 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic Model Based Multi-Label Classification from the Crowd
Paper and Code
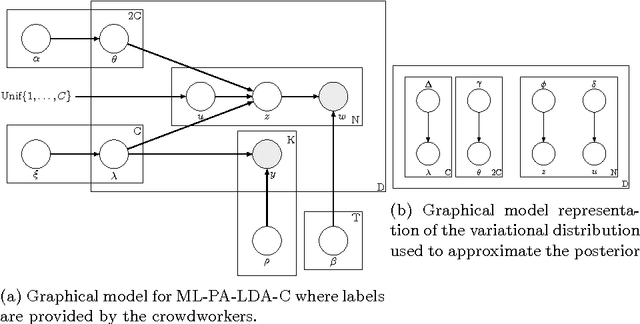
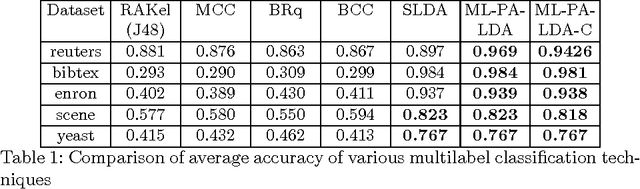
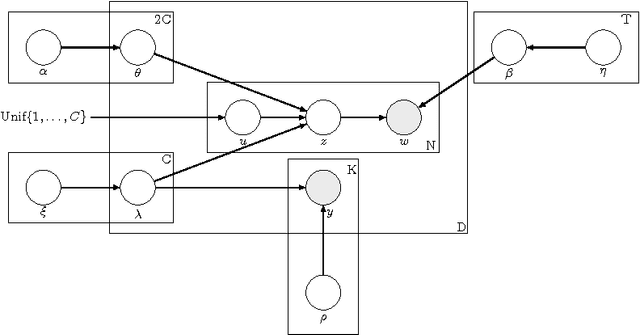
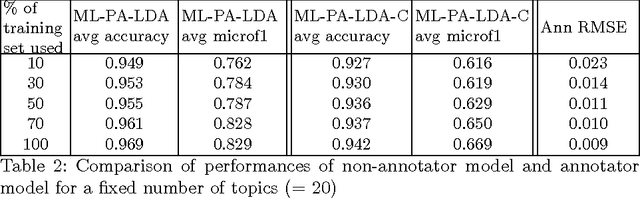
Multi-label classification is a common supervised machine learning problem where each instance is associated with multiple classes. The key challenge in this problem is learning the correlations between the classes. An additional challenge arises when the labels of the training instances are provided by noisy, heterogeneous crowdworkers with unknown qualities. We first assume labels from a perfect source and propose a novel topic model where the present as well as the absent classes generate the latent topics and hence the words. We non-trivially extend our topic model to the scenario where the labels are provided by noisy crowdworkers. Extensive experimentation on real world datasets reveals the superior performance of the proposed model. The proposed model learns the qualities of the annotators as well, even with minimal training data.