 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Augmentation Training Makes Action Recognition Models More Robust to Realistic Video Distribution Shifts
Jan 21, 2024Despite recent advances in video action recognition achieving strong performance on existing benchmarks, these models often lack robustness when faced with natural distribution shifts between training and test data. We propose two novel evaluation methods to assess model resilience to such distribution disparity. One method uses two different datasets collected from different sources and uses one for training and validation, and the other for testing. More precisely, we created dataset splits of HMDB-51 or UCF-101 for training, and Kinetics-400 for testing, using the subset of the classes that are overlapping in both train and test datasets. The other proposed method extracts the feature mean of each class from the target evaluation dataset's training data (i.e. class prototype) and estimates test video prediction as a cosine similarity score between each sample to the class prototypes of each target class. This procedure does not alter model weights using the target dataset and it does not require aligning overlapping classes of two different datasets, thus is a very efficient method to test the model robustness to distribution shifts without prior knowledge of the target distribution. We address the robustness problem by adversarial augmentation training - generating augmented views of videos that are "hard" for the classification model by applying gradient ascent on the augmentation parameters - as well as "curriculum" scheduling the strength of the video augmentations. We experimentally demonstrate the superior performance of the proposed adversarial augmentation approach over baselines across three state-of-the-art action recognition models - TSM, Video Swin Transformer, and Uniformer. The presented work provides critical insight into model robustness to distribution shifts and presents effective techniques to enhance video action recognition performance in a real-world deployment.
An Action Is Worth Multiple Words: Handling Ambiguity in Action Recognition
Oct 10, 2022



Precisely naming the action depicted in a video can be a challenging and oftentimes ambiguous task. In contrast to object instances represented as nouns (e.g. dog, cat, chair, etc.), in the case of actions, human annotators typically lack a consensus as to what constitutes a specific action (e.g. jogging versus running). In practice, a given video can contain multiple valid positive annotations for the same action. As a result, video datasets often contain significant levels of label noise and overlap between the atomic action classes. In this work, we address the challenge of training multi-label action recognition models from only single positive training labels. We propose two approaches that are based on generating pseudo training examples sampled from similar instances within the train set. Unlike other approaches that use model-derived pseudo-labels, our pseudo-labels come from human annotations and are selected based on feature similarity. To validate our approaches, we create a new evaluation benchmark by manually annotating a subset of EPIC-Kitchens-100's validation set with multiple verb labels. We present results on this new test set along with additional results on a new version of HMDB-51, called Confusing-HMDB-102, where we outperform existing methods in both cases. Data and code are available at https://github.com/kiyoon/verb_ambiguity
Capturing Temporal Information in a Single Frame: Channel Sampling Strategies for Action Recognition
Jan 25, 2022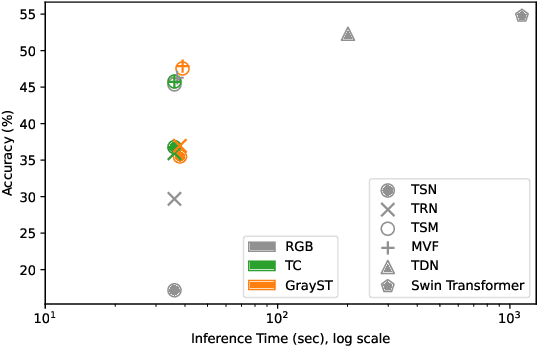
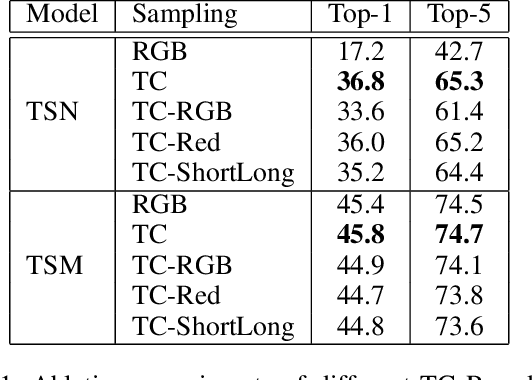
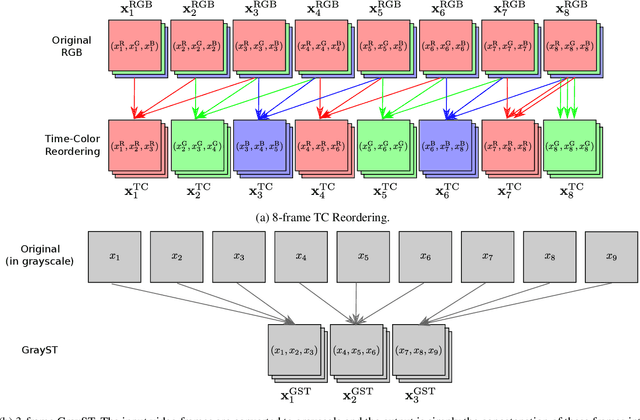

We address the problem of capturing temporal information for video classification in 2D networks, without increasing computational cost. Existing approaches focus on modifying the architecture of 2D networks (e.g. by including filters in the temporal dimension to turn them into 3D networks, or using optical flow, etc.), which increases computation cost. Instead, we propose a novel sampling strategy, where we re-order the channels of the input video, to capture short-term frame-to-frame changes. We observe that without bells and whistles, the proposed sampling strategy improves performance on multiple architectures (e.g. TSN, TRN, and TSM) and datasets (CATER, Something-Something-V1 and V2), up to 24% over the baseline of using the standard video input. In addition, our sampling strategies do not require training from scratch and do not increase the computational cost of training and testing. Given the generality of the results and the flexibility of the approach, we hope this can be widely useful to the video understanding community. Code is available at https://github.com/kiyoon/PyVideoAI.
A New Split for Evaluating True Zero-Shot Action Recognition
Jul 27, 2021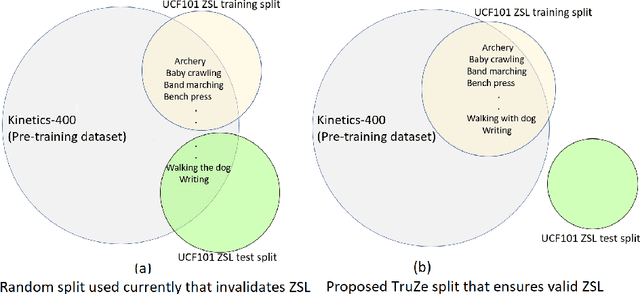
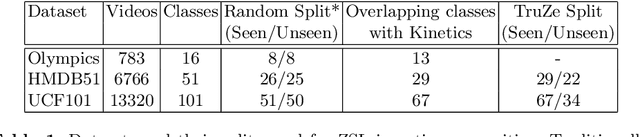


Zero-shot action recognition is the task of classifying action categories that are not available in the training set. In this setting, the standard evaluation protocol is to use existing action recognition datasets (e.g. UCF101) and randomly split the classes into seen and unseen. However, most recent work builds on representations pre-trained on the Kinetics dataset, where classes largely overlap with classes in the zero-shot evaluation datasets. As a result, classes which are supposed to be unseen, are present during supervised pre-training, invalidating the condition of the zero-shot setting. A similar concern was previously noted several years ago for image based zero-shot recognition, but has not been considered by the zero-shot action recognition community. In this paper, we propose a new split for true zero-shot action recognition with no overlap between unseen test classes and training or pre-training classes. We benchmark several recent approaches on the proposed True Zero-Shot (TruZe) Split for UCF101 and HMDB51, with zero-shot and generalized zero-shot evaluation. In our extensive analysis we find that our TruZe splits are significantly harder than comparable random splits as nothing is leaking from pre-training, i.e. unseen performance is consistently lower, up to 9.4% for zero-shot action recognition. In an additional evaluation we also find that similar issues exist in the splits used in few-shot action recognition, here we see differences of up to 14.1%. We publish our splits and hope that our benchmark analysis will change how the field is evaluating zero- and few-shot action recognition moving forward.
Extreme Low Resolution Activity Recognition with Multi-Siamese Embedding Learning
Feb 04, 2018



This paper presents an approach for recognizing human activities from extreme low resolution (e.g., 16x12) videos. Extreme low resolution recognition is not only necessary for analyzing actions at a distance but also is crucial for enabling privacy-preserving recognition of human activities. We design a new two-stream multi-Siamese convolutional neural network. The idea is to explicitly capture the inherent property of low resolution (LR) videos that two images originated from the exact same scene often have totally different pixel values depending on their LR transformations. Our approach learns the shared embedding space that maps LR videos with the same content to the same location regardless of their transformations. We experimentally confirm that our approach of jointly learning such transform robust LR video representation and the classifier outperforms the previous state-of-the-art low resolution recognition approaches on two public standard datasets by a meaningful margin.