 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersian Keyphrase Generation Using Sequence-to-Sequence Models
Sep 25, 2020Keyphrases are a very short summary of an input text and provide the main subjects discussed in the text. Keyphrase extraction is a useful upstream task and can be used in various natural language processing problems, for example, text summarization and information retrieval, to name a few. However, not all the keyphrases are explicitly mentioned in the body of the text. In real-world examples there are always some topics that are discussed implicitly. Extracting such keyphrases requires a generative approach, which is adopted here. In this paper, we try to tackle the problem of keyphrase generation and extraction from news articles using deep sequence-to-sequence models. These models significantly outperform the conventional methods such as Topic Rank, KPMiner, and KEA in the task of keyphrase extraction.
PerKey: A Persian News Corpus for Keyphrase Extraction and Generation
Sep 25, 2020
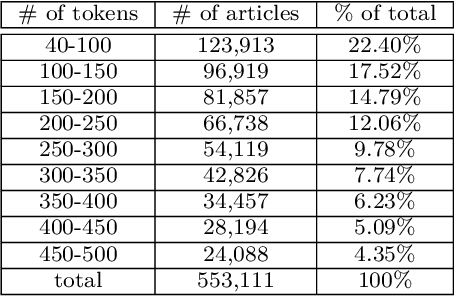
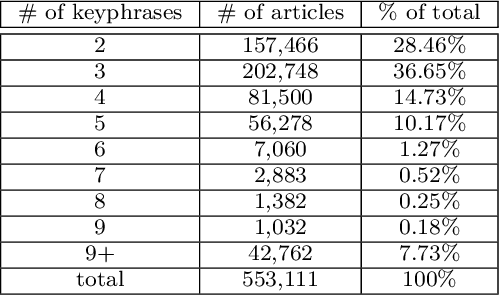
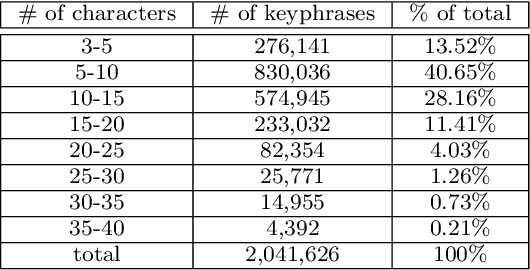
Keyphrases provide an extremely dense summary of a text. Such information can be used in many Natural Language Processing tasks, such as information retrieval and text summarization. Since previous studies on Persian keyword or keyphrase extraction have not published their data, the field suffers from the lack of a human extracted keyphrase dataset. In this paper, we introduce PerKey, a corpus of 553k news articles from six Persian news websites and agencies with relatively high quality author extracted keyphrases, which is then filtered and cleaned to achieve higher quality keyphrases. The resulted data was put into human assessment to ensure the quality of the keyphrases. We also measured the performance of different supervised and unsupervised techniques, e.g. TFIDF, MultipartiteRank, KEA, etc. on the dataset using precision, recall, and F1-score.