 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark Dataset for Graph Regression with Homogeneous and Multi-Relational Variants
May 29, 2025



Graph-level regression underpins many real-world applications, yet public benchmarks remain heavily skewed toward molecular graphs and citation networks. This limited diversity hinders progress on models that must generalize across both homogeneous and heterogeneous graph structures. We introduce RelSC, a new graph-regression dataset built from program graphs that combine syntactic and semantic information extracted from source code. Each graph is labelled with the execution-time cost of the corresponding program, providing a continuous target variable that differs markedly from those found in existing benchmarks. RelSC is released in two complementary variants. RelSC-H supplies rich node features under a single (homogeneous) edge type, while RelSC-M preserves the original multi-relational structure, connecting nodes through multiple edge types that encode distinct semantic relationships. Together, these variants let researchers probe how representation choice influences model behaviour. We evaluate a diverse set of graph neural network architectures on both variants of RelSC. The results reveal consistent performance differences between the homogeneous and multi-relational settings, emphasising the importance of structural representation. These findings demonstrate RelSC's value as a challenging and versatile benchmark for advancing graph regression methods.
Analysing the Behaviour of Tree-Based Neural Networks in Regression Tasks
Jun 17, 2024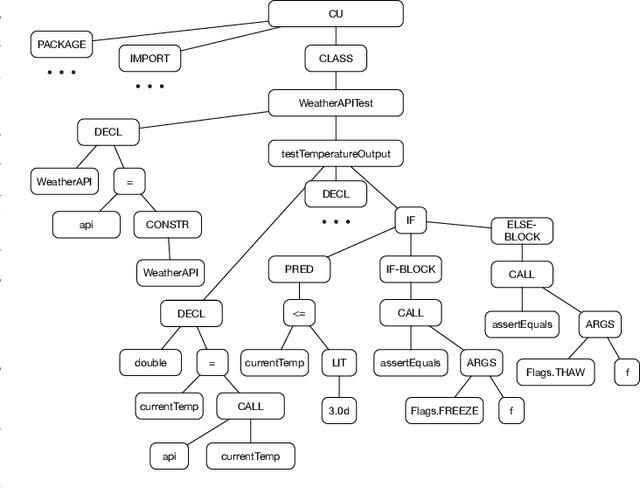



The landscape of deep learning has vastly expanded the frontiers of source code analysis, particularly through the utilization of structural representations such as Abstract Syntax Trees (ASTs). While these methodologies have demonstrated effectiveness in classification tasks, their efficacy in regression applications, such as execution time prediction from source code, remains underexplored. This paper endeavours to decode the behaviour of tree-based neural network models in the context of such regression challenges. We extend the application of established models--tree-based Convolutional Neural Networks (CNNs), Code2Vec, and Transformer-based methods--to predict the execution time of source code by parsing it to an AST. Our comparative analysis reveals that while these models are benchmarks in code representation, they exhibit limitations when tasked with regression. To address these deficiencies, we propose a novel dual-transformer approach that operates on both source code tokens and AST representations, employing cross-attention mechanisms to enhance interpretability between the two domains. Furthermore, we explore the adaptation of Graph Neural Networks (GNNs) to this tree-based problem, theorizing the inherent compatibility due to the graphical nature of ASTs. Empirical evaluations on real-world datasets showcase that our dual-transformer model outperforms all other tree-based neural networks and the GNN-based models. Moreover, our proposed dual transformer demonstrates remarkable adaptability and robust performance across diverse datasets.
A Unified Active Learning Framework for Annotating Graph Data with Application to Software Source Code Performance Prediction
Apr 06, 2023



Most machine learning and data analytics applications, including performance engineering in software systems, require a large number of annotations and labelled data, which might not be available in advance. Acquiring annotations often requires significant time, effort, and computational resources, making it challenging. We develop a unified active learning framework, specializing in software performance prediction, to address this task. We begin by parsing the source code to an Abstract Syntax Tree (AST) and augmenting it with data and control flow edges. Then, we convert the tree representation of the source code to a Flow Augmented-AST graph (FA-AST) representation. Based on the graph representation, we construct various graph embeddings (unsupervised and supervised) into a latent space. Given such an embedding, the framework becomes task agnostic since active learning can be performed using any regression method and query strategy suited for regression. Within this framework, we investigate the impact of using different levels of information for active and passive learning, e.g., partially available labels and unlabeled test data. Our approach aims to improve the investment in AI models for different software performance predictions (execution time) based on the structure of the source code. Our real-world experiments reveal that respectable performance can be achieved by querying labels for only a small subset of all the data.