 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Prompt Programming on Function-Level Code Generation
Dec 29, 2024Large Language Models (LLMs) are increasingly used by software engineers for code generation. However, limitations of LLMs such as irrelevant or incorrect code have highlighted the need for prompt programming (or prompt engineering) where engineers apply specific prompt techniques (e.g., chain-of-thought or input-output examples) to improve the generated code. Despite this, the impact of different prompt techniques -- and their combinations -- on code generation remains underexplored. In this study, we introduce CodePromptEval, a dataset of 7072 prompts designed to evaluate five prompt techniques (few-shot, persona, chain-of-thought, function signature, list of packages) and their effect on the correctness, similarity, and quality of complete functions generated by three LLMs (GPT-4o, Llama3, and Mistral). Our findings show that while certain prompt techniques significantly influence the generated code, combining multiple techniques does not necessarily improve the outcome. Additionally, we observed a trade-off between correctness and quality when using prompt techniques. Our dataset and replication package enable future research on improving LLM-generated code and evaluating new prompt techniques.
Beyond Code Generation: An Observational Study of ChatGPT Usage in Software Engineering Practice
Apr 23, 2024



Large Language Models (LLMs) are frequently discussed in academia and the general public as support tools for virtually any use case that relies on the production of text, including software engineering. Currently there is much debate, but little empirical evidence, regarding the practical usefulness of LLM-based tools such as ChatGPT for engineers in industry. We conduct an observational study of 24 professional software engineers who have been using ChatGPT over a period of one week in their jobs, and qualitatively analyse their dialogues with the chatbot as well as their overall experience (as captured by an exit survey). We find that, rather than expecting ChatGPT to generate ready-to-use software artifacts (e.g., code), practitioners more often use ChatGPT to receive guidance on how to solve their tasks or learn about a topic in more abstract terms. We also propose a theoretical framework for how (i) purpose of the interaction, (ii) internal factors (e.g., the user's personality), and (iii) external factors (e.g., company policy) together shape the experience (in terms of perceived usefulness and trust). We envision that our framework can be used by future research to further the academic discussion on LLM usage by software engineering practitioners, and to serve as a reference point for the design of future empirical LLM research in this domain.
TEP-GNN: Accurate Execution Time Prediction of Functional Tests using Graph Neural Networks
Aug 25, 2022
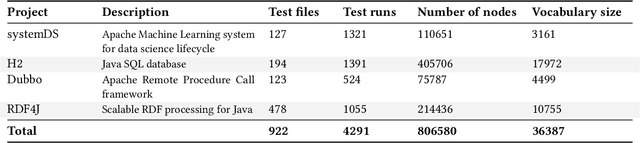
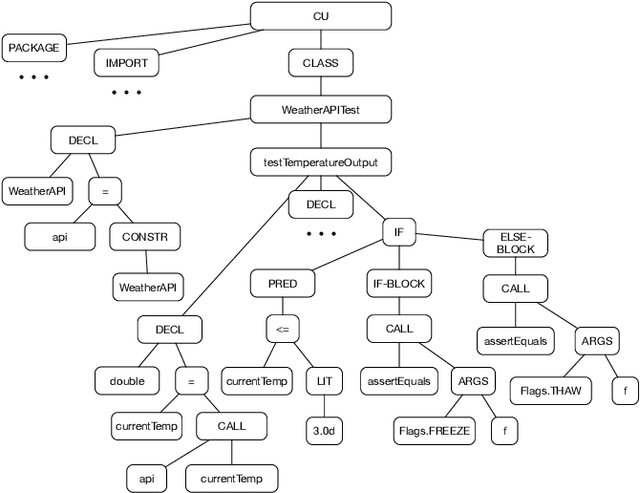
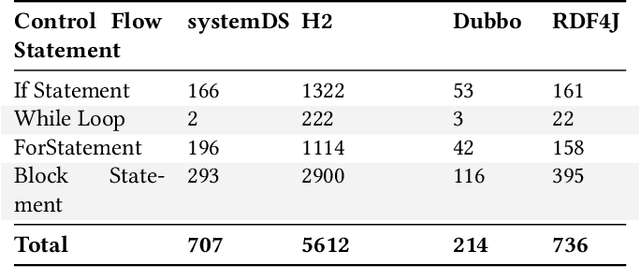
Predicting the performance of production code prior to actually executing or benchmarking it is known to be highly challenging. In this paper, we propose a predictive model, dubbed TEP-GNN, which demonstrates that high-accuracy performance prediction is possible for the special case of predicting unit test execution times. TEP-GNN uses FA-ASTs, or flow-augmented ASTs, as a graph-based code representation approach, and predicts test execution times using a powerful graph neural network (GNN) deep learning model. We evaluate TEP-GNN using four real-life Java open source programs, based on 922 test files mined from the projects' public repositories. We find that our approach achieves a high Pearson correlation of 0.789, considerable outperforming a baseline deep learning model. However, we also find that more work is needed for trained models to generalize to unseen projects. Our work demonstrates that FA-ASTs and GNNs are a feasible approach for predicting absolute performance values, and serves as an important intermediary step towards being able to predict the performance of arbitrary code prior to execution.