 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParsBERT: Transformer-based Model for Persian Language Understanding
May 31, 2020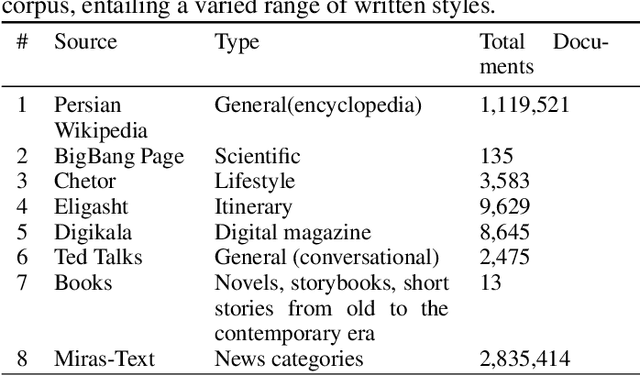
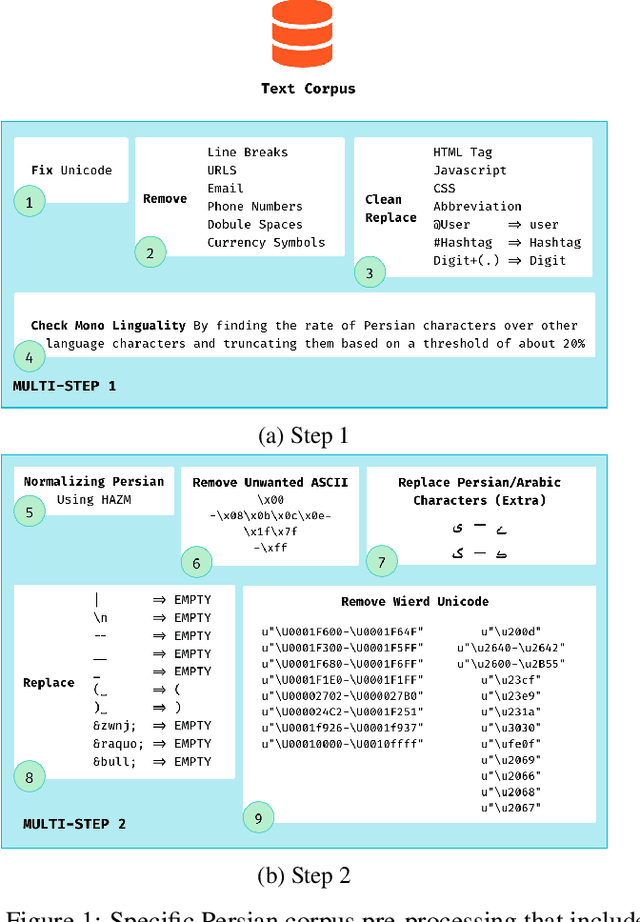
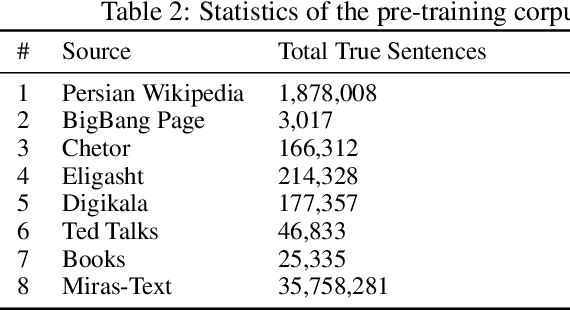
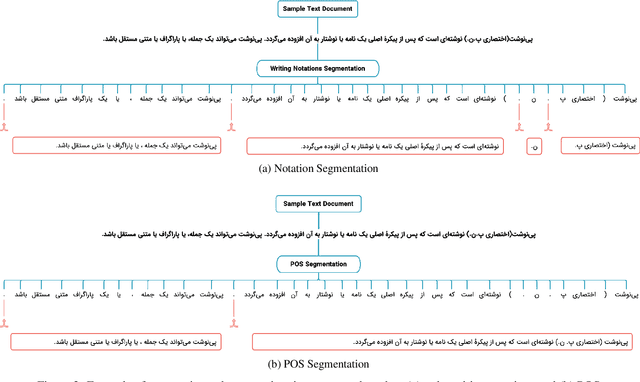
The surge of pre-trained language models has begun a new era in the field of Natural Language Processing (NLP) by allowing us to build powerful language models. Among these models, Transformer-based models such as BERT have become increasingly popular due to their state-of-the-art performance. However, these models are usually focused on English, leaving other languages to multilingual models with limited resources. This paper proposes a monolingual BERT for the Persian language (ParsBERT), which shows its state-of-the-art performance compared to other architectures and multilingual models. Also, since the amount of data available for NLP tasks in Persian is very restricted, a massive dataset for different NLP tasks as well as pre-training the model is composed. ParsBERT obtains higher scores in all datasets, including existing ones as well as composed ones and improves the state-of-the-art performance by outperforming both multilingual BERT and other prior works in Sentiment Analysis, Text Classification and Named Entity Recognition tasks.
Short-Term Traffic Flow Prediction Using Variational LSTM Networks
Feb 18, 2020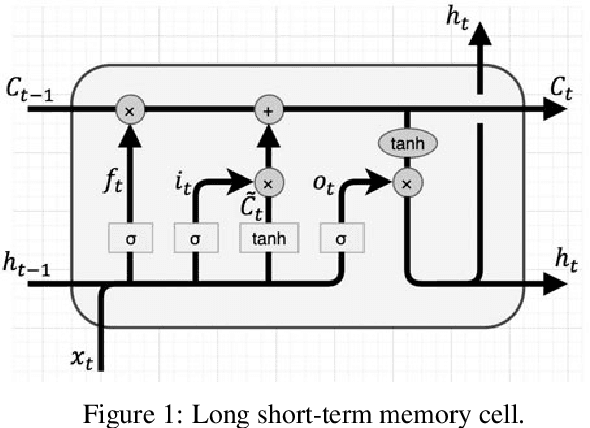

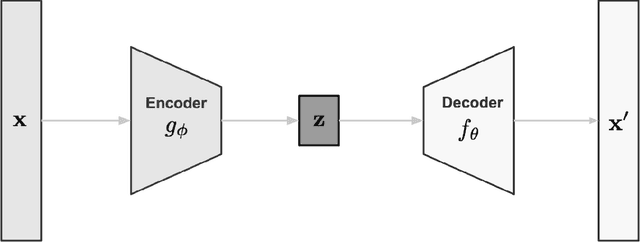

Traffic flow characteristics are one of the most critical decision-making and traffic policing factors in a region. Awareness of the predicted status of the traffic flow has prime importance in traffic management and traffic information divisions. The purpose of this research is to suggest a forecasting model for traffic flow by using deep learning techniques based on historical data in the Intelligent Transportation Systems area. The historical data collected from the Caltrans Performance Measurement Systems (PeMS) for six months in 2019. The proposed prediction model is a Variational Long Short-Term Memory Encoder in brief VLSTM-E try to estimate the flow accurately in contrast to other conventional methods. VLSTM-E can provide more reliable short-term traffic flow by considering the distribution and missing values.