 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Likelihood Estimation of Flexible Survival Densities with Importance Sampling
Nov 03, 2023



Survival analysis is a widely-used technique for analyzing time-to-event data in the presence of censoring. In recent years, numerous survival analysis methods have emerged which scale to large datasets and relax traditional assumptions such as proportional hazards. These models, while being performant, are very sensitive to model hyperparameters including: (1) number of bins and bin size for discrete models and (2) number of cluster assignments for mixture-based models. Each of these choices requires extensive tuning by practitioners to achieve optimal performance. In addition, we demonstrate in empirical studies that: (1) optimal bin size may drastically differ based on the metric of interest (e.g., concordance vs brier score), and (2) mixture models may suffer from mode collapse and numerical instability. We propose a survival analysis approach which eliminates the need to tune hyperparameters such as mixture assignments and bin sizes, reducing the burden on practitioners. We show that the proposed approach matches or outperforms baselines on several real-world datasets.
Assessing Phenotype Definitions for Algorithmic Fairness
Mar 10, 2022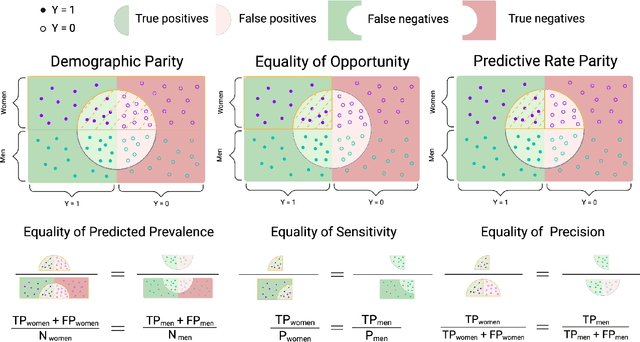
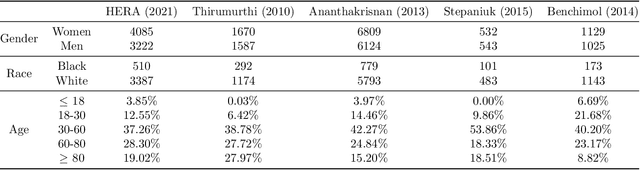
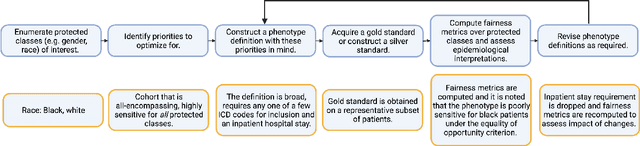
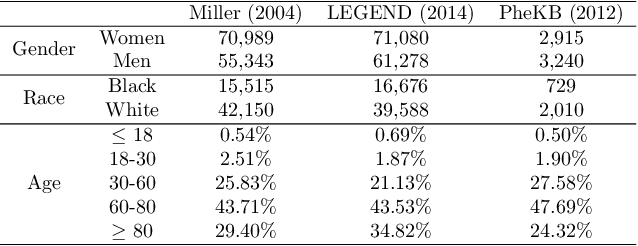
Disease identification is a core, routine activity in observational health research. Cohorts impact downstream analyses, such as how a condition is characterized, how patient risk is defined, and what treatments are studied. It is thus critical to ensure that selected cohorts are representative of all patients, independently of their demographics or social determinants of health. While there are multiple potential sources of bias when constructing phenotype definitions which may affect their fairness, it is not standard in the field of phenotyping to consider the impact of different definitions across subgroups of patients. In this paper, we propose a set of best practices to assess the fairness of phenotype definitions. We leverage established fairness metrics commonly used in predictive models and relate them to commonly used epidemiological cohort description metrics. We describe an empirical study for Crohn's disease and diabetes type 2, each with multiple phenotype definitions taken from the literature across two sets of patient subgroups (gender and race). We show that the different phenotype definitions exhibit widely varying and disparate performance according to the different fairness metrics and subgroups. We hope that the proposed best practices can help in constructing fair and inclusive phenotype definitions.