 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysing the Behaviour of Tree-Based Neural Networks in Regression Tasks
Paper and Code
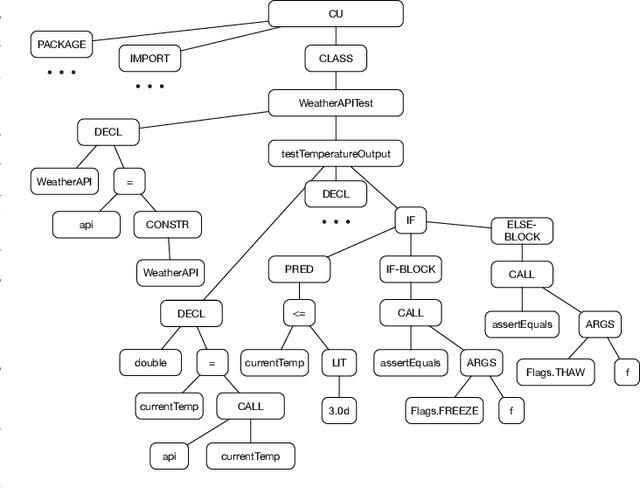



The landscape of deep learning has vastly expanded the frontiers of source code analysis, particularly through the utilization of structural representations such as Abstract Syntax Trees (ASTs). While these methodologies have demonstrated effectiveness in classification tasks, their efficacy in regression applications, such as execution time prediction from source code, remains underexplored. This paper endeavours to decode the behaviour of tree-based neural network models in the context of such regression challenges. We extend the application of established models--tree-based Convolutional Neural Networks (CNNs), Code2Vec, and Transformer-based methods--to predict the execution time of source code by parsing it to an AST. Our comparative analysis reveals that while these models are benchmarks in code representation, they exhibit limitations when tasked with regression. To address these deficiencies, we propose a novel dual-transformer approach that operates on both source code tokens and AST representations, employing cross-attention mechanisms to enhance interpretability between the two domains. Furthermore, we explore the adaptation of Graph Neural Networks (GNNs) to this tree-based problem, theorizing the inherent compatibility due to the graphical nature of ASTs. Empirical evaluations on real-world datasets showcase that our dual-transformer model outperforms all other tree-based neural networks and the GNN-based models. Moreover, our proposed dual transformer demonstrates remarkable adaptability and robust performance across diverse datasets.