 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Shapley Network: A Probabilistic Approach to Self-Explaining Shapley values with Uncertainty Quantification
Feb 06, 2024Shapley values have emerged as a foundational tool in machine learning (ML) for elucidating model decision-making processes. Despite their widespread adoption and unique ability to satisfy essential explainability axioms, computational challenges persist in their estimation when ($i$) evaluating a model over all possible subset of input feature combinations, ($ii$) estimating model marginals, and ($iii$) addressing variability in explanations. We introduce a novel, self-explaining method that simplifies the computation of Shapley values significantly, requiring only a single forward pass. Recognizing the deterministic treatment of Shapley values as a limitation, we explore incorporating a probabilistic framework to capture the inherent uncertainty in explanations. Unlike alternatives, our technique does not rely directly on the observed data space to estimate marginals; instead, it uses adaptable baseline values derived from a latent, feature-specific embedding space, generated by a novel masked neural network architecture. Evaluations on simulated and real datasets underscore our technique's robust predictive and explanatory performance.
Maximum Likelihood Estimation of Flexible Survival Densities with Importance Sampling
Nov 03, 2023



Survival analysis is a widely-used technique for analyzing time-to-event data in the presence of censoring. In recent years, numerous survival analysis methods have emerged which scale to large datasets and relax traditional assumptions such as proportional hazards. These models, while being performant, are very sensitive to model hyperparameters including: (1) number of bins and bin size for discrete models and (2) number of cluster assignments for mixture-based models. Each of these choices requires extensive tuning by practitioners to achieve optimal performance. In addition, we demonstrate in empirical studies that: (1) optimal bin size may drastically differ based on the metric of interest (e.g., concordance vs brier score), and (2) mixture models may suffer from mode collapse and numerical instability. We propose a survival analysis approach which eliminates the need to tune hyperparameters such as mixture assignments and bin sizes, reducing the burden on practitioners. We show that the proposed approach matches or outperforms baselines on several real-world datasets.
A Coreset-based, Tempered Variational Posterior for Accurate and Scalable Stochastic Gaussian Process Inference
Nov 02, 2023


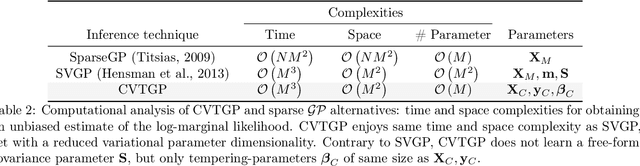
We present a novel stochastic variational Gaussian process ($\mathcal{GP}$) inference method, based on a posterior over a learnable set of weighted pseudo input-output points (coresets). Instead of a free-form variational family, the proposed coreset-based, variational tempered family for $\mathcal{GP}$s (CVTGP) is defined in terms of the $\mathcal{GP}$ prior and the data-likelihood; hence, accommodating the modeling inductive biases. We derive CVTGP's lower bound for the log-marginal likelihood via marginalization of the proposed posterior over latent $\mathcal{GP}$ coreset variables, and show it is amenable to stochastic optimization. CVTGP reduces the learnable parameter size to $\mathcal{O}(M)$, enjoys numerical stability, and maintains $\mathcal{O}(M^3)$ time- and $\mathcal{O}(M^2)$ space-complexity, by leveraging a coreset-based tempered posterior that, in turn, provides sparse and explainable representations of the data. Results on simulated and real-world regression problems with Gaussian observation noise validate that CVTGP provides better evidence lower-bound estimates and predictive root mean squared error than alternative stochastic $\mathcal{GP}$ inference methods.
CEHR-BERT: Incorporating temporal information from structured EHR data to improve prediction tasks
Nov 10, 2021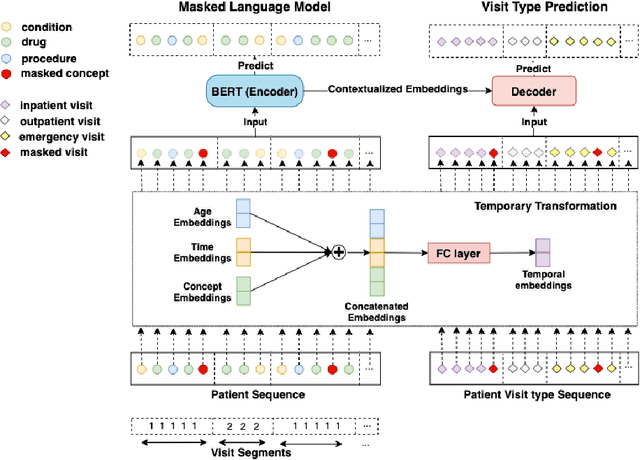


Embedding algorithms are increasingly used to represent clinical concepts in healthcare for improving machine learning tasks such as clinical phenotyping and disease prediction. Recent studies have adapted state-of-the-art bidirectional encoder representations from transformers (BERT) architecture to structured electronic health records (EHR) data for the generation of contextualized concept embeddings, yet do not fully incorporate temporal data across multiple clinical domains. Therefore we developed a new BERT adaptation, CEHR-BERT, to incorporate temporal information using a hybrid approach by augmenting the input to BERT using artificial time tokens, incorporating time, age, and concept embeddings, and introducing a new second learning objective for visit type. CEHR-BERT was trained on a subset of Columbia University Irving Medical Center-York Presbyterian Hospital's clinical data, which includes 2.4M patients, spanning over three decades, and tested using 4-fold cross-validation on the following prediction tasks: hospitalization, death, new heart failure (HF) diagnosis, and HF readmission. Our experiments show that CEHR-BERT outperformed existing state-of-the-art clinical BERT adaptations and baseline models across all 4 prediction tasks in both ROC-AUC and PR-AUC. CEHR-BERT also demonstrated strong transfer learning capability, as our model trained on only 5% of data outperformed comparison models trained on the entire data set. Ablation studies to better understand the contribution of each time component showed incremental gains with every element, suggesting that CEHR-BERT's incorporation of artificial time tokens, time and age embeddings with concept embeddings, and the addition of the second learning objective represents a promising approach for future BERT-based clinical embeddings.
Zero-Shot Clinical Acronym Expansion with a Hierarchical Metadata-Based Latent Variable Model
Sep 29, 2020
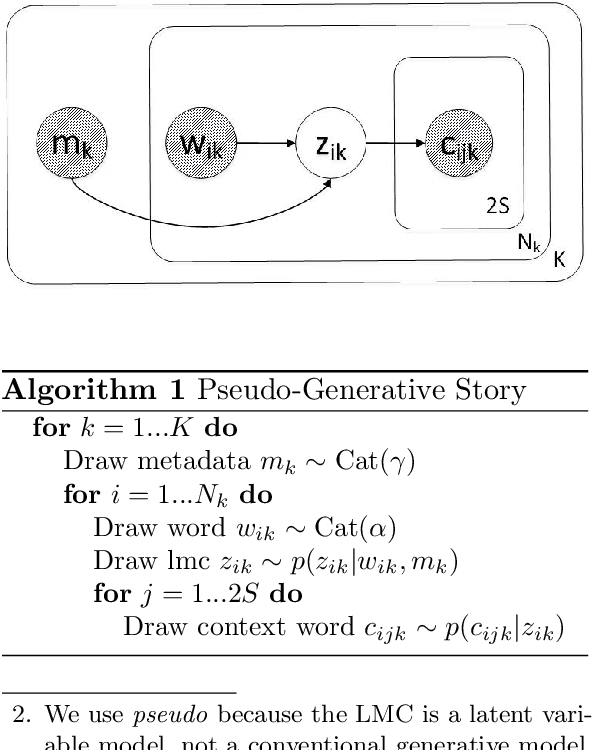
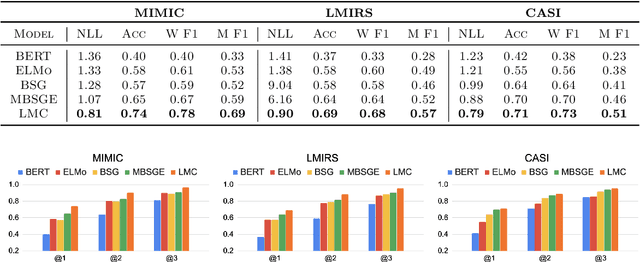

We introduce Latent Meaning Cells, a deep latent variable model which learns contextualized representations of words by combining local lexical context and metadata. Metadata can refer to granular context, such as section type, or to more global context, such as unique document ids. Reliance on metadata for contextualized representation learning is apropos in the clinical domain where text is semi-structured and expresses high variation in topics. We evaluate the LMC model on the task of clinical acronym expansion across three datasets. The LMC significantly outperforms a diverse set of baselines at a fraction of the pre-training cost and learns clinically coherent representations.
Phenotype inference with Semi-Supervised Mixed Membership Models
Dec 07, 2018

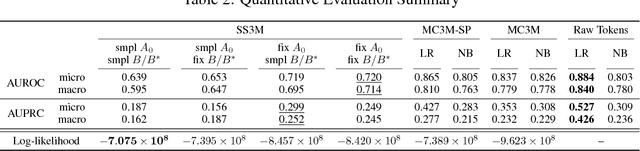
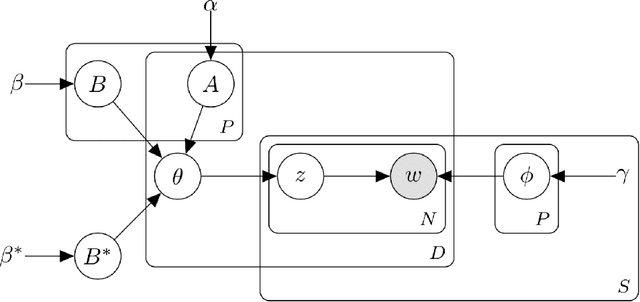
Disease phenotyping algorithms process observational clinical data to identify patients with specific diseases. Supervised phenotyping methods require significant quantities of expert-labeled data, while unsupervised methods may learn non-disease phenotypes. To address these limitations, we propose the Semi-Supervised Mixed Membership Model (SS3M) -- a probabilistic graphical model for learning disease phenotypes from clinical data with relatively few labels. We show SS3M can learn interpretable, disease-specific phenotypes which capture the clinical characteristics of the diseases specified by the labels provided.
Multiple Causal Inference with Latent Confounding
Aug 07, 2018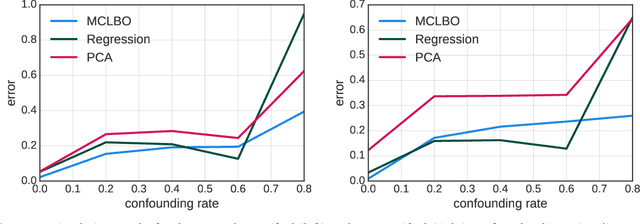
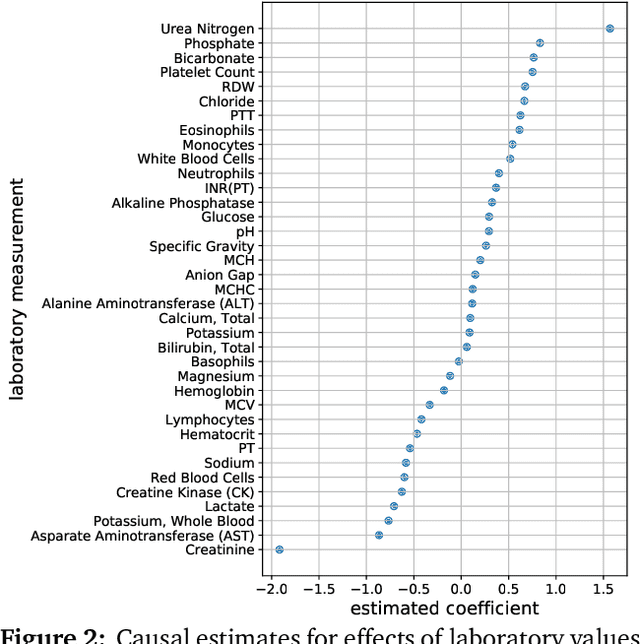
Causal inference from observational data requires assumptions. These assumptions range from measuring confounders to identifying instruments. Traditionally, these assumptions have focused on estimation in a single causal problem. In this work, we develop techniques for causal estimation in causal problems with multiple treatments. We develop two assumptions based on shared confounding between treatments and independence of treatments given the confounder. Together these assumptions lead to a confounder estimator regularized by mutual information. For this estimator, we develop a tractable lower bound. To fit the outcome model, we use the residual information in the treatments given the confounder. We validate on simulations and an example from clinical medicine.
Deep Survival Analysis
Sep 18, 2016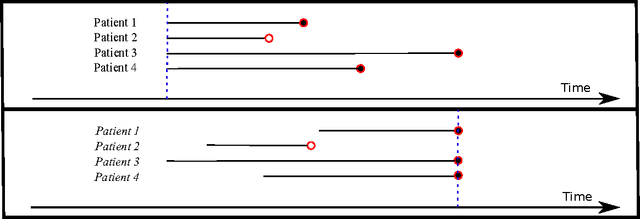
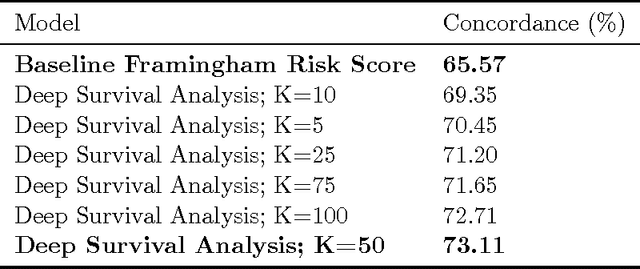

The electronic health record (EHR) provides an unprecedented opportunity to build actionable tools to support physicians at the point of care. In this paper, we investigate survival analysis in the context of EHR data. We introduce deep survival analysis, a hierarchical generative approach to survival analysis. It departs from previous approaches in two primary ways: (1) all observations, including covariates, are modeled jointly conditioned on a rich latent structure; and (2) the observations are aligned by their failure time, rather than by an arbitrary time zero as in traditional survival analysis. Further, it (3) scalably handles heterogeneous (continuous and discrete) data types that occur in the EHR. We validate deep survival analysis model by stratifying patients according to risk of developing coronary heart disease (CHD). Specifically, we study a dataset of 313,000 patients corresponding to 5.5 million months of observations. When compared to the clinically validated Framingham CHD risk score, deep survival analysis is significantly superior in stratifying patients according to their risk.