 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Factual Recall Mechanisms Carry over from Text to Speech in Multimodal Language Models?
May 21, 2026In recent years, several Speech Language Models (SLMs) that represent speech and written text jointly have been presented. The question then emerges about how model-internal mechanisms are similar and different when operating in the two modalities. We focus on how these systems encode, store, and retrieve factual knowledge, which has previously been investigated for text-only models. To investigate mechanisms behind the storage and recall of factual association in SLMs, we leverage Causal Mediation Analysis, a technique previously applied to text-based models. Initial results using SpiritLM, a multimodal model integrating discrete speech tokens reveal discrepancies between text-to-text and speech-to-text results, suggesting that the emergent mechanisms for factual recall are only partially carried over from the text to the speech modality. These results advance our understanding of how internal mechanisms encode factual associations in SLMs while contributing insights for improving speech-enabled AI systems.
To Copy or Not to Copy: Copying Is Easier to Induce Than Recall
Jan 17, 2026Language models used in retrieval-augmented settings must arbitrate between parametric knowledge stored in their weights and contextual information in the prompt. This work presents a mechanistic study of that choice by extracting an \emph{arbitration vector} from model activations on a curated dataset designed to disentangle (i) irrelevant contexts that elicit parametric recall and (ii) relevant but false contexts that elicit copying. The vector is computed as the residual-stream centroid difference between these regimes across 27 relations, and is injected as an additive intervention at selected layers and token spans to steer behavior in two directions: Copy$\rightarrow$Recall (suppressing context use) and Recall$\rightarrow$Copy (inducing the model to copy any token from the context). Experiments on two architectures (decoder-only and encoder/decoder) and two open-domain QA benchmarks show consistent behavior shifts under moderate scaling while monitoring accuracy and fluency. Mechanistic analyses of attention routing, MLP contributions, and layer-wise probability trajectories reveal an asymmetry: inducing copying is an easy ``reactivation'' process that can be triggered at different locations in the input, while restoring recall is a ``suppression'' process that is more fragile and strongly tied to object-token interventions.
Deciphering the Interplay of Parametric and Non-parametric Memory in Retrieval-augmented Language Models
Oct 07, 2024Generative language models often struggle with specialized or less-discussed knowledge. A potential solution is found in Retrieval-Augmented Generation (RAG) models which act like retrieving information before generating responses. In this study, we explore how the \textsc{Atlas} approach, a RAG model, decides between what it already knows (parametric) and what it retrieves (non-parametric). We use causal mediation analysis and controlled experiments to examine how internal representations influence information processing. Our findings disentangle the effects of parametric knowledge and the retrieved context. They indicate that in cases where the model can choose between both types of information (parametric and non-parametric), it relies more on the context than the parametric knowledge. Furthermore, the analysis investigates the computations involved in \emph{how} the model uses the information from the context. We find that multiple mechanisms are active within the model and can be detected with mediation analysis: first, the decision of \emph{whether the context is relevant}, and second, how the encoder computes output representations to support copying when relevant.
Analysing the Behaviour of Tree-Based Neural Networks in Regression Tasks
Jun 17, 2024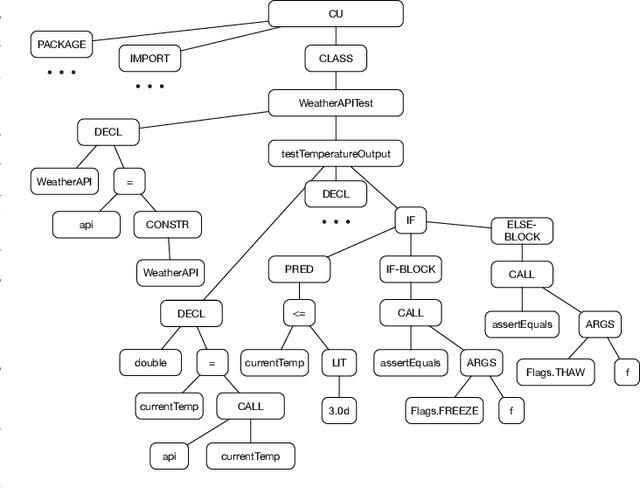



The landscape of deep learning has vastly expanded the frontiers of source code analysis, particularly through the utilization of structural representations such as Abstract Syntax Trees (ASTs). While these methodologies have demonstrated effectiveness in classification tasks, their efficacy in regression applications, such as execution time prediction from source code, remains underexplored. This paper endeavours to decode the behaviour of tree-based neural network models in the context of such regression challenges. We extend the application of established models--tree-based Convolutional Neural Networks (CNNs), Code2Vec, and Transformer-based methods--to predict the execution time of source code by parsing it to an AST. Our comparative analysis reveals that while these models are benchmarks in code representation, they exhibit limitations when tasked with regression. To address these deficiencies, we propose a novel dual-transformer approach that operates on both source code tokens and AST representations, employing cross-attention mechanisms to enhance interpretability between the two domains. Furthermore, we explore the adaptation of Graph Neural Networks (GNNs) to this tree-based problem, theorizing the inherent compatibility due to the graphical nature of ASTs. Empirical evaluations on real-world datasets showcase that our dual-transformer model outperforms all other tree-based neural networks and the GNN-based models. Moreover, our proposed dual transformer demonstrates remarkable adaptability and robust performance across diverse datasets.
An Empirical Study of Multitask Learning to Improve Open Domain Dialogue Systems
Apr 17, 2023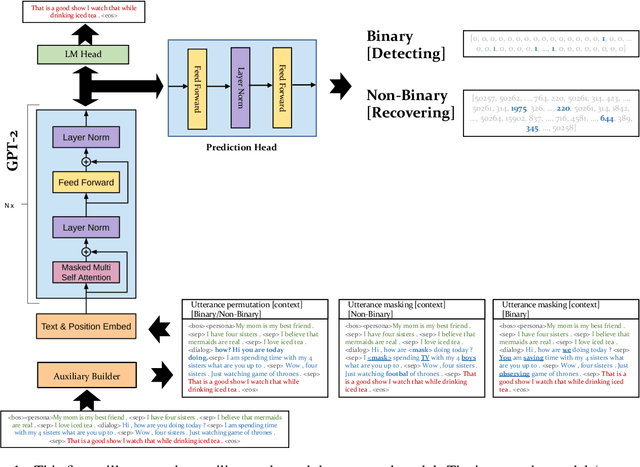
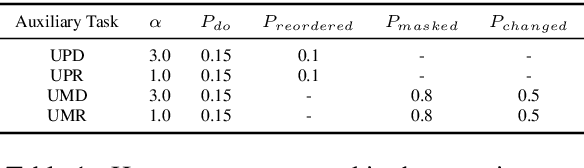
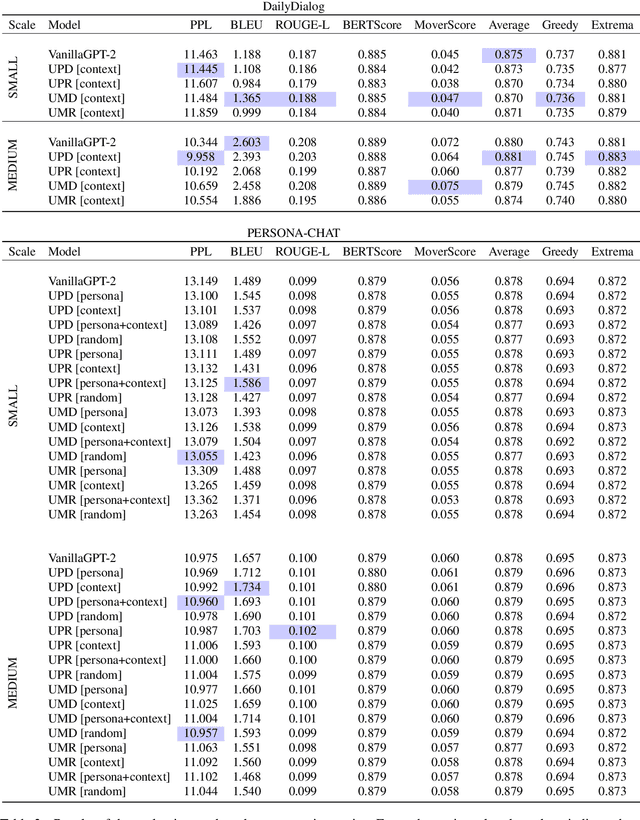
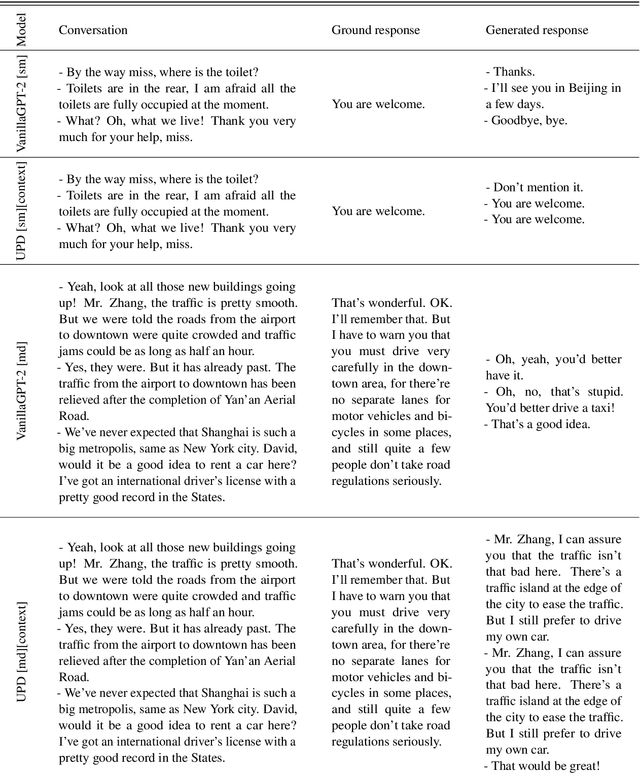
Autoregressive models used to generate responses in open-domain dialogue systems often struggle to take long-term context into account and to maintain consistency over a dialogue. Previous research in open-domain dialogue generation has shown that the use of \emph{auxiliary tasks} can introduce inductive biases that encourage the model to improve these qualities. However, most previous research has focused on encoder-only or encoder/decoder models, while the use of auxiliary tasks in \emph{decoder-only} autoregressive models is under-explored. This paper describes an investigation where four different auxiliary tasks are added to small and medium-sized GPT-2 models fine-tuned on the PersonaChat and DailyDialog datasets. The results show that the introduction of the new auxiliary tasks leads to small but consistent improvement in evaluations of the investigated models.
Leveraging ParsBERT and Pretrained mT5 for Persian Abstractive Text Summarization
Dec 21, 2020
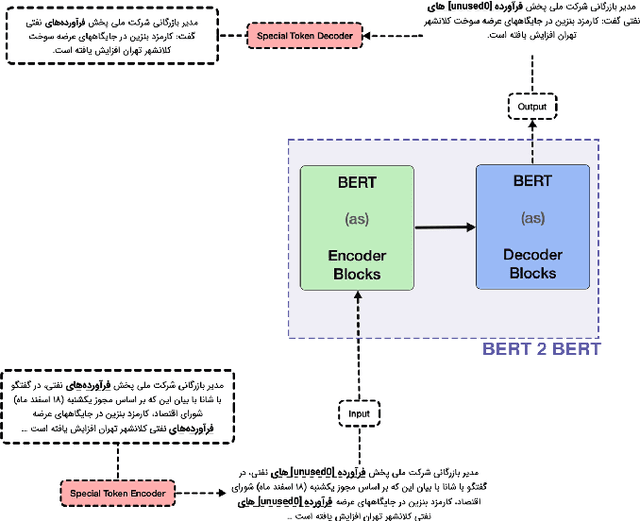
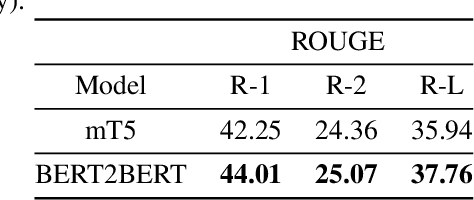
Text summarization is one of the most critical Natural Language Processing (NLP) tasks. More and more researches are conducted in this field every day. Pre-trained transformer-based encoder-decoder models have begun to gain popularity for these tasks. This paper proposes two methods to address this task and introduces a novel dataset named pn-summary for Persian abstractive text summarization. The models employed in this paper are mT5 and an encoder-decoder version of the ParsBERT model (i.e., a monolingual BERT model for Persian). These models are fine-tuned on the pn-summary dataset. The current work is the first of its kind and, by achieving promising results, can serve as a baseline for any future work.
ParsBERT: Transformer-based Model for Persian Language Understanding
May 31, 2020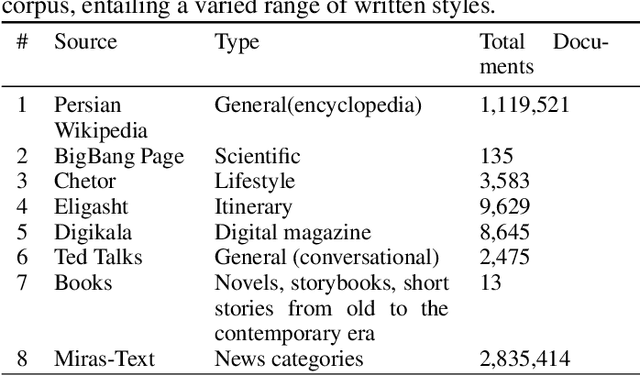
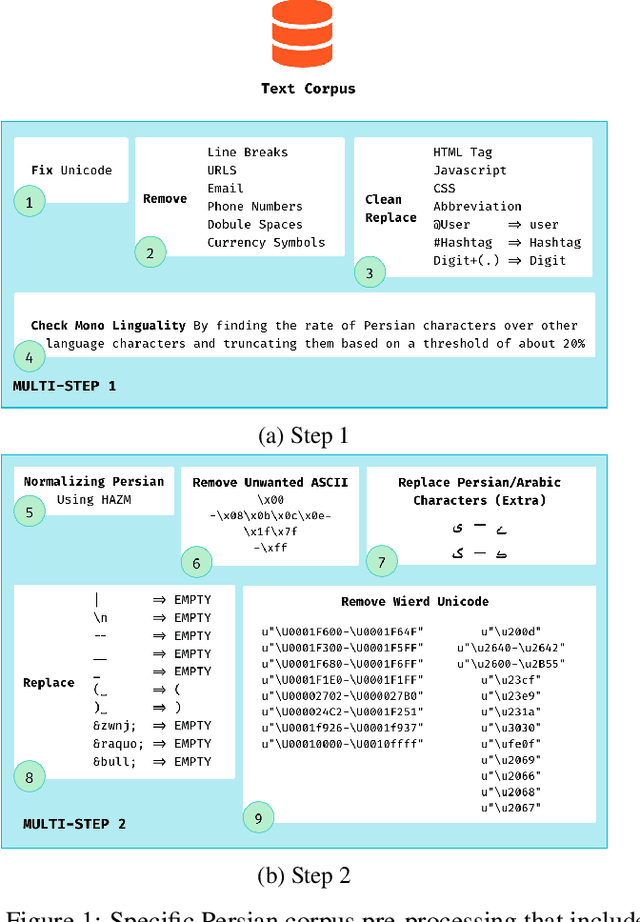
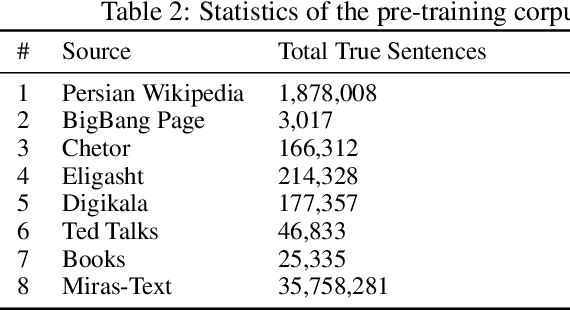
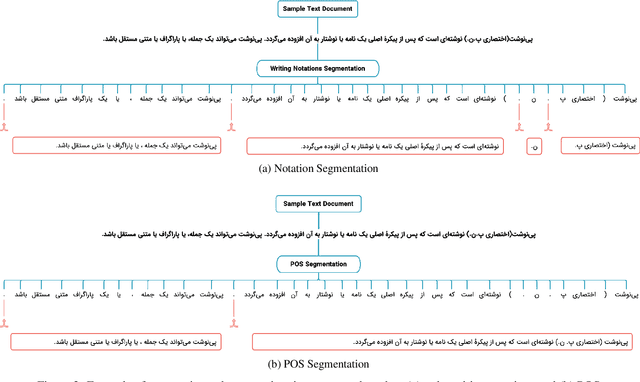
The surge of pre-trained language models has begun a new era in the field of Natural Language Processing (NLP) by allowing us to build powerful language models. Among these models, Transformer-based models such as BERT have become increasingly popular due to their state-of-the-art performance. However, these models are usually focused on English, leaving other languages to multilingual models with limited resources. This paper proposes a monolingual BERT for the Persian language (ParsBERT), which shows its state-of-the-art performance compared to other architectures and multilingual models. Also, since the amount of data available for NLP tasks in Persian is very restricted, a massive dataset for different NLP tasks as well as pre-training the model is composed. ParsBERT obtains higher scores in all datasets, including existing ones as well as composed ones and improves the state-of-the-art performance by outperforming both multilingual BERT and other prior works in Sentiment Analysis, Text Classification and Named Entity Recognition tasks.
Short-Term Traffic Flow Prediction Using Variational LSTM Networks
Feb 18, 2020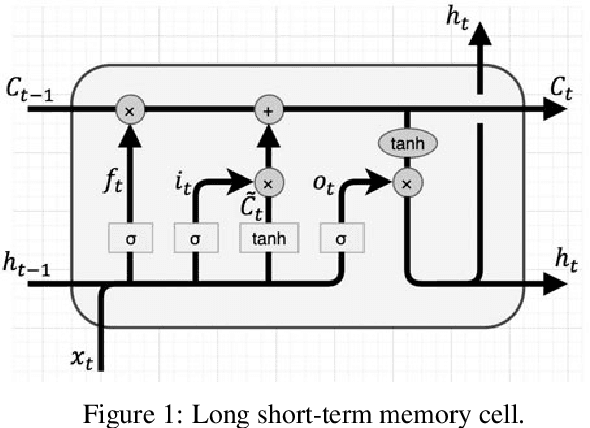

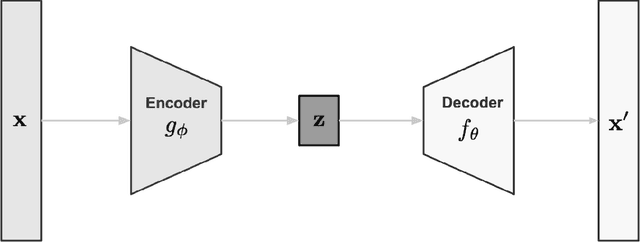

Traffic flow characteristics are one of the most critical decision-making and traffic policing factors in a region. Awareness of the predicted status of the traffic flow has prime importance in traffic management and traffic information divisions. The purpose of this research is to suggest a forecasting model for traffic flow by using deep learning techniques based on historical data in the Intelligent Transportation Systems area. The historical data collected from the Caltrans Performance Measurement Systems (PeMS) for six months in 2019. The proposed prediction model is a Variational Long Short-Term Memory Encoder in brief VLSTM-E try to estimate the flow accurately in contrast to other conventional methods. VLSTM-E can provide more reliable short-term traffic flow by considering the distribution and missing values.