 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToPro: Token-Level Prompt Decomposition for Cross-Lingual Sequence Labeling Tasks
Paper and Code

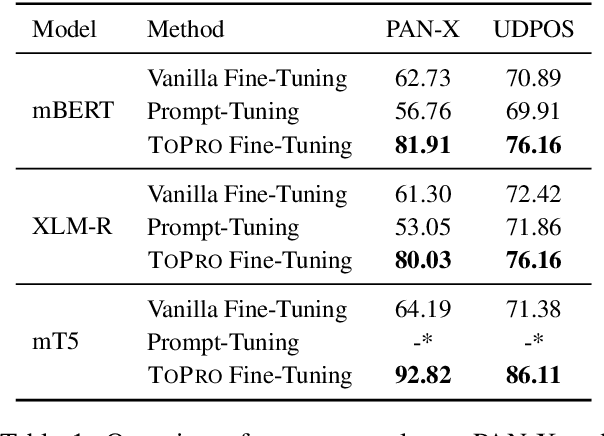
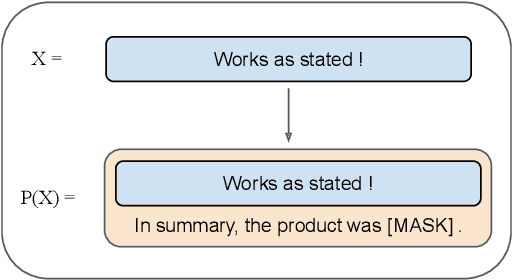
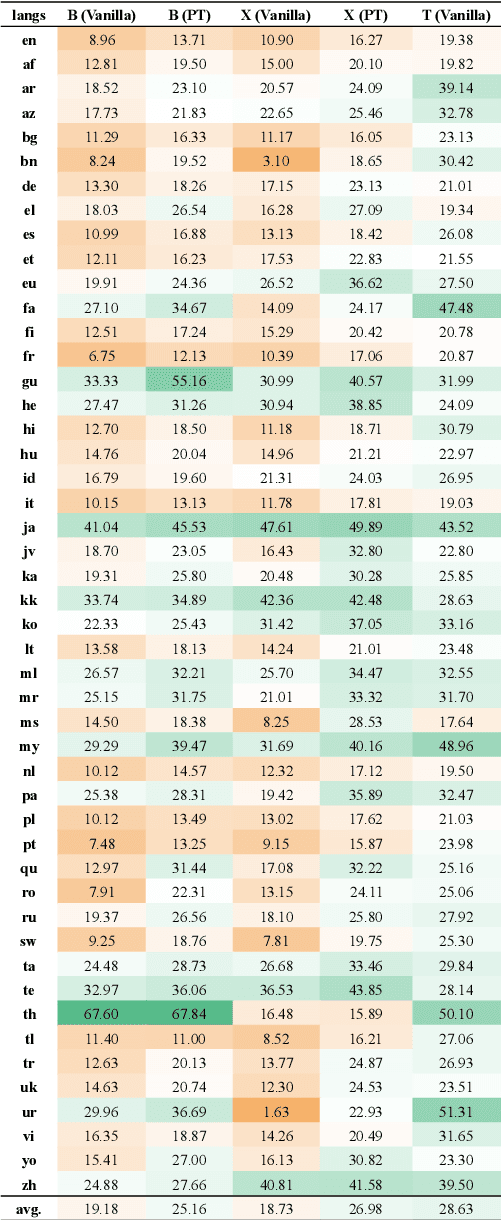
Prompt-based methods have been successfully applied to multilingual pretrained language models for zero-shot cross-lingual understanding. However, most previous studies primarily focused on sentence-level classification tasks, and only a few considered token-level labeling tasks such as Named Entity Recognition (NER) and Part-of-Speech (POS) tagging. In this paper, we propose Token-Level Prompt Decomposition (ToPro), which facilitates the prompt-based method for token-level sequence labeling tasks. The ToPro method decomposes an input sentence into single tokens and applies one prompt template to each token. Our experiments on multilingual NER and POS tagging datasets demonstrate that ToPro-based fine-tuning outperforms Vanilla fine-tuning and Prompt-Tuning in zero-shot cross-lingual transfer, especially for languages that are typologically different from the source language English. Our method also attains state-of-the-art performance when employed with the mT5 model. Besides, our exploratory study in multilingual large language models shows that ToPro performs much better than the current in-context learning method. Overall, the performance improvements show that ToPro could potentially serve as a novel and simple benchmarking method for sequence labeling tasks.