 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelation Robust Influence Maximization
Oct 24, 2020
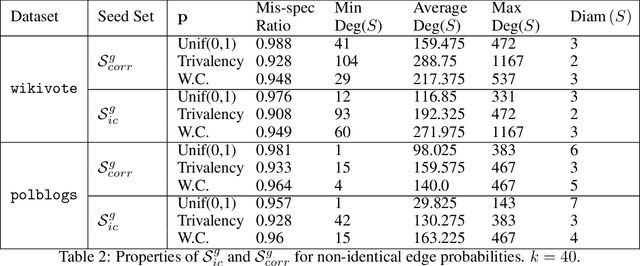
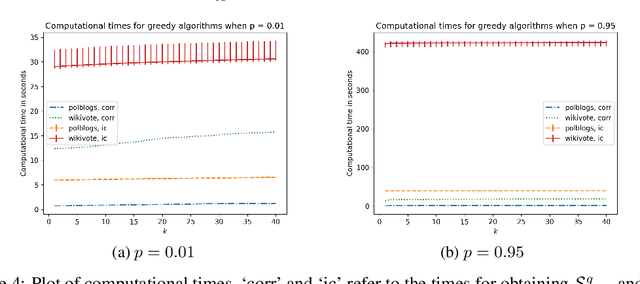

We propose a distributionally robust model for the influence maximization problem. Unlike the classic independent cascade model \citep{kempe2003maximizing}, this model's diffusion process is adversarially adapted to the choice of seed set. Hence, instead of optimizing under the assumption that all influence relationships in the network are independent, we seek a seed set whose expected influence under the worst correlation, i.e. the "worst-case, expected influence", is maximized. We show that this worst-case influence can be efficiently computed, and though the optimization is NP-hard, a ($1 - 1/e$) approximation guarantee holds. We also analyze the structure to the adversary's choice of diffusion process, and contrast with established models. Beyond the key computational advantages, we also highlight the extent to which the independence assumption may cost optimality, and provide insights from numerical experiments comparing the adversarial and independent cascade model.
Topic Model Based Multi-Label Classification from the Crowd
Apr 04, 2016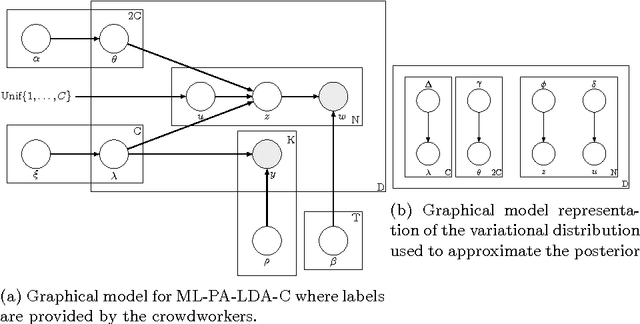
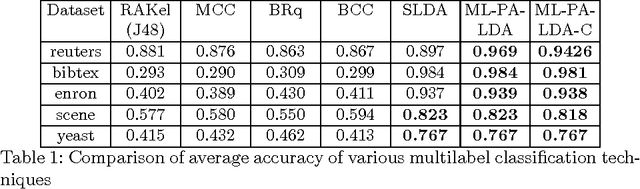
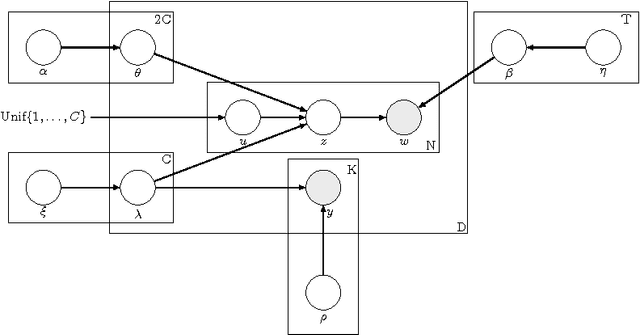
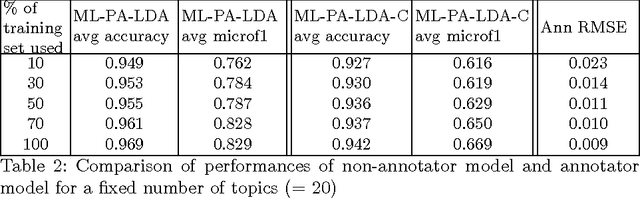
Multi-label classification is a common supervised machine learning problem where each instance is associated with multiple classes. The key challenge in this problem is learning the correlations between the classes. An additional challenge arises when the labels of the training instances are provided by noisy, heterogeneous crowdworkers with unknown qualities. We first assume labels from a perfect source and propose a novel topic model where the present as well as the absent classes generate the latent topics and hence the words. We non-trivially extend our topic model to the scenario where the labels are provided by noisy crowdworkers. Extensive experimentation on real world datasets reveals the superior performance of the proposed model. The proposed model learns the qualities of the annotators as well, even with minimal training data.
A Truthful Mechanism with Biparameter Learning for Online Crowdsourcing
Feb 12, 2016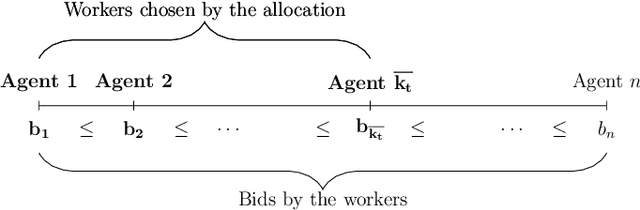
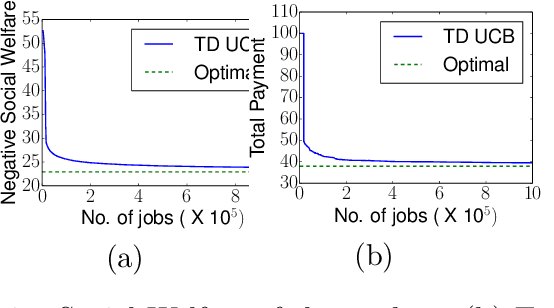
We study a problem of allocating divisible jobs, arriving online, to workers in a crowdsourcing setting which involves learning two parameters of strategically behaving workers. Each job is split into a certain number of tasks that are then allocated to workers. Each arriving job has to be completed within a deadline and each task has to be completed satisfying an upper bound on probability of failure. The job population is homogeneous while the workers are heterogeneous in terms of costs, completion times, and times to failure. The job completion time and time to failure of each worker are stochastic with fixed but unknown means. The requester is faced with the challenge of learning two separate parameters of each (strategically behaving) worker simultaneously, namely, the mean job completion time and the mean time to failure. The time to failure of a worker depends on the duration of the task handled by the worker. Assuming non-strategic workers to start with, we solve this biparameter learning problem by applying the Robust UCB algorithm. Then, we non-trivially extend this algorithm to the setting where the workers are strategic about their costs. Our proposed mechanism is dominant strategy incentive compatible and ex-post individually rational with asymptotically optimal regret performance.
A Robust UCB Scheme for Active Learning in Regression from Strategic Crowds
Jan 29, 2016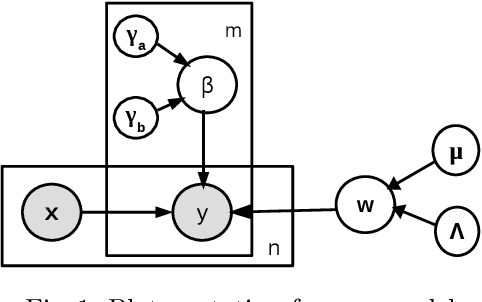
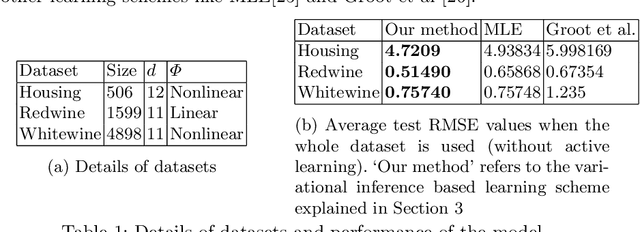
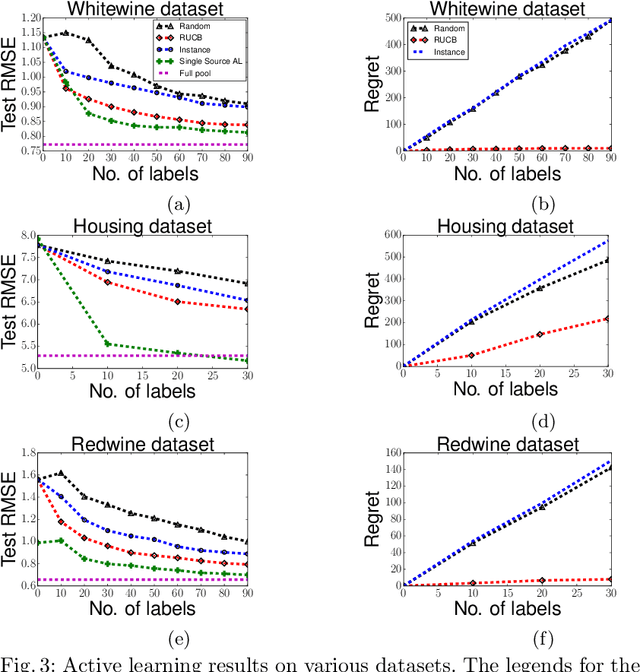
We study the problem of training an accurate linear regression model by procuring labels from multiple noisy crowd annotators, under a budget constraint. We propose a Bayesian model for linear regression in crowdsourcing and use variational inference for parameter estimation. To minimize the number of labels crowdsourced from the annotators, we adopt an active learning approach. In this specific context, we prove the equivalence of well-studied criteria of active learning like entropy minimization and expected error reduction. Interestingly, we observe that we can decouple the problems of identifying an optimal unlabeled instance and identifying an annotator to label it. We observe a useful connection between the multi-armed bandit framework and the annotator selection in active learning. Due to the nature of the distribution of the rewards on the arms, we use the Robust Upper Confidence Bound (UCB) scheme with truncated empirical mean estimator to solve the annotator selection problem. This yields provable guarantees on the regret. We further apply our model to the scenario where annotators are strategic and design suitable incentives to induce them to put in their best efforts.