 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Prompt Programming on Function-Level Code Generation
Dec 29, 2024Large Language Models (LLMs) are increasingly used by software engineers for code generation. However, limitations of LLMs such as irrelevant or incorrect code have highlighted the need for prompt programming (or prompt engineering) where engineers apply specific prompt techniques (e.g., chain-of-thought or input-output examples) to improve the generated code. Despite this, the impact of different prompt techniques -- and their combinations -- on code generation remains underexplored. In this study, we introduce CodePromptEval, a dataset of 7072 prompts designed to evaluate five prompt techniques (few-shot, persona, chain-of-thought, function signature, list of packages) and their effect on the correctness, similarity, and quality of complete functions generated by three LLMs (GPT-4o, Llama3, and Mistral). Our findings show that while certain prompt techniques significantly influence the generated code, combining multiple techniques does not necessarily improve the outcome. Additionally, we observed a trade-off between correctness and quality when using prompt techniques. Our dataset and replication package enable future research on improving LLM-generated code and evaluating new prompt techniques.
Analysing the Behaviour of Tree-Based Neural Networks in Regression Tasks
Jun 17, 2024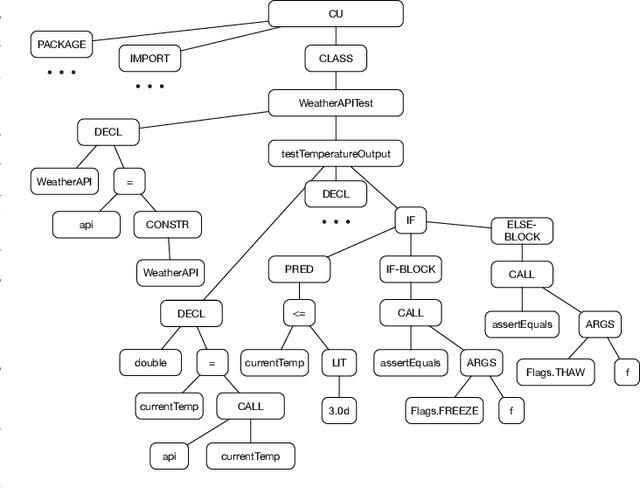



The landscape of deep learning has vastly expanded the frontiers of source code analysis, particularly through the utilization of structural representations such as Abstract Syntax Trees (ASTs). While these methodologies have demonstrated effectiveness in classification tasks, their efficacy in regression applications, such as execution time prediction from source code, remains underexplored. This paper endeavours to decode the behaviour of tree-based neural network models in the context of such regression challenges. We extend the application of established models--tree-based Convolutional Neural Networks (CNNs), Code2Vec, and Transformer-based methods--to predict the execution time of source code by parsing it to an AST. Our comparative analysis reveals that while these models are benchmarks in code representation, they exhibit limitations when tasked with regression. To address these deficiencies, we propose a novel dual-transformer approach that operates on both source code tokens and AST representations, employing cross-attention mechanisms to enhance interpretability between the two domains. Furthermore, we explore the adaptation of Graph Neural Networks (GNNs) to this tree-based problem, theorizing the inherent compatibility due to the graphical nature of ASTs. Empirical evaluations on real-world datasets showcase that our dual-transformer model outperforms all other tree-based neural networks and the GNN-based models. Moreover, our proposed dual transformer demonstrates remarkable adaptability and robust performance across diverse datasets.
From Human-to-Human to Human-to-Bot Conversations in Software Engineering
May 21, 2024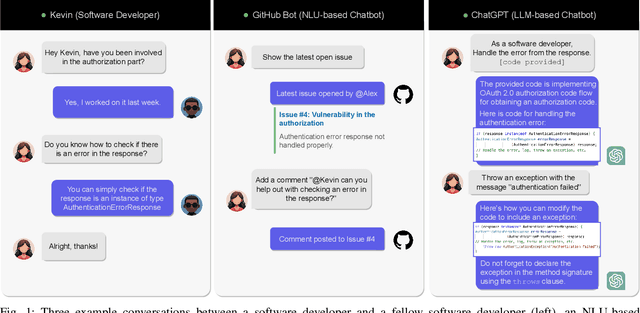
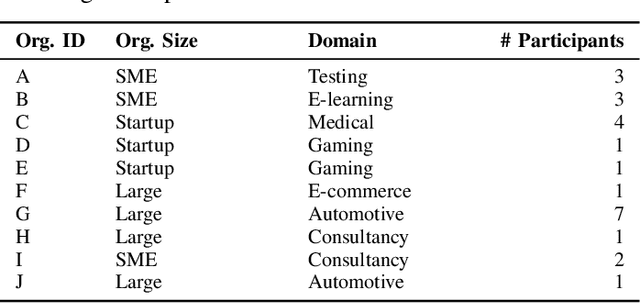
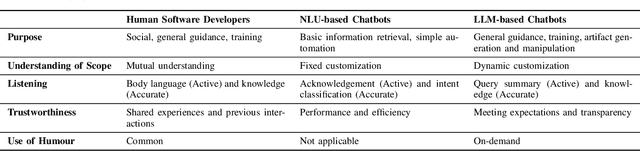
Software developers use natural language to interact not only with other humans, but increasingly also with chatbots. These interactions have different properties and flow differently based on what goal the developer wants to achieve and who they interact with. In this paper, we aim to understand the dynamics of conversations that occur during modern software development after the integration of AI and chatbots, enabling a deeper recognition of the advantages and disadvantages of including chatbot interactions in addition to human conversations in collaborative work. We compile existing conversation attributes with humans and NLU-based chatbots and adapt them to the context of software development. Then, we extend the comparison to include LLM-powered chatbots based on an observational study. We present similarities and differences between human-to-human and human-to-bot conversations, also distinguishing between NLU- and LLM-based chatbots. Furthermore, we discuss how understanding the differences among the conversation styles guides the developer on how to shape their expectations from a conversation and consequently support the communication within a software team. We conclude that the recent conversation styles that we observe with LLM-chatbots can not replace conversations with humans due to certain attributes regarding social aspects despite their ability to support productivity and decrease the developers' mental load.
Beyond Code Generation: An Observational Study of ChatGPT Usage in Software Engineering Practice
Apr 23, 2024



Large Language Models (LLMs) are frequently discussed in academia and the general public as support tools for virtually any use case that relies on the production of text, including software engineering. Currently there is much debate, but little empirical evidence, regarding the practical usefulness of LLM-based tools such as ChatGPT for engineers in industry. We conduct an observational study of 24 professional software engineers who have been using ChatGPT over a period of one week in their jobs, and qualitatively analyse their dialogues with the chatbot as well as their overall experience (as captured by an exit survey). We find that, rather than expecting ChatGPT to generate ready-to-use software artifacts (e.g., code), practitioners more often use ChatGPT to receive guidance on how to solve their tasks or learn about a topic in more abstract terms. We also propose a theoretical framework for how (i) purpose of the interaction, (ii) internal factors (e.g., the user's personality), and (iii) external factors (e.g., company policy) together shape the experience (in terms of perceived usefulness and trust). We envision that our framework can be used by future research to further the academic discussion on LLM usage by software engineering practitioners, and to serve as a reference point for the design of future empirical LLM research in this domain.
A Unified Active Learning Framework for Annotating Graph Data with Application to Software Source Code Performance Prediction
Apr 06, 2023



Most machine learning and data analytics applications, including performance engineering in software systems, require a large number of annotations and labelled data, which might not be available in advance. Acquiring annotations often requires significant time, effort, and computational resources, making it challenging. We develop a unified active learning framework, specializing in software performance prediction, to address this task. We begin by parsing the source code to an Abstract Syntax Tree (AST) and augmenting it with data and control flow edges. Then, we convert the tree representation of the source code to a Flow Augmented-AST graph (FA-AST) representation. Based on the graph representation, we construct various graph embeddings (unsupervised and supervised) into a latent space. Given such an embedding, the framework becomes task agnostic since active learning can be performed using any regression method and query strategy suited for regression. Within this framework, we investigate the impact of using different levels of information for active and passive learning, e.g., partially available labels and unlabeled test data. Our approach aims to improve the investment in AI models for different software performance predictions (execution time) based on the structure of the source code. Our real-world experiments reveal that respectable performance can be achieved by querying labels for only a small subset of all the data.
Machine Learning Containers are Bloated and Vulnerable
Dec 16, 2022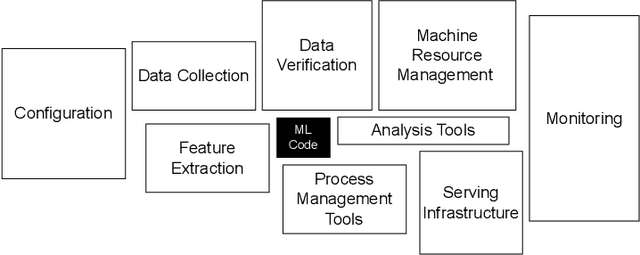


Today's software is bloated leading to significant resource wastage. This bloat is prevalent across the entire software stack, from the operating system, all the way to software backends, frontends, and web-pages. In this paper, we study how prevalent bloat is in machine learning containers. We develop MMLB, a framework to analyze bloat in machine learning containers, measuring the amount of bloat that exists on the container and package levels. Our tool quantifies the sources of bloat and removes them. We integrate our tool with vulnerability analysis tools to measure how bloat affects container vulnerabilities. We experimentally study 15 machine learning containers from the official Tensorflow, Pytorch, and NVIDIA container registries under different tasks, (i.e., training, tuning, and serving). Our findings show that machine learning containers contain bloat encompassing up to 80\% of the container size. We find that debloating machine learning containers speeds provisioning times by up to $3.7\times$ and removes up to 98\% of all vulnerabilities detected by vulnerability analysis tools such as Grype. Finally, we relate our results to the larger discussion about technical debt in machine learning systems.
TEP-GNN: Accurate Execution Time Prediction of Functional Tests using Graph Neural Networks
Aug 25, 2022
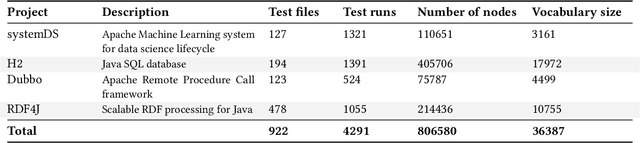
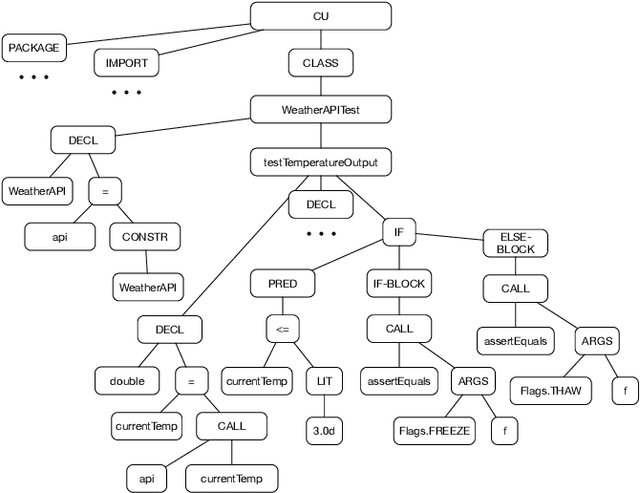
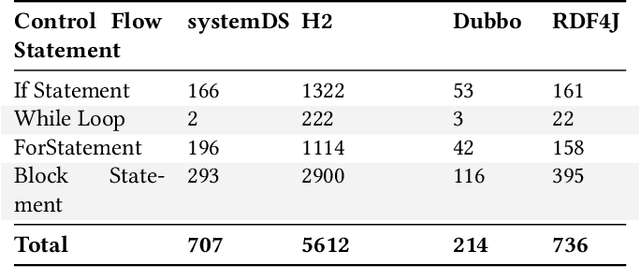
Predicting the performance of production code prior to actually executing or benchmarking it is known to be highly challenging. In this paper, we propose a predictive model, dubbed TEP-GNN, which demonstrates that high-accuracy performance prediction is possible for the special case of predicting unit test execution times. TEP-GNN uses FA-ASTs, or flow-augmented ASTs, as a graph-based code representation approach, and predicts test execution times using a powerful graph neural network (GNN) deep learning model. We evaluate TEP-GNN using four real-life Java open source programs, based on 922 test files mined from the projects' public repositories. We find that our approach achieves a high Pearson correlation of 0.789, considerable outperforming a baseline deep learning model. However, we also find that more work is needed for trained models to generalize to unseen projects. Our work demonstrates that FA-ASTs and GNNs are a feasible approach for predicting absolute performance values, and serves as an important intermediary step towards being able to predict the performance of arbitrary code prior to execution.