 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Containers are Bloated and Vulnerable
Dec 16, 2022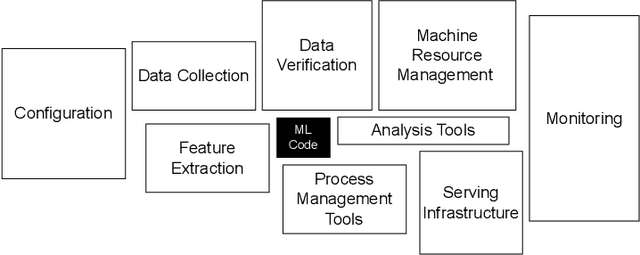

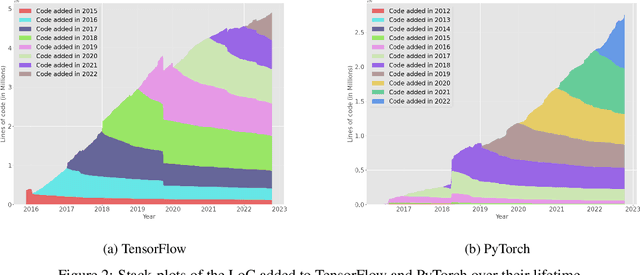

Today's software is bloated leading to significant resource wastage. This bloat is prevalent across the entire software stack, from the operating system, all the way to software backends, frontends, and web-pages. In this paper, we study how prevalent bloat is in machine learning containers. We develop MMLB, a framework to analyze bloat in machine learning containers, measuring the amount of bloat that exists on the container and package levels. Our tool quantifies the sources of bloat and removes them. We integrate our tool with vulnerability analysis tools to measure how bloat affects container vulnerabilities. We experimentally study 15 machine learning containers from the official Tensorflow, Pytorch, and NVIDIA container registries under different tasks, (i.e., training, tuning, and serving). Our findings show that machine learning containers contain bloat encompassing up to 80\% of the container size. We find that debloating machine learning containers speeds provisioning times by up to $3.7\times$ and removes up to 98\% of all vulnerabilities detected by vulnerability analysis tools such as Grype. Finally, we relate our results to the larger discussion about technical debt in machine learning systems.
Extended vehicle energy dataset (eVED): an enhanced large-scale dataset for deep learning on vehicle trip energy consumption
Mar 16, 2022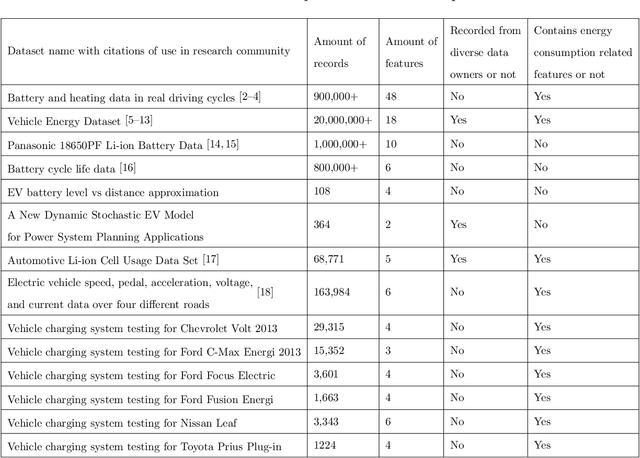
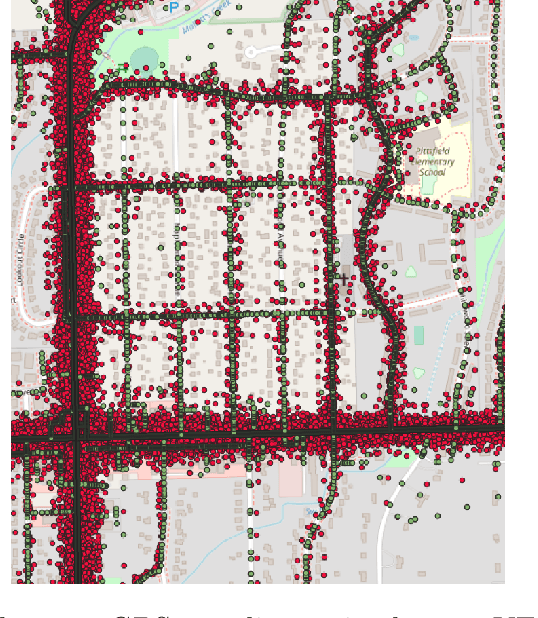

This work presents an extended version of the Vehicle Energy Dataset (VED), which is a openly released large-scale dataset for vehicle energy consumption analysis. Compared with its original version, the extended VED (eVED) dataset is enhanced with accurate vehicle trip GPS coordinates, serving as a basis to associate the VED trip records with external information, e.g., road speed limit and intersections, from accessible map services to accumulate attributes that is essential in analyzing vehicle energy consumption. In particularly, we calibrate all the GPS trace records in the original VED data, upon which we associated the VED data with attributes extracted from the Geographic Information System (QGIS), the Overpass API, the Open Street Map API, and Google Maps API. The associated attributes include 12,609,170 records of road elevation, 12,203,044 of speed limit, 12,281,719 of speed limit with direction (in case the road is bi-directional), 584,551 of intersections, 429,638 of bus stop, 312,196 of crossings, 195,856 of traffic signals, 29,397 of stop signs, 5,848 of turning loops, 4,053 of railway crossings (level crossing), 3,554 of turning circles, and 2,938 of motorway junctions. With the accurate GPS coordinates and enriched features of the vehicle trip record, the obtained eVED dataset can provide a precise and abundant medium to feed a learning engine, especially a deep learning engine that is more demanding on data sufficiency and richness. Moreover, our software work for data calibration and enrichment can be reused to generate further vehicle trip datasets for specific user cases, contributing to deep insights into vehicle behaviors and traffic dynamics analyses. We anticipate that the eVED dataset and our data enrichment software can serve the academic and industrial automotive section as apparatus in developing future technologies.