 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFABench: A Generic Framework for Benchmarking Active Feature Acquisition
Aug 20, 2025



In many real-world scenarios, acquiring all features of a data instance can be expensive or impractical due to monetary cost, latency, or privacy concerns. Active Feature Acquisition (AFA) addresses this challenge by dynamically selecting a subset of informative features for each data instance, trading predictive performance against acquisition cost. While numerous methods have been proposed for AFA, ranging from greedy information-theoretic strategies to non-myopic reinforcement learning approaches, fair and systematic evaluation of these methods has been hindered by the lack of standardized benchmarks. In this paper, we introduce AFABench, the first benchmark framework for AFA. Our benchmark includes a diverse set of synthetic and real-world datasets, supports a wide range of acquisition policies, and provides a modular design that enables easy integration of new methods and tasks. We implement and evaluate representative algorithms from all major categories, including static, greedy, and reinforcement learning-based approaches. To test the lookahead capabilities of AFA policies, we introduce a novel synthetic dataset, AFAContext, designed to expose the limitations of greedy selection. Our results highlight key trade-offs between different AFA strategies and provide actionable insights for future research. The benchmark code is available at: https://github.com/Linusaronsson/AFA-Benchmark.
An Efficient Local Search Approach for Polarized Community Discovery in Signed Networks
Feb 04, 2025Signed networks, where edges are labeled as positive or negative to indicate friendly or antagonistic interactions, offer a natural framework for studying polarization, trust, and conflict in social systems. Detecting meaningful group structures in these networks is crucial for understanding online discourse, political division, and trust dynamics. A key challenge is to identify groups that are cohesive internally yet antagonistic externally, while allowing for neutral or unaligned vertices. In this paper, we address this problem by identifying $k$ polarized communities that are large, dense, and balanced in size. We develop an approach based on Frank-Wolfe optimization, leading to a local search procedure with provable convergence guarantees. Our method is both scalable and efficient, outperforming state-of-the-art baselines in solution quality while remaining competitive in terms of computational efficiency.
Effective Acquisition Functions for Active Correlation Clustering
Feb 05, 2024Correlation clustering is a powerful unsupervised learning paradigm that supports positive and negative similarities. In this paper, we assume the similarities are not known in advance. Instead, we employ active learning to iteratively query similarities in a cost-efficient way. In particular, we develop three effective acquisition functions to be used in this setting. One is based on the notion of inconsistency (i.e., when similarities violate the transitive property). The remaining two are based on information-theoretic quantities, i.e., entropy and information gain.
A Unified Active Learning Framework for Annotating Graph Data with Application to Software Source Code Performance Prediction
Apr 06, 2023



Most machine learning and data analytics applications, including performance engineering in software systems, require a large number of annotations and labelled data, which might not be available in advance. Acquiring annotations often requires significant time, effort, and computational resources, making it challenging. We develop a unified active learning framework, specializing in software performance prediction, to address this task. We begin by parsing the source code to an Abstract Syntax Tree (AST) and augmenting it with data and control flow edges. Then, we convert the tree representation of the source code to a Flow Augmented-AST graph (FA-AST) representation. Based on the graph representation, we construct various graph embeddings (unsupervised and supervised) into a latent space. Given such an embedding, the framework becomes task agnostic since active learning can be performed using any regression method and query strategy suited for regression. Within this framework, we investigate the impact of using different levels of information for active and passive learning, e.g., partially available labels and unlabeled test data. Our approach aims to improve the investment in AI models for different software performance predictions (execution time) based on the structure of the source code. Our real-world experiments reveal that respectable performance can be achieved by querying labels for only a small subset of all the data.
Active Learning with Positive and Negative Pairwise Feedback
Feb 22, 2023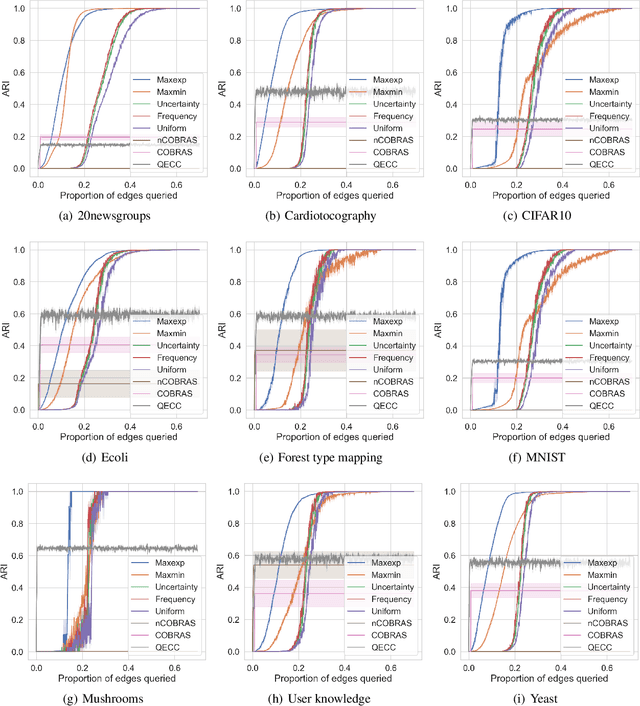

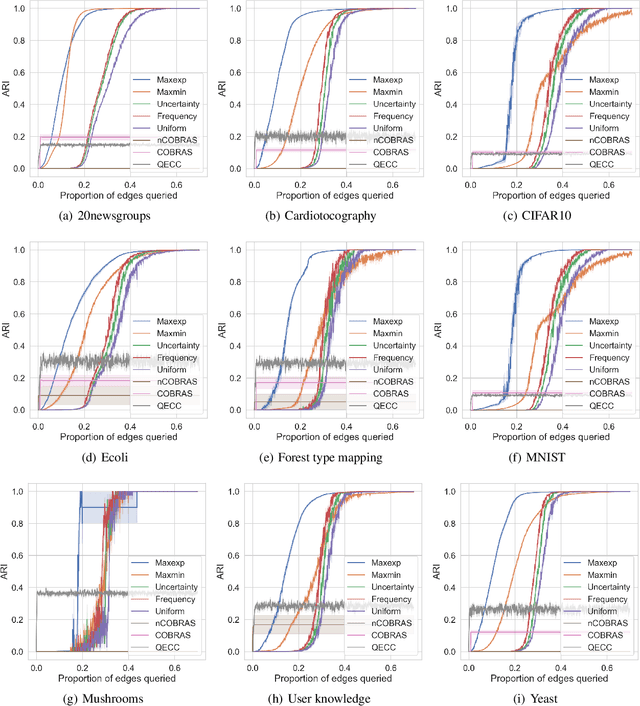
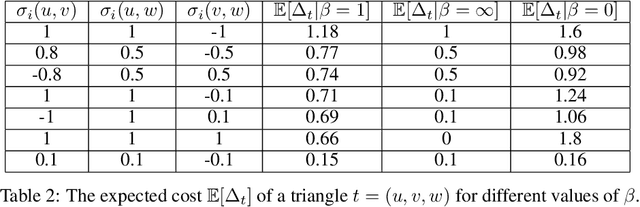
In this paper, we propose a generic framework for active clustering with queries for pairwise similarities between objects. First, the pairwise similarities can be any positive or negative number, yielding full flexibility in the type of feedback that a user/annotator can provide. Second, the process of querying pairwise similarities is separated from the clustering algorithm, leading to more flexibility in how the query strategies can be constructed. Third, the queries are robust to noise by allowing multiple queries for the same pairwise similarity (i.e., a non-persistent noise model is assumed). Finally, the number of clusters is automatically identified based on the currently known pairwise similarities. In addition, we propose and analyze a number of novel query strategies suited to this active clustering framework. We demonstrate the effectiveness of our framework and the proposed query strategies via several experimental studies.