principle that brings out the phenomenon of self-similarity of optimal IS distributions. The proposed sampler is the first to attain asymptotically optimal variance reduction across a spectrum of multivariate distributions despite being oblivious to the underlying structure. The large deviations principle additionally results in new distribution tail asymptotics capable of yielding operational insights. The applicability is illustrated by considering product distribution networks and portfolio credit risk models informed by neural networks as examples.
Confidence Regions in Wasserstein Distributionally Robust Estimation
Jun 04, 2019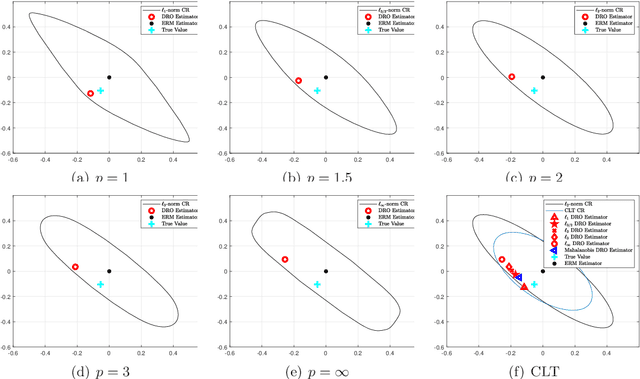
Wasserstein distributionally robust optimization (DRO) estimators are obtained as solutions of min-max problems in which the statistician selects a parameter minimizing the worst-case loss among all probability models within a certain distance (in a Wasserstein sense) from the underlying empirical measure. While motivated by the need to identify model parameters (or) decision choices that are robust to model uncertainties and misspecification, the Wasserstein DRO estimators recover a wide range of regularized estimators, including square-root LASSO and support vector machines, among others, as particular cases. This paper studies the asymptotic normality of underlying DRO estimators as well as the properties of an optimal (in a suitable sense) confidence region induced by the Wasserstein DRO formulation.
Data-driven Optimal Transport Cost Selection for Distributionally Robust Optimizatio
May 19, 2017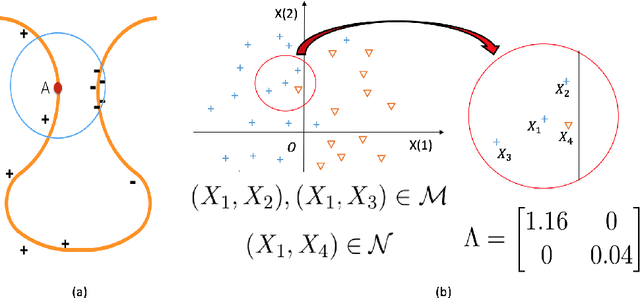
Recently, (Blanchet, Kang, and Murhy 2016) showed that several machine learning algorithms, such as square-root Lasso, Support Vector Machines, and regularized logistic regression, among many others, can be represented exactly as distributionally robust optimization (DRO) problems. The distributional uncertainty is defined as a neighborhood centered at the empirical distribution. We propose a methodology which learns such neighborhood in a natural data-driven way. We show rigorously that our framework encompasses adaptive regularization as a particular case. Moreover, we demonstrate empirically that our proposed methodology is able to improve upon a wide range of popular machine learning estimators.